Linuxカーネルのファイルアクセスの処理を追いかける (9) writeback
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、wb_workfn関数からwrite_inodeとwritepagesを呼びところまで確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。

本記事では、writebackカーネルスレッドからwritepagesとwrite_inodeを呼び出すまでを確認する。
writebackするための条件確認
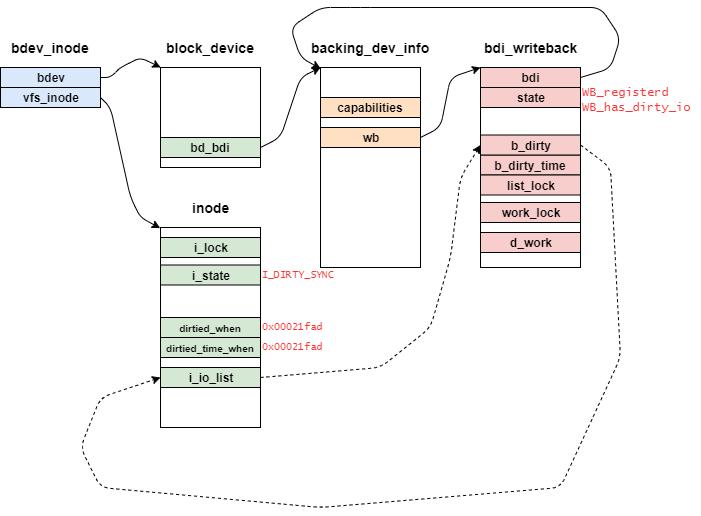
wb_wakeup_delayed関数から呼び出すwb_workfn関数の定義は下記の通りとなっている。
// 2219: void wb_workfn(struct work_struct *work) { struct bdi_writeback *wb = container_of(to_delayed_work(work), struct bdi_writeback, dwork); long pages_written; set_worker_desc("flush-%s", bdi_dev_name(wb->bdi)); current->flags |= PF_SWAPWRITE; if (likely(!current_is_workqueue_rescuer() || !test_bit(WB_registered, &wb->state))) { /* * The normal path. Keep writing back @wb until its * work_list is empty. Note that this path is also taken * if @wb is shutting down even when we're running off the * rescuer as work_list needs to be drained. */ do { pages_written = wb_do_writeback(wb); trace_writeback_pages_written(pages_written); } while (!list_empty(&wb->work_list)); } else { /* * bdi_wq can't get enough workers and we're running off * the emergency worker. Don't hog it. Hopefully, 1024 is * enough for efficient IO. */ pages_written = writeback_inodes_wb(wb, 1024, WB_REASON_FORKER_THREAD); trace_writeback_pages_written(pages_written); } if (!list_empty(&wb->work_list)) wb_wakeup(wb); else if (wb_has_dirty_io(wb) && dirty_writeback_interval) wb_wakeup_delayed(wb); current->flags &= ~PF_SWAPWRITE; }
wb_workfn関数は、wb_init関数のINIT_DELAYED_WORKマクロによって追加されたworkである。
container_ofマクロを使うことで、元の構造体bdi_writebackを取得することができる。
また、現在のプロセスにスワップへのアクセスを許可するためにPF_SWAPWRITEを立てる。
current_is_workqueue_rescuer関数は、導入時のコミットメッセージから「Work Queue rescuerを実行しているかどうかを確認する」ものだろう。
そのため、ここでは通常時の 2228行のif文がTrueの場合のみを考慮する。
wb_do_writeback関数は次のようになっている。
// 2188: static long wb_do_writeback(struct bdi_writeback *wb) { struct wb_writeback_work *work; long wrote = 0; set_bit(WB_writeback_running, &wb->state); while ((work = get_next_work_item(wb)) != NULL) { trace_writeback_exec(wb, work); wrote += wb_writeback(wb, work); finish_writeback_work(wb, work); } /* * Check for a flush-everything request */ wrote += wb_check_start_all(wb); /* * Check for periodic writeback, kupdated() style */ wrote += wb_check_old_data_flush(wb); wrote += wb_check_background_flush(wb); clear_bit(WB_writeback_running, &wb->state); return wrote; }
wb_do_writeback関数は、次のような処理を担う。
wb_writeback_workを順番に実行していく- 特定の条件を満たしているページキャッシュをwritebackする
ここで、「特定の条件」について軽く確認しておくと、次の通りとなっている。
wb_check_start_all: writebackが途中となっている状態かどうかを確認するwb_check_old_data_flush: Dirtyになってからdirty_writeback_centisecs時間経過しているかどうかを確認する。wb_check_background_flush: 現在キャッシュされているDirtyなページがしきい値を超えているかどうかを確認する。
これらの条件が満たされている場合、次のようなwb_writeback_workを引数にwb_writebackを実行する。
| 変数名 | wb_check_start_all | wb_check_old_data_flush | wb_check_background_flush |
|---|---|---|---|
| nr_pages | wb_split_bdi_pages(wb, nr_pages) | nr_pages | LONG_MAX |
| sync_mode | WB_SYNC_NONE | WB_SYNC_NONE | WB_SYNC_NONE |
| for_kupdate | 0 | 1 | 0 |
| for_background | 0 | 0 | 1 |
| range_cyclic | 1 | 1 | 1 |
