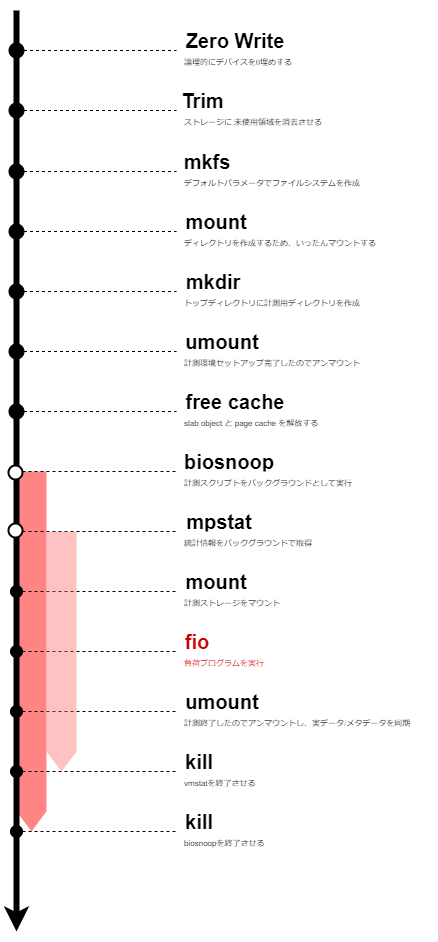
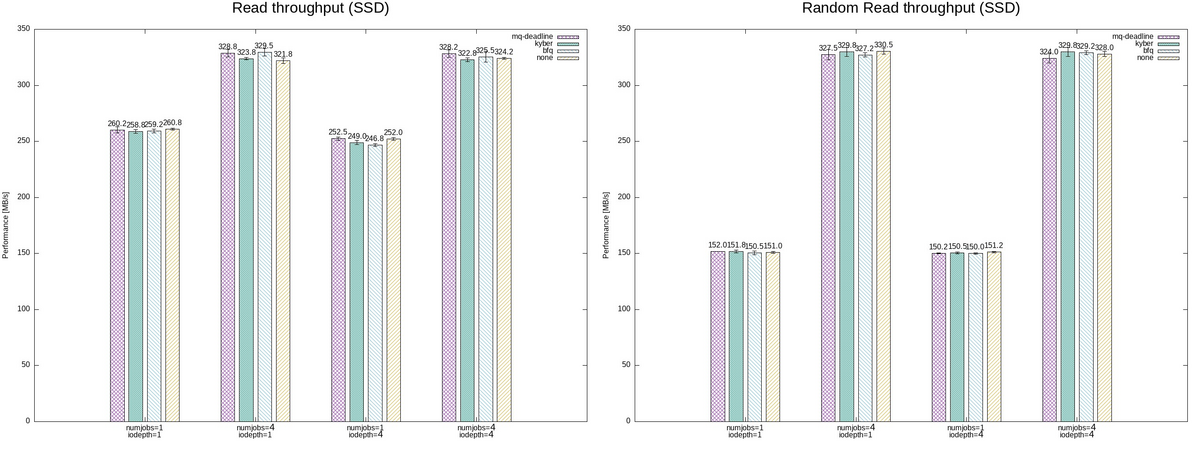
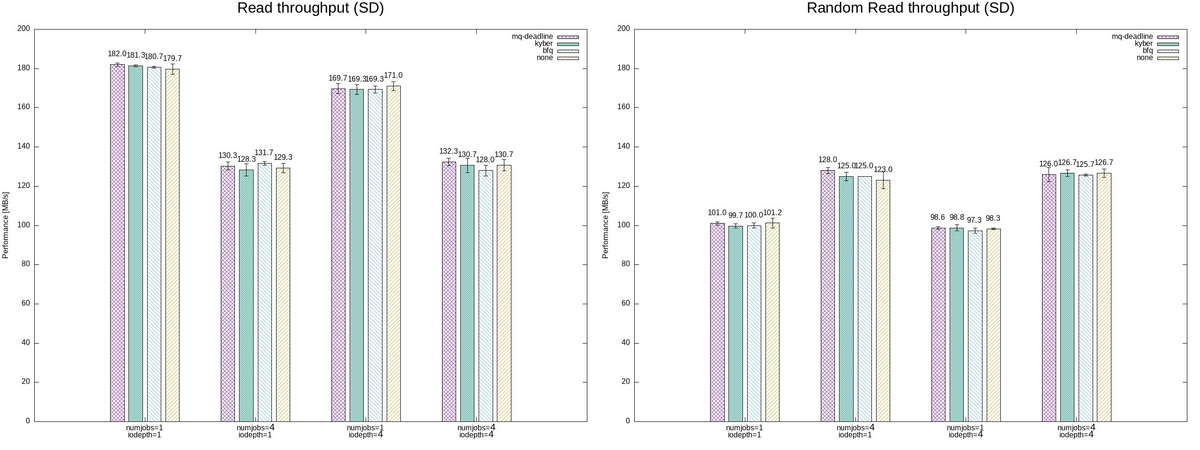
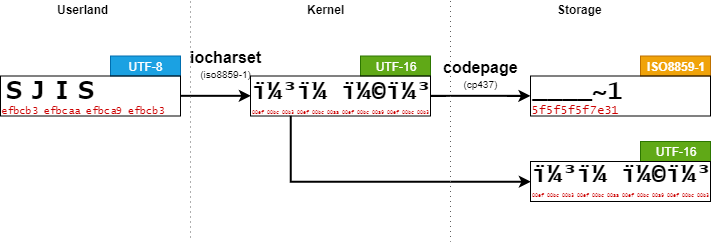
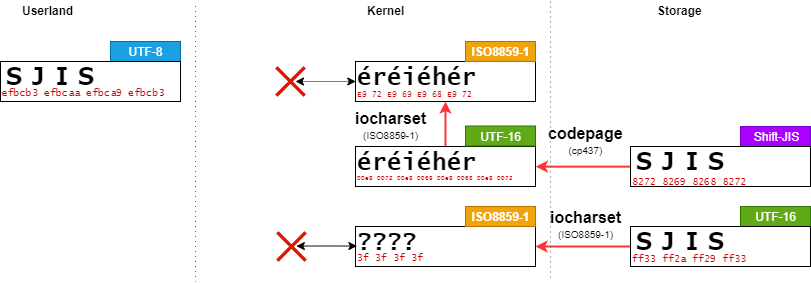
biosnoop は、IO要求発行(blk_mq_start_request)と IO完了(blk_account_io_done) における BIO のステータスを確認することができる。
このスクリプトを実行することで下記のような結果を得ることができる。
TIME(s) COMM PID DISK T SECTOR BYTES QUE(ms) LAT(ms)
0.000000 mount 4349 sda R 2050 1024 0.06 0.46
0.000396 mount 4349 sda R 2048 4096 0.05 0.19
0.000713 mount 4349 sda R 2056 4096 0.05 0.18
0.000826 mount 4349 sda R 2064 4096 0.05 0.18
0.000968 mount 4349 sda R 2072 4096 0.05 0.16
0.001165 mount 4349 sda R 2080 4096 0.09 0.17
// 209:staticintblk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx)
{
int ret;
do {
ret = __blk_mq_do_dispatch_sched(hctx);
} while (ret == 1);
return ret;
}
// 118:staticint__blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx)
{
struct request_queue *q = hctx->queue;
struct elevator_queue *e = q->elevator;
bool multi_hctxs = false, run_queue = false;
bool dispatched = false, busy = false;
unsignedint max_dispatch;
LIST_HEAD(rq_list);
int count = 0;
if (hctx->dispatch_busy)
max_dispatch = 1;
else
max_dispatch = hctx->queue->nr_requests;
do {
struct request *rq;
int budget_token;
if (e->type->ops.has_work && !e->type->ops.has_work(hctx))
break;
if (!list_empty_careful(&hctx->dispatch)) {
busy = true;
break;
}
budget_token = blk_mq_get_dispatch_budget(q);
if (budget_token < 0)
break;
rq = e->type->ops.dispatch_request(hctx);
if (!rq) {
blk_mq_put_dispatch_budget(q, budget_token);
/* * We're releasing without dispatching. Holding the * budget could have blocked any "hctx"s with the * same queue and if we didn't dispatch then there's * no guarantee anyone will kick the queue. Kick it * ourselves. */
run_queue = true;
break;
}
blk_mq_set_rq_budget_token(rq, budget_token);
/* * Now this rq owns the budget which has to be released * if this rq won't be queued to driver via .queue_rq() * in blk_mq_dispatch_rq_list(). */list_add_tail(&rq->queuelist, &rq_list);
count++;
if (rq->mq_hctx != hctx)
multi_hctxs = true;
/* * If we cannot get tag for the request, stop dequeueing * requests from the IO scheduler. We are unlikely to be able * to submit them anyway and it creates false impression for * scheduling heuristics that the device can take more IO. */if (!blk_mq_get_driver_tag(rq))
break;
} while (count < max_dispatch);