| reason | wb->start_all_reason | WB_REASON_PERIODIC | WB_REASON_BACKGROUND |
すべてのダーティデータを書き込み
// 2161: static long wb_check_start_all(struct bdi_writeback *wb) { long nr_pages; if (!test_bit(WB_start_all, &wb->state)) return 0; nr_pages = get_nr_dirty_pages(); if (nr_pages) { struct wb_writeback_work work = { .nr_pages = wb_split_bdi_pages(wb, nr_pages), .sync_mode = WB_SYNC_NONE, .range_cyclic = 1, .reason = wb->start_all_reason, }; nr_pages = wb_writeback(wb, &work); } clear_bit(WB_start_all, &wb->state); return nr_pages; }
wb_check_start_all関数は、次の場合にwb_writeback関数で指定されたページをwritebackする関数となっている。
WB_start_allフラグが立っている場合 (他プロセスによるwritebackがまだ終わっていない場合)- Dirtyとなっているページが存在する場合
bdi_writeback構造体にWB_start_allフラグがセットされているのは、wb_start_writeback関数のみとなっている。
// 1222: static void wb_start_writeback(struct bdi_writeback *wb, enum wb_reason reason) { if (!wb_has_dirty_io(wb)) return; /* * All callers of this function want to start writeback of all * dirty pages. Places like vmscan can call this at a very * high frequency, causing pointless allocations of tons of * work items and keeping the flusher threads busy retrieving * that work. Ensure that we only allow one of them pending and * inflight at the time. */ if (test_bit(WB_start_all, &wb->state) || test_and_set_bit(WB_start_all, &wb->state)) return; wb->start_all_reason = reason; wb_wakeup(wb); }
この関数は、wb_io_lists_populated関数が実行されてからwb_io_lists_depopulated関数が実行されるまでの間でのみ、WB_start_allフラグをセットする。
そして、WB_start_allフラグがセットできた場合には、wb_wakeup関数によってmod_delayed_work関数を実行する。
mod_delayed_work関数については、前章のWork QueueのAPIとなっている。
expireしたデータをフラッシュする
// 2127: static long wb_check_old_data_flush(struct bdi_writeback *wb) { unsigned long expired; long nr_pages; /* * When set to zero, disable periodic writeback */ if (!dirty_writeback_interval) return 0; expired = wb->last_old_flush + msecs_to_jiffies(dirty_writeback_interval * 10); if (time_before(jiffies, expired)) return 0; wb->last_old_flush = jiffies; nr_pages = get_nr_dirty_pages(); if (nr_pages) { struct wb_writeback_work work = { .nr_pages = nr_pages, .sync_mode = WB_SYNC_NONE, .for_kupdate = 1, .range_cyclic = 1, .reason = WB_REASON_PERIODIC, }; return wb_writeback(wb, &work); } return 0; }
wb_check_old_data_flush関数は、次の場合にwb_writeback関数で指定されたページをwritebackする関数となっている。
dirty_writeback_intervalが設定されている場合- 前回の
wb_check_old_data_flush関数が実行されてからdirty_writeback_interval× 10 ミリ秒経過している場合 - ノード内にある
NR_FILE_DIRTYのページが存在する場合
dirty_writeback_intervalは、カーネルがwritebackを定期的に実行する間隔となっている。
この値は、{procfs}/sys/vm/dirty_writeback_centisecs で設定することができる。 (本実験環境では、デフォルト値として500が設定されていた)
この時、get_nr_dirty_pages関数によって、Dirty (となっている) のページの数を取得する。
// 1216: static unsigned long get_nr_dirty_pages(void) { return global_node_page_state(NR_FILE_DIRTY) + get_nr_dirty_inodes(); }
get_nr_dirty_pages関数では、ノード内にあるNR_FILE_DIRTYのページとDirtyとなっている大まかなinodeの数を返す。
Backgroundによる書き込みの閾値を超えている
別の記事で取り上げることにする。
writebackを開始する
これまでにwritebackする条件を満たしていた場合、writebackする単位をworkとしてwb_writeback関数を実行する。
また、workには次の値が渡される。 (再掲)
| 変数名 | wb_check_start_all | wb_check_old_data_flush | wb_check_background_flush |
|---|---|---|---|
| nr_pages | ノード内にあるDirtyページ (最大) | ノード内にあるDirtyページ数 | LONG_MAX |
| sync_mode | WB_SYNC_NONE | WB_SYNC_NONE | WB_SYNC_NONE |
| for_kupdate | 0 | 1 | 0 |
| for_background | 0 | 0 | 1 |
| range_cyclic | 1 | 1 | 1 |
| reason | WB_REASON_LAPTOP_TIMER WB_REASON_SYNC WB_REASON_PERIODIC WB_REASON_VMSCAN |
WB_REASON_PERIODIC | WB_REASON_BACKGROUND |
wb_writeback関数の定義は次の通りとなっている。
// 2002: static long wb_writeback(struct bdi_writeback *wb, struct wb_writeback_work *work) { long nr_pages = work->nr_pages; unsigned long dirtied_before = jiffies; struct inode *inode; long progress; struct blk_plug plug; blk_start_plug(&plug); spin_lock(&wb->list_lock); for (;;) { /* * Stop writeback when nr_pages has been consumed */ if (work->nr_pages <= 0) break; /* * Background writeout and kupdate-style writeback may * run forever. Stop them if there is other work to do * so that e.g. sync can proceed. They'll be restarted * after the other works are all done. */ if ((work->for_background || work->for_kupdate) && !list_empty(&wb->work_list)) break; /* * For background writeout, stop when we are below the * background dirty threshold */ if (work->for_background && !wb_over_bg_thresh(wb)) break; /* * Kupdate and background works are special and we want to * include all inodes that need writing. Livelock avoidance is * handled by these works yielding to any other work so we are * safe. */ if (work->for_kupdate) { dirtied_before = jiffies - msecs_to_jiffies(dirty_expire_interval * 10); } else if (work->for_background) dirtied_before = jiffies; trace_writeback_start(wb, work); if (list_empty(&wb->b_io)) queue_io(wb, work, dirtied_before); if (work->sb) progress = writeback_sb_inodes(work->sb, wb, work); else progress = __writeback_inodes_wb(wb, work); trace_writeback_written(wb, work); /* * Did we write something? Try for more * * Dirty inodes are moved to b_io for writeback in batches. * The completion of the current batch does not necessarily * mean the overall work is done. So we keep looping as long * as made some progress on cleaning pages or inodes. */ if (progress) continue; /* * No more inodes for IO, bail */ if (list_empty(&wb->b_more_io)) break; /* * Nothing written. Wait for some inode to * become available for writeback. Otherwise * we'll just busyloop. */ trace_writeback_wait(wb, work); inode = wb_inode(wb->b_more_io.prev); spin_lock(&inode->i_lock); spin_unlock(&wb->list_lock); /* This function drops i_lock... */ inode_sleep_on_writeback(inode); spin_lock(&wb->list_lock); } spin_unlock(&wb->list_lock); blk_finish_plug(&plug); return nr_pages - work->nr_pages; }
wb_writeback関数では、workの内容次第で処理が異なる。
wb_check_start_all関数が追加したworkの場合
bdi_writeback構造体に繋がっているすべてのinodeをexpiredとし、writebackを開始する。
- 最初の条件分岐 (2017行目)では、他の要因によってDirtyページがすべて書き出されていない限り条件を満たさない。
- 2つ目の条件分岐 (2026行目)では、
for_backgroundとfor_kupdateフラグが立っていないので条件を満たさない。 - 3つ目の条件分岐 (2034行目)では、
for_backgroundフラグが立っていないので条件を満たさない。 - 4つ目の条件分岐 (2043, 2046行目)では、
for_backgroundとfor_kupdateフラグが立っていないので条件を満たさない。 - 5つ目の条件分岐 (2050行目)では、
wb->b_ioが空であった場合、queue_io関数を実行する。 - 6つ目の条件分岐 (2052行目)では、
work->sbがNULLであるため、__writeback_inode_wb関数を実行する。