if (!count) {
if (run_queue)
blk_mq_delay_run_hw_queues(q, BLK_MQ_BUDGET_DELAY);
} elseif (multi_hctxs) {
/* * Requests from different hctx may be dequeued from some * schedulers, such as bfq and deadline. * * Sort the requests in the list according to their hctx, * dispatch batching requests from same hctx at a time. */list_sort(NULL, &rq_list, sched_rq_cmp);
do {
dispatched |= blk_mq_dispatch_hctx_list(&rq_list);
} while (!list_empty(&rq_list));
} else {
dispatched = blk_mq_dispatch_rq_list(hctx, &rq_list, count);
}
if (busy)
return -EAGAIN;
return !!dispatched;
}
// 133:do {
struct request *rq;
int budget_token;
if (e->type->ops.has_work && !e->type->ops.has_work(hctx))
break;
if (!list_empty_careful(&hctx->dispatch)) {
busy = true;
break;
}
budget_token = blk_mq_get_dispatch_budget(q);
if (budget_token < 0)
break;
rq = e->type->ops.dispatch_request(hctx);
if (!rq) {
blk_mq_put_dispatch_budget(q, budget_token);
/* * We're releasing without dispatching. Holding the * budget could have blocked any "hctx"s with the * same queue and if we didn't dispatch then there's * no guarantee anyone will kick the queue. Kick it * ourselves. */
run_queue = true;
break;
}
blk_mq_set_rq_budget_token(rq, budget_token);
/* * Now this rq owns the budget which has to be released * if this rq won't be queued to driver via .queue_rq() * in blk_mq_dispatch_rq_list(). */list_add_tail(&rq->queuelist, &rq_list);
count++;
if (rq->mq_hctx != hctx)
multi_hctxs = true;
/* * If we cannot get tag for the request, stop dequeueing * requests from the IO scheduler. We are unlikely to be able * to submit them anyway and it creates false impression for * scheduling heuristics that the device can take more IO. */if (!blk_mq_get_driver_tag(rq))
break;
} while (count < max_dispatch);
// 185:if (!count) {
if (run_queue)
blk_mq_delay_run_hw_queues(q, BLK_MQ_BUDGET_DELAY);
} elseif (multi_hctxs) {
/* * Requests from different hctx may be dequeued from some * schedulers, such as bfq and deadline. * * Sort the requests in the list according to their hctx, * dispatch batching requests from same hctx at a time. */list_sort(NULL, &rq_list, sched_rq_cmp);
do {
dispatched |= blk_mq_dispatch_hctx_list(&rq_list);
} while (!list_empty(&rq_list));
} else {
dispatched = blk_mq_dispatch_rq_list(hctx, &rq_list, count);
}
if (busy)
return -EAGAIN;
return !!dispatched;
}
// 1319:boolblk_mq_dispatch_rq_list(struct blk_mq_hw_ctx *hctx, struct list_head *list,