wb_b_ioリストが空queue_io関数の定義は次の通りとなっている。
// 1445: static void queue_io(struct bdi_writeback *wb, struct wb_writeback_work *work, unsigned long dirtied_before) { int moved; unsigned long time_expire_jif = dirtied_before; assert_spin_locked(&wb->list_lock); list_splice_init(&wb->b_more_io, &wb->b_io); moved = move_expired_inodes(&wb->b_dirty, &wb->b_io, dirtied_before); if (!work->for_sync) time_expire_jif = jiffies - dirtytime_expire_interval * HZ; moved += move_expired_inodes(&wb->b_dirty_time, &wb->b_io, time_expire_jif); if (moved) wb_io_lists_populated(wb); trace_writeback_queue_io(wb, work, dirtied_before, moved); }
引数にあるdirtied_beforeは、expireとなるtick数を表している。(つまりこの値より小さい場合には、expairdなinodeとなる)
次のような手順でbdi_writeback構造体のメンバb_ioにinodeを追加する。
b_more_ioに連結しているノードをb_ioに繋げるb_dirtyに連結しているexpiredなノードをb_ioに繋げるb_dirty_timeに連結しているexpiredなノードをb_ioに繋げる
ここで、次のような状態のbdi_writeback構造体に対してqueue_io関数を実行したときを考えてみる。
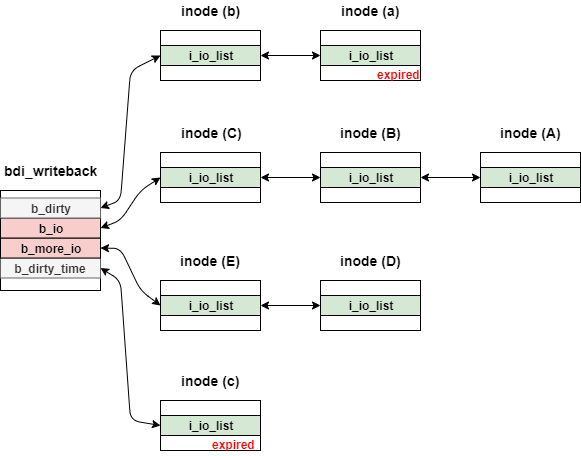
実際には、各ノードの末尾は先頭とつながっているが簡略化の都合上、図からは排除している。
また、b_dirtyとb_dirty_timeはメンバ内のdirtied_whenに依存してノードの追加をするが、簡略化の都合上、対象のノードにはexpiredと赤字を付けている。
まず初めに、b_more_ioとb_ioを引数としてlist_splice_init関数を実行する。
list_splice_init関数は下記の通りとなっている。
// 478: static inline void list_splice_init(struct list_head *list, struct list_head *head) { if (!list_empty(list)) { __list_splice(list, head, head->next); INIT_LIST_HEAD(list); } }
__list_splice関数は、headのnextにlistを挿入する関数となっている。
その結果、b_more_ioに連結していたinode (E) と inode (D) が b_io の先頭に挿入される。
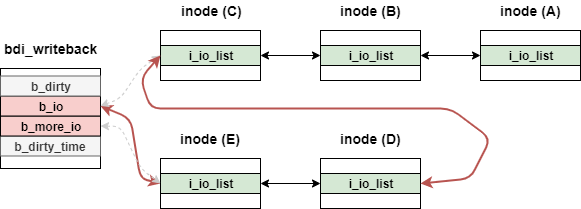
その後、b_dirtyとb_dirty_timeそれぞれに対して、move_expired_inodes関数を実行する。
この時、第3引数のdirtied_beforeには、expireとなるtick数を渡している。
move_expired_inodes関数の定義は次の通りとなっている。
// 1338: static int move_expired_inodes(struct list_head *delaying_queue, struct list_head *dispatch_queue, unsigned long dirtied_before) { LIST_HEAD(tmp); struct list_head *pos, *node; struct super_block *sb = NULL; struct inode *inode; int do_sb_sort = 0; int moved = 0; while (!list_empty(delaying_queue)) { inode = wb_inode(delaying_queue->prev); if (inode_dirtied_after(inode, dirtied_before)) break; list_move(&inode->i_io_list, &tmp); moved++; spin_lock(&inode->i_lock); inode->i_state |= I_SYNC_QUEUED; spin_unlock(&inode->i_lock); if (sb_is_blkdev_sb(inode->i_sb)) continue; if (sb && sb != inode->i_sb) do_sb_sort = 1; sb = inode->i_sb; } /* just one sb in list, splice to dispatch_queue and we're done */ if (!do_sb_sort) { list_splice(&tmp, dispatch_queue); goto out; } /* Move inodes from one superblock together */ while (!list_empty(&tmp)) { sb = wb_inode(tmp.prev)->i_sb; list_for_each_prev_safe(pos, node, &tmp) { inode = wb_inode(pos); if (inode->i_sb == sb) list_move(&inode->i_io_list, dispatch_queue); } } out: return moved; }
move_expired_inodes関数では、inode_dirtied_after関数で対象のinodeがexpireしているかどうか確認し、変数tmpを介してdispatch_queue(今回の場合はb_io)に繋げていく。

b_dirtyに対してmore_expired_inodes関数を実行した結果は、inode(a)がb_ioの先頭に挿入される。
最終的に、queue_io関数実行後には次のような状態となっている。

この時、b_ioに連結しているノードがwritebackの対象となる。
wb_check_old_data_flush関数が追加したworkの場合
bdi_writeback構造体に繋がっているinodeで、Dirtyになってからdirty_expire_interval × 10 ミリ秒経過しているinodeのみ、writebackを開始する。
- 最初の条件分岐 (2017行目)では、他の要因によってDirtyページがすべて書き出されていない限り条件を満たさない。
- 2つ目の条件分岐 (2026行目)では、
for_kupdateフラグが立っているので、wb->work_listが空の場合、処理を中断する。 - 3つ目の条件分岐 (2034行目)では、
for_backgroundフラグが立っていないので条件を満たさない。 - 4つ目の条件分岐 (2043, 2046行目)では、
for_kupdateフラグが立っているので、dirtied_beforeを更新する。 - 5つ目の条件分岐 (2050行目)では、
wb->b_ioが空であった場合、queue_io関数を実行する。 - 6つ目の条件分岐 (2052行目)では、
work->sbがNULLであるため、__writeback_inode_wb関数を実行する。
wb_check_background_flush関数が追加したworkの場合
- 最初の条件分岐 (2017行目)では、
LONG_MAXなので条件を満たさない。 - 2つ目の条件分岐 (2026行目)では、
for_backgroundフラグが立っているので、wb->work_listが空の場合、処理を中断する。 - 3つ目の条件分岐 (2034行目)では、
for_backgroundフラグが立っているので、wb_over_bg_thresh関数の結果次第では処理を中断する。 - 4つ目の条件分岐 (2043, 2046目)では、
for_backgroundフラグが立っているので、dirtied_beforeを更新する。 - 5つ目の条件分岐 (2050行目)では、
wb->b_ioが空であった場合、queue_io関数を実行する。 - 6つ目の条件分岐 (2052行目)では、
work->sbが未設定であるため、__writeback_inode_wb関数を実行する。
inodeのwrite-backを開始する
上記3つのパターンからwb_writeback関数を直接呼び出した場合には、__writeback_inodes_wb関数が呼び出される。
__writeback_inodes_wb関数の定義は次の通りとなっている。
// 1931: static long __writeback_inodes_wb(struct bdi_writeback *wb, struct wb_writeback_work *work) { unsigned long start_time = jiffies; long wrote = 0; while (!list_empty(&wb->b_io)) { struct inode *inode = wb_inode(wb->b_io.prev); struct super_block *sb = inode->i_sb; if (!trylock_super(sb)) { /* * trylock_super() may fail consistently due to * s_umount being grabbed by someone else. Don't use * requeue_io() to avoid busy retrying the inode/sb. */ redirty_tail(inode, wb); continue; } wrote += writeback_sb_inodes(sb, wb, work); up_read(&sb->s_umount); /* refer to the same tests at the end of writeback_sb_inodes */ if (wrote) { if (time_is_before_jiffies(start_time + HZ / 10UL)) break; if (work->nr_pages <= 0) break; } } /* Leave any unwritten inodes on b_io */ return wrote; }
__writeback_inodes_wb関数は、superblock構造体のs_umount(アンマウント用のセマフォ)を獲得したうえで、writeback_sb_inodes関数を呼び出す。
writeback_sb_inodes関数は次の通りとなっている。
// 1789: static long writeback_sb_inodes(struct super_block *sb, struct bdi_writeback *wb, struct wb_writeback_work *work) { struct writeback_control wbc = { .sync_mode = work->sync_mode, .tagged_writepages = work->tagged_writepages, .for_kupdate = work->for_kupdate, .for_background = work->for_background, .for_sync = work->for_sync, .range_cyclic = work->range_cyclic, .range_start = 0, .range_end = LLONG_MAX, }; unsigned long start_time = jiffies; long write_chunk; long wrote = 0; /* count both pages and inodes */ while (!list_empty(&wb->b_io)) { struct inode *inode = wb_inode(wb->b_io.prev); struct bdi_writeback *tmp_wb; if (inode->i_sb != sb) { if (work->sb) { /* * We only want to write back data for this * superblock, move all inodes not belonging * to it back onto the dirty list. */ redirty_tail(inode, wb); continue; } /* * The inode belongs to a different superblock. * Bounce back to the caller to unpin this and * pin the next superblock. */ break; } /* * Don't bother with new inodes or inodes being freed, first * kind does not need periodic writeout yet, and for the latter * kind writeout is handled by the freer. */ spin_lock(&inode->i_lock); if (inode->i_state & (I_NEW | I_FREEING | I_WILL_FREE)) { redirty_tail_locked(inode, wb); spin_unlock(&inode->i_lock); continue; } if ((inode->i_state & I_SYNC) && wbc.sync_mode != WB_SYNC_ALL) { /* * If this inode is locked for writeback and we are not * doing writeback-for-data-integrity, move it to * b_more_io so that writeback can proceed with the * other inodes on s_io. * * We'll have another go at writing back this inode * when we completed a full scan of b_io. */ spin_unlock(&inode->i_lock); requeue_io(inode, wb); trace_writeback_sb_inodes_requeue(inode); continue; } spin_unlock(&wb->list_lock); /* * We already requeued the inode if it had I_SYNC set and we * are doing WB_SYNC_NONE writeback. So this catches only the * WB_SYNC_ALL case. */ if (inode->i_state & I_SYNC) { /* Wait for I_SYNC. This function drops i_lock... */ inode_sleep_on_writeback(inode); /* Inode may be gone, start again */ spin_lock(&wb->list_lock); continue; } inode->i_state |= I_SYNC; wbc_attach_and_unlock_inode(&wbc, inode); write_chunk = writeback_chunk_size(wb, work); wbc.nr_to_write = write_chunk; wbc.pages_skipped = 0; /* * We use I_SYNC to pin the inode in memory. While it is set * evict_inode() will wait so the inode cannot be freed. */ __writeback_single_inode(inode, &wbc); wbc_detach_inode(&wbc); work->nr_pages -= write_chunk - wbc.nr_to_write; wrote += write_chunk - wbc.nr_to_write; if (need_resched()) { /* * We're trying to balance between building up a nice * long list of IOs to improve our merge rate, and * getting those IOs out quickly for anyone throttling * in balance_dirty_pages(). cond_resched() doesn't * unplug, so get our IOs out the door before we * give up the CPU. */ blk_flush_plug(current); cond_resched(); } /* * Requeue @inode if still dirty. Be careful as @inode may * have been switched to another wb in the meantime. */ tmp_wb = inode_to_wb_and_lock_list(inode); spin_lock(&inode->i_lock); if (!(inode->i_state & I_DIRTY_ALL)) wrote++; requeue_inode(inode, tmp_wb, &wbc); inode_sync_complete(inode); spin_unlock(&inode->i_lock); if (unlikely(tmp_wb != wb)) { spin_unlock(&tmp_wb->list_lock); spin_lock(&wb->list_lock); } /* * bail out to wb_writeback() often enough to check * background threshold and other termination conditions. */ if (wrote) { if (time_is_before_jiffies(start_time + HZ / 10UL)) break; if (work->nr_pages <= 0) break; } } return wrote; }
writeback_sb_inodes関数では、b_ioにつながっているinode構造体を末尾から取り出していき、処理を続けていく。
ただし、次のような状態の場合にも対応しなければならない。
inodeを保持しているsuper blockと、bdi_writebackで管理しているsuper blockが異なる場合- 新しい
inodeや解放されるinodeである場合 inodeにSYNCフラグが立っているが、bdi_writebackではWB_SYNC_ALLフラグが立っていない場合
一つ目のケースでは、redirty_tail関数によってbdi_writebackで管理しているsuper block構造体で再度Dirtyフラグをセットする。
redirty_tail関数の定義は下記の通りとなっている。
// 1332: static void redirty_tail(struct inode *inode, struct bdi_writeback *wb) { spin_lock(&inode->i_lock); redirty_tail_locked(inode, wb); spin_unlock(&inode->i_lock); }
redirty_tail関数では、inodeのデータを書き換えるのでi_lockでロックする必要がある。
実際にDirtyフラグをセットする処理はredirty_tail_locked関数となっている。
redirty_tail_locked関数は次の通りとなっている。