unsignedint nr_budgets)
{
enum prep_dispatch prep;
struct request_queue *q = hctx->queue;
struct request *rq, *nxt;
int errors, queued;
blk_status_t ret = BLK_STS_OK;
LIST_HEAD(zone_list);
bool needs_resource = false;
if (list_empty(list))
returnfalse;
/* * Now process all the entries, sending them to the driver. */
errors = queued = 0;
do {
struct blk_mq_queue_data bd;
rq = list_first_entry(list, struct request, queuelist);
WARN_ON_ONCE(hctx != rq->mq_hctx);
prep = blk_mq_prep_dispatch_rq(rq, !nr_budgets);
if (prep != PREP_DISPATCH_OK)
break;
list_del_init(&rq->queuelist);
bd.rq = rq;
/* * Flag last if we have no more requests, or if we have more * but can't assign a driver tag to it. */if (list_empty(list))
bd.last = true;
else {
nxt = list_first_entry(list, struct request, queuelist);
bd.last = !blk_mq_get_driver_tag(nxt);
}
/* * once the request is queued to lld, no need to cover the * budget any more */if (nr_budgets)
nr_budgets--;
ret = q->mq_ops->queue_rq(hctx, &bd);
switch (ret) {
case BLK_STS_OK:
queued++;
break;
case BLK_STS_RESOURCE:
needs_resource = true;
fallthrough;
case BLK_STS_DEV_RESOURCE:
blk_mq_handle_dev_resource(rq, list);
goto out;
case BLK_STS_ZONE_RESOURCE:
/* * Move the request to zone_list and keep going through * the dispatch list to find more requests the drive can * accept. */blk_mq_handle_zone_resource(rq, &zone_list);
needs_resource = true;
break;
default:
errors++;
blk_mq_end_request(rq, ret);
}
} while (!list_empty(list));
out:
if (!list_empty(&zone_list))
list_splice_tail_init(&zone_list, list);
hctx->dispatched[queued_to_index(queued)]++;
/* If we didn't flush the entire list, we could have told the driver * there was more coming, but that turned out to be a lie. */if ((!list_empty(list) || errors) && q->mq_ops->commit_rqs && queued)
q->mq_ops->commit_rqs(hctx);
/* * Any items that need requeuing? Stuff them into hctx->dispatch, * that is where we will continue on next queue run. */if (!list_empty(list)) {
bool needs_restart;
/* For non-shared tags, the RESTART check will suffice */bool no_tag = prep == PREP_DISPATCH_NO_TAG &&
(hctx->flags & BLK_MQ_F_TAG_QUEUE_SHARED);
if (nr_budgets)
blk_mq_release_budgets(q, list);
spin_lock(&hctx->lock);
list_splice_tail_init(list, &hctx->dispatch);
spin_unlock(&hctx->lock);
/* * Order adding requests to hctx->dispatch and checking * SCHED_RESTART flag. The pair of this smp_mb() is the one * in blk_mq_sched_restart(). Avoid restart code path to * miss the new added requests to hctx->dispatch, meantime * SCHED_RESTART is observed here. */smp_mb();
/* * If SCHED_RESTART was set by the caller of this function and * it is no longer set that means that it was cleared by another * thread and hence that a queue rerun is needed. * * If 'no_tag' is set, that means that we failed getting * a driver tag with an I/O scheduler attached. If our dispatch * waitqueue is no longer active, ensure that we run the queue * AFTER adding our entries back to the list. * * If no I/O scheduler has been configured it is possible that * the hardware queue got stopped and restarted before requests * were pushed back onto the dispatch list. Rerun the queue to * avoid starvation. Notes: * - blk_mq_run_hw_queue() checks whether or not a queue has * been stopped before rerunning a queue. * - Some but not all block drivers stop a queue before * returning BLK_STS_RESOURCE. Two exceptions are scsi-mq * and dm-rq. * * If driver returns BLK_STS_RESOURCE and SCHED_RESTART * bit is set, run queue after a delay to avoid IO stalls * that could otherwise occur if the queue is idle. We'll do * similar if we couldn't get budget or couldn't lock a zone * and SCHED_RESTART is set. */
needs_restart = blk_mq_sched_needs_restart(hctx);
if (prep == PREP_DISPATCH_NO_BUDGET)
needs_resource = true;
if (!needs_restart ||
(no_tag && list_empty_careful(&hctx->dispatch_wait.entry)))
blk_mq_run_hw_queue(hctx, true);
elseif (needs_restart && needs_resource)
blk_mq_delay_run_hw_queue(hctx, BLK_MQ_RESOURCE_DELAY);
blk_mq_update_dispatch_busy(hctx, true);
returnfalse;
} elseblk_mq_update_dispatch_busy(hctx, false);
return (queued + errors) != 0;
}
// 1330:if (list_empty(list))
returnfalse;
/* * Now process all the entries, sending them to the driver. */
errors = queued = 0;
do {
struct blk_mq_queue_data bd;
rq = list_first_entry(list, struct request, queuelist);
WARN_ON_ONCE(hctx != rq->mq_hctx);
prep = blk_mq_prep_dispatch_rq(rq, !nr_budgets);
if (prep != PREP_DISPATCH_OK)
break;
list_del_init(&rq->queuelist);
bd.rq = rq;
/* * Flag last if we have no more requests, or if we have more * but can't assign a driver tag to it. */if (list_empty(list))
bd.last = true;
else {
nxt = list_first_entry(list, struct request, queuelist);
bd.last = !blk_mq_get_driver_tag(nxt);
}