// 1327: static void redirty_tail_locked(struct inode *inode, struct bdi_writeback *wb) { assert_spin_locked(&inode->i_lock); if (!list_empty(&wb->b_dirty)) { struct inode *tail; tail = wb_inode(wb->b_dirty.next); if (time_before(inode->dirtied_when, tail->dirtied_when)) inode->dirtied_when = jiffies; } inode_io_list_move_locked(inode, wb, &wb->b_dirty); inode->i_state &= ~I_SYNC_QUEUED; }
redirty_tail_locaked関数は、inodeをb_dirtyリストに追加する。
この時、inodeがb_dirtyリストの先頭inodeのDirtyになった時刻より古い場合には、Dirtyになった時刻を更新する。

二つ目のケースでも同様に、redirty_tail_lock関数によってbdi_writebackで管理しているsuper block構造体で再度Dirtyフラグをセットする。
三つ目のケースでは同様に、inode_sleep_on_writeback関数によってbdi_writebackで管理しているsuper block構造体で再度Dirtyフラグをセットする。
inode_sleep_on_writeback関数の定義は下記の通りとなっている。
// 1511: static void inode_sleep_on_writeback(struct inode *inode) __releases(inode->i_lock) { DEFINE_WAIT(wait); wait_queue_head_t *wqh = bit_waitqueue(&inode->i_state, __I_SYNC); int sleep; prepare_to_wait(wqh, &wait, TASK_UNINTERRUPTIBLE); sleep = inode->i_state & I_SYNC; spin_unlock(&inode->i_lock); if (sleep) schedule(); finish_wait(wqh, &wait); }
inode_sleep_on_writeback関数の詳細は省略するが、I_SYNCがクリアされるまでスリープする関数となっている。
以降はinodeをwritebackのための下準備を実施する。
inodeにI_SYNCフラグをセットするwbc(writebackに関する情報) にwriteback予定のinodeを関連付けるwbc_attach_and_unlock_inode関数の説明は省く
- 書き込みサイズを設定する。
writeback_chunk_size関数の説明は省く
そして、__writeback_single_inode関数により、Dirtyとなっているページとinodeのwritebackを実施する。
__writeback_single_inode関数の定義は次の通りとなっている。
// 1605: static int __writeback_single_inode(struct inode *inode, struct writeback_control *wbc) { struct address_space *mapping = inode->i_mapping; long nr_to_write = wbc->nr_to_write; unsigned dirty; int ret; WARN_ON(!(inode->i_state & I_SYNC)); trace_writeback_single_inode_start(inode, wbc, nr_to_write); ret = do_writepages(mapping, wbc); /* * Make sure to wait on the data before writing out the metadata. * This is important for filesystems that modify metadata on data * I/O completion. We don't do it for sync(2) writeback because it has a * separate, external IO completion path and ->sync_fs for guaranteeing * inode metadata is written back correctly. */ if (wbc->sync_mode == WB_SYNC_ALL && !wbc->for_sync) { int err = filemap_fdatawait(mapping); if (ret == 0) ret = err; } /* * If the inode has dirty timestamps and we need to write them, call * mark_inode_dirty_sync() to notify the filesystem about it and to * change I_DIRTY_TIME into I_DIRTY_SYNC. */ if ((inode->i_state & I_DIRTY_TIME) && (wbc->sync_mode == WB_SYNC_ALL || time_after(jiffies, inode->dirtied_time_when + dirtytime_expire_interval * HZ))) { trace_writeback_lazytime(inode); mark_inode_dirty_sync(inode); } /* * Get and clear the dirty flags from i_state. This needs to be done * after calling writepages because some filesystems may redirty the * inode during writepages due to delalloc. It also needs to be done * after handling timestamp expiration, as that may dirty the inode too. */ spin_lock(&inode->i_lock); dirty = inode->i_state & I_DIRTY; inode->i_state &= ~dirty; /* * Paired with smp_mb() in __mark_inode_dirty(). This allows * __mark_inode_dirty() to test i_state without grabbing i_lock - * either they see the I_DIRTY