/* * once the request is queued to lld, no need to cover the * budget any more */if (nr_budgets)
nr_budgets--;
// 1265:staticenum prep_dispatch blk_mq_prep_dispatch_rq(struct request *rq,
bool need_budget)
{
struct blk_mq_hw_ctx *hctx = rq->mq_hctx;
int budget_token = -1;
if (need_budget) {
budget_token = blk_mq_get_dispatch_budget(rq->q);
if (budget_token < 0) {
blk_mq_put_driver_tag(rq);
return PREP_DISPATCH_NO_BUDGET;
}
blk_mq_set_rq_budget_token(rq, budget_token);
}
if (!blk_mq_get_driver_tag(rq)) {
/* * The initial allocation attempt failed, so we need to * rerun the hardware queue when a tag is freed. The * waitqueue takes care of that. If the queue is run * before we add this entry back on the dispatch list, * we'll re-run it below. */if (!blk_mq_mark_tag_wait(hctx, rq)) {
/* * All budgets not got from this function will be put * together during handling partial dispatch */if (need_budget)
blk_mq_put_dispatch_budget(rq->q, budget_token);
return PREP_DISPATCH_NO_TAG;
}
}
return PREP_DISPATCH_OK;
}
// 1368:
ret = q->mq_ops->queue_rq(hctx, &bd);
switch (ret) {
case BLK_STS_OK:
queued++;
break;
case BLK_STS_RESOURCE:
needs_resource = true;
fallthrough;
case BLK_STS_DEV_RESOURCE:
blk_mq_handle_dev_resource(rq, list);
goto out;
case BLK_STS_ZONE_RESOURCE:
/* * Move the request to zone_list and keep going through * the dispatch list to find more requests the drive can * accept. */blk_mq_handle_zone_resource(rq, &zone_list);
needs_resource = true;
break;
default:
errors++;
blk_mq_end_request(rq, ret);
}
} while (!list_empty(list));
// 1393:out:
if (!list_empty(&zone_list))
list_splice_tail_init(&zone_list, list);
hctx->dispatched[queued_to_index(queued)]++;
/* If we didn't flush the entire list, we could have told the driver * there was more coming, but that turned out to be a lie. */if ((!list_empty(list) || errors) && q->mq_ops->commit_rqs && queued)
q->mq_ops->commit_rqs(hctx);
/* * Any items that need requeuing? Stuff them into hctx->dispatch, * that is where we will continue on next queue run. */if (!list_empty(list)) {
bool needs_restart;
/* For non-shared tags, the RESTART check will suffice */bool no_tag = prep == PREP_DISPATCH_NO_TAG &&
(hctx->flags & BLK_MQ_F_TAG_QUEUE_SHARED);
if (nr_budgets)
blk_mq_release_budgets(q, list);
spin_lock(&hctx->lock);
list_splice_tail_init(list, &hctx->dispatch);
spin_unlock(&hctx->lock);