bits cleared or we see the dirtied * inode. * * I_DIRTY_PAGES is always cleared together above even if @mapping * still has dirty pages. The flag is reinstated after smp_mb() if * necessary. This guarantees that either __mark_inode_dirty() * sees clear I_DIRTY_PAGES or we see PAGECACHE_TAG_DIRTY. */ smp_mb(); if (mapping_tagged(mapping, PAGECACHE_TAG_DIRTY)) inode->i_state |= I_DIRTY_PAGES; spin_unlock(&inode->i_lock); /* Don't write the inode if only I_DIRTY_PAGES was set */ if (dirty & ~I_DIRTY_PAGES) { int err = write_inode(inode, wbc); if (ret == 0) ret = err; } trace_writeback_single_inode(inode, wbc, nr_to_write); return ret; }
__writeback_single_inode関数の大きな流れは次の通りとなっている。
do_writepages関数で、inode関連づいているページでDirtyとなっているものをwritebackする。- 必要に応じてDirtyページの書き込みが完了するまで待つ。
- 必要に応じてinodeをDirtyにする。
write_inode関数で、inodeをwritebackする。
この中でwritebackの主の処理となっているdo_writepages関数とwrite_inode関数を確認していく。
do_writepages関数の定義は次の通りとなっている。
// 2353: int do_writepages(struct address_space *mapping, struct writeback_control *wbc) { int ret; struct bdi_writeback *wb; if (wbc->nr_to_write <= 0) return 0; wb = inode_to_wb_wbc(mapping->host, wbc); wb_bandwidth_estimate_start(wb); while (1) { if (mapping->a_ops->writepages) ret = mapping->a_ops->writepages(mapping, wbc); else ret = generic_writepages(mapping, wbc); if ((ret != -ENOMEM) || (wbc->sync_mode != WB_SYNC_ALL)) break; cond_resched(); congestion_wait(BLK_RW_ASYNC, HZ/50); } /* * Usually few pages are written by now from those we've just submitted * but if there's constant writeback being submitted, this makes sure * writeback bandwidth is updated once in a while. */ if (time_is_before_jiffies(READ_ONCE(wb->bw_time_stamp) + BANDWIDTH_INTERVAL)) wb_update_bandwidth(wb); return ret; }
mappingにwritebpagesの関数が定義されている場合にはそれを呼び出し、そうでなければ汎用のgeneric_writepages関数を呼び出す。
今回の場合では、ext2_writepages関数が設定されている。
write_inode関数の定義は次の通りとなっている。
// 1463: static int write_inode(struct inode *inode, struct writeback_control *wbc) { int ret; if (inode->i_sb->s_op->write_inode && !is_bad_inode(inode)) { trace_writeback_write_inode_start(inode, wbc); ret = inode->i_sb->s_op->write_inode(inode, wbc); trace_writeback_write_inode(inode, wbc); return ret; } return 0; }
write_inode関数では、do_writepages関数と同様にinodeに設定されているwrite_inodeを呼び出す。
今回の場合では、ext2_write_inode関数が設定されている。
Dirtyとなっているページキャッシュとinodeの書き込みを実施後はwriteback_sb_inodes関数に戻り、後処理をする。
後処理で実施する内容は次の通りとなっている。
wbcからinodeの関連を削除する- リストから
inodeを削除する inodeのフラグを更新する
おわりに
本記事では、Linux v5.15におけるwriteback kthread (wb_workfn関数)を確認した。
変更履歴
- 2022/02/23: 記事公開
- 2022/09/19: カーネルバージョンを5.15に変更
参考
- アプリがディスクに書き込むまでの動きまとめ - フラミナル
- 書き込み時の動きについて解説されている。
- hiboma/ファイルシステムの実装/30-backing_dev_info.md at master · hiboma/hiboma · GitHub
- tmpfsのソースを参考にv2.6.32のファイルシステムの実装を確認した内容が記載されている
- Linuxのdirty page関連パラメータからコードを読む #kernel - Qiita
- dirty pageの仕組みやその後のシーケンスまで細かく記載されている
- http://baotiao.github.io/2017/03/02/data-to-disk/
- 中国語の記事となっているが、構造体の相関図が記載されている。
- VFS基础学习笔记 - 7. page cache回写 - コードワールド
- 中国語の記事となっているが、writeback処理について記載されている。
- https://www.kernel.org/doc/Documentation/laptops/laptop-mode.txt
- Laptop Modeに関するドキュメント。