/* * Order adding requests to hctx->dispatch and checking * SCHED_RESTART flag. The pair of this smp_mb() is the one * in blk_mq_sched_restart(). Avoid restart code path to * miss the new added requests to hctx->dispatch, meantime * SCHED_RESTART is observed here. */smp_mb();
/* * If SCHED_RESTART was set by the caller of this function and * it is no longer set that means that it was cleared by another * thread and hence that a queue rerun is needed. * * If 'no_tag' is set, that means that we failed getting * a driver tag with an I/O scheduler attached. If our dispatch * waitqueue is no longer active, ensure that we run the queue * AFTER adding our entries back to the list. * * If no I/O scheduler has been configured it is possible that * the hardware queue got stopped and restarted before requests * were pushed back onto the dispatch list. Rerun the queue to * avoid starvation. Notes: * - blk_mq_run_hw_queue() checks whether or not a queue has * been stopped before rerunning a queue. * - Some but not all block drivers stop a queue before * returning BLK_STS_RESOURCE. Two exceptions are scsi-mq * and dm-rq. * * If driver returns BLK_STS_RESOURCE and SCHED_RESTART * bit is set, run queue after a delay to avoid IO stalls * that could otherwise occur if the queue is idle. We'll do * similar if we couldn't get budget or couldn't lock a zone * and SCHED_RESTART is set. */
needs_restart = blk_mq_sched_needs_restart(hctx);
if (prep == PREP_DISPATCH_NO_BUDGET)
needs_resource = true;
if (!needs_restart ||
(no_tag && list_empty_careful(&hctx->dispatch_wait.entry)))
blk_mq_run_hw_queue(hctx, true);
elseif (needs_restart && needs_resource)
blk_mq_delay_run_hw_queue(hctx, BLK_MQ_RESOURCE_DELAY);
blk_mq_update_dispatch_busy(hctx, true);
returnfalse;
} elseblk_mq_update_dispatch_busy(hctx, false);
return (queued + errors) != 0;
memory barriers have to be used for ordering the following two pair of OPs:
1) adding requests to hctx->dispatch and checking SCHED_RESTART inblk_mq_dispatch_rq_list()
2) clearing SCHED_RESTART and checking if there is request in hctx->dispatch in blk_mq_sched_restart().
Without the added memory barrier, either:
1) blk_mq_sched_restart() may miss requests added to hctx->dispatch meantime blk_mq_dispatch_rq_list() observes SCHED_RESTART, and not run queue in dispatch side
or
2) blk_mq_dispatch_rq_list still sees SCHED_RESTART, and not run queue
in dispatch side, meantime checking if there is request in
hctx->dispatch from blk_mq_sched_restart() is missed.
biosnoop は、IO要求発行(blk_mq_start_request)と IO完了(blk_account_io_done) における BIO のステータスを確認することができる。
このスクリプトを実行することで下記のような結果を得ることができる。
TIME(s) COMM PID DISK T SECTOR BYTES QUE(ms) LAT(ms)
0.000000 mount 4349 sda R 2050 1024 0.06 0.46
0.000396 mount 4349 sda R 2048 4096 0.05 0.19
0.000713 mount 4349 sda R 2056 4096 0.05 0.18
0.000826 mount 4349 sda R 2064 4096 0.05 0.18
0.000968 mount 4349 sda R 2072 4096 0.05 0.16
0.001165 mount 4349 sda R 2080 4096 0.09 0.17
// 1479:staticvoid__blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx)
{
int srcu_idx;
/* * We can't run the queue inline with ints disabled. Ensure that * we catch bad users of this early. */WARN_ON_ONCE(in_interrupt());
might_sleep_if(hctx->flags & BLK_MQ_F_BLOCKING);
hctx_lock(hctx, &srcu_idx);
blk_mq_sched_dispatch_requests(hctx);
hctx_unlock(hctx, srcu_idx);
}
// 346:voidblk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx)
{
struct request_queue *q = hctx->queue;
/* RCU or SRCU read lock is needed before checking quiesced flag */if (unlikely(blk_mq_hctx_stopped(hctx) || blk_queue_quiesced(q)))
return;
hctx->run++;
/* * A return of -EAGAIN is an indication that hctx->dispatch is not * empty and we must run again in order to avoid starving flushes. */if (__blk_mq_sched_dispatch_requests(hctx) == -EAGAIN) {
if (__blk_mq_sched_dispatch_requests(hctx) == -EAGAIN)
blk_mq_run_hw_queue(hctx, true);
}
}
// 294:staticint__blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx)
{
struct request_queue *q = hctx->queue;
constbool has_sched = q->elevator;
int ret = 0;
LIST_HEAD(rq_list);
/* * If we have previous entries on our dispatch list, grab them first for * more fair dispatch. */if (!list_empty_careful(&hctx->dispatch)) {
spin_lock(&hctx->lock);
if (!list_empty(&hctx->dispatch))
list_splice_init(&hctx->dispatch, &rq_list);
spin_unlock(&hctx->lock);
}
/* * Only ask the scheduler for requests, if we didn't have residual * requests from the dispatch list. This is to avoid the case where * we only ever dispatch a fraction of the requests available because * of low device queue depth. Once we pull requests out of the IO * scheduler, we can no longer merge or sort them. So it's best to * leave them there for as long as we can. Mark the hw queue as * needing a restart in that case. * * We want to dispatch from the scheduler if there was nothing * on the dispatch list or we were able to dispatch from the * dispatch list. */if (!list_empty(&rq_list)) {
blk_mq_sched_mark_restart_hctx(hctx);
if (blk_mq_dispatch_rq_list(hctx, &rq_list, 0)) {
if (has_sched)
ret = blk_mq_do_dispatch_sched(hctx);
else
ret = blk_mq_do_dispatch_ctx(hctx);
}
} elseif (has_sched) {
ret = blk_mq_do_dispatch_sched(hctx);
} elseif (hctx->dispatch_busy) {
/* dequeue request one by one from sw queue if queue is busy */
ret = blk_mq_do_dispatch_ctx(hctx);
} else {
blk_mq_flush_busy_ctxs(hctx, &rq_list);
blk_mq_dispatch_rq_list(hctx, &rq_list, 0);
}
return ret;
}
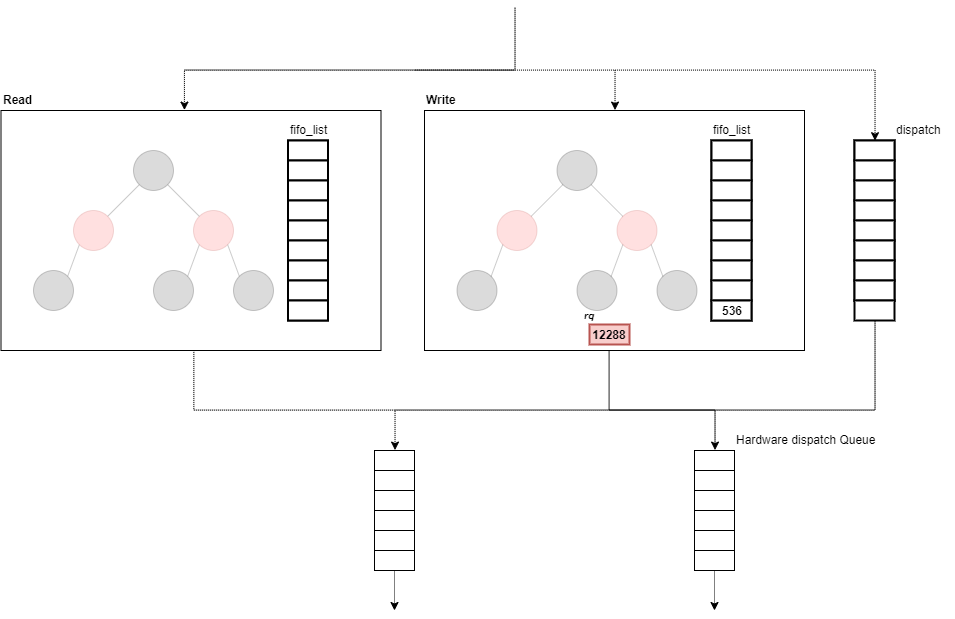
// 362:staticstruct request *__dd_dispatch_request(struct deadline_data *dd,
struct dd_per_prio *per_prio)
{
struct request *rq, *next_rq;
enum dd_data_dir data_dir;
enum dd_prio prio;
u8 ioprio_class;
lockdep_assert_held(&dd->lock);
if (!list_empty(&per_prio->dispatch)) {
rq = list_first_entry(&per_prio->dispatch, struct request,
queuelist);
list_del_init(&rq->queuelist);
goto done;
}
/* * batches are currently reads XOR writes */
rq = deadline_next_request(dd, per_prio, dd->last_dir);
if (rq && dd->batching < dd->fifo_batch)
/* we have a next request are still entitled to batch */goto dispatch_request;
/* * at this point we are not running a batch. select the appropriate * data direction (read / write) */if (!list_empty(&per_prio->fifo_list[DD_READ])) {
BUG_ON(RB_EMPTY_ROOT(&per_prio->sort_list[DD_READ]));
if (deadline_fifo_request(dd, per_prio, DD_WRITE) &&
(dd->starved++ >= dd->writes_starved))
goto dispatch_writes;
data_dir = DD_READ;
goto dispatch_find_request;
}
/* * there are either no reads or writes have been starved */if (!list_empty(&per_prio->fifo_list[DD_WRITE])) {
dispatch_writes:
BUG_ON(RB_EMPTY_ROOT(&per_prio->sort_list[DD_WRITE]));
dd->starved = 0;
data_dir = DD_WRITE;
goto dispatch_find_request;
}
returnNULL;
dispatch_find_request:
/* * we are not running a batch, find best request for selected data_dir */
next_rq = deadline_next_request(dd, per_prio, data_dir);
if (deadline_check_fifo(per_prio, data_dir) || !next_rq) {
/* * A deadline has expired, the last request was in the other * direction, or we have run out of higher-sectored requests. * Start again from the request with the earliest expiry time. */
rq = deadline_fifo_request(dd, per_prio, data_dir);
} else {
/* * The last req was the same dir and we have a next request in * sort order. No expired requests so continue on from here. */
rq = next_rq;
}
/* * For a zoned block device, if we only have writes queued and none of * them can be dispatched, rq will be NULL. */if (!rq)
returnNULL;
dd->last_dir = data_dir;
dd->batching = 0;
dispatch_request:
/* * rq is the selected appropriate request. */
dd->batching++;
deadline_move_request(dd, per_prio, rq);
done:
ioprio_class = dd_rq_ioclass(rq);
prio = ioprio_class_to_prio[ioprio_class];
dd_count(dd, dispatched, prio);
/* * If the request needs its target zone locked, do it. */blk_req_zone_write_lock(rq);
rq->rq_flags |= RQF_STARTED;
return rq;
}
// 192:staticvoiddeadline_remove_request(struct request_queue *q,
struct dd_per_prio *per_prio,
struct request *rq)
{
list_del_init(&rq->queuelist);
/* * We might not be on the rbtree, if we are doing an insert merge */if (!RB_EMPTY_NODE(&rq->rb_node))
deadline_del_rq_rb(per_prio, rq);
elv_rqhash_del(q, rq);
if (q->last_merge == rq)
q->last_merge = NULL;
}