Linuxカーネルのファイルアクセスの処理を追いかける (10) ext2: writepages
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
- 概要
- はじめに
- writepagesの概要
- mpage_writepages関数
- write_cache_pages関数
- __mpage_writepage関数
- mpage_bio_submit関数
- おわりに
- 変更履歴
- 参考
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、ext2_writepages関数を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。

本記事では、writebackカーネルスレッドがwritepagesを呼び出すところから、submit_bio関数を呼ぶところまでを確認する。
writepagesの概要
kerner thread のライトバック処理によって、Dirtyのinodeに対してwritepages関数とwrite_inode関数を呼び出す。
基本的には、writepages関数はファイルの実データの書き込み、write_inode関数はファイルのメタデータの書き込みをする。
ext2ファイルシステムの場合では、ext2_writepages関数とext2_write_inode関数が定義されている。

ext2_writepages関数の定義は次の通りとなっている。
// 950: static int ext2_writepages(struct address_space *mapping, struct writeback_control *wbc) { return mpage_writepages(mapping, wbc, ext2_get_block); }
ext2_writepage関数は、mpage_writepage関数を呼び出す。(関数の引数にext2固有の関数ポインタを渡す)
mpage_writepages関数
// 693: int mpage_writepages(struct address_space *mapping, struct writeback_control *wbc, get_block_t get_block) { struct blk_plug plug; int ret; blk_start_plug(&plug); if (!get_block) ret = generic_writepages(mapping, wbc); else { struct mpage_data mpd = { .bio = NULL, .last_block_in_bio = 0, .get_block = get_block, .use_writepage = 1, }; ret = write_cache_pages(mapping, wbc, __mpage_writepage, &mpd); if (mpd.bio) { int op_flags = (wbc->sync_mode == WB_SYNC_ALL ? REQ_SYNC : 0); mpage_bio_submit(REQ_OP_WRITE, op_flags, mpd.bio); } } blk_finish_plug(&plug); return ret; }
ここで、writepages関数では、IOリクエストを管理するためのblk_plug構造体を取り扱う。
blk_start_plug関数で初期化 (または保留されているものを戻す) 、blk_finidh_plug関数で完了を表す。

ext2ファイルシステムでは、独自のget_block関数を渡すため、write_cache_pages関数とmpage_bio_submit関数が主な処理となっている。
write_cache_pages関数は、ext2_writepages関数から渡された関数に加えて、単体ページ書き込み関数__mpage_writepage関数とページ書き込み用メタデータmpage_data構造体を渡す。
ここで、今回の場合におけるwriteback_control構造体の値を再掲する。
| 変数名 | 値 |
|---|---|
| nr_pages | ノード内にあるDirtyページ数 |
| sync_mode | WB_SYNC_NONE |
| for_kupdate | 1 |
| for_background | 0 |
| range_cyclic | 1 |
write_cache_pages関数の定義は次の通りとなっている。
write_cache_pages関数
// 2177: int write_cache_pages(struct address_space *mapping, struct writeback_control *wbc, writepage_t writepage, void *data) { int ret = 0; int done = 0; int error; struct pagevec pvec; int nr_pages; pgoff_t index; pgoff_t end; /* Inclusive */ pgoff_t done_index; int range_whole = 0; xa_mark_t tag; pagevec_init(&pvec); if (wbc->range_cyclic) { index = mapping->writeback_index; /* prev offset */ end = -1; } else { index = wbc->range_start >> PAGE_SHIFT; end = wbc->range_end >> PAGE_SHIFT; if (wbc->range_start == 0 && wbc->range_end == LLONG_MAX) range_whole = 1; } if (wbc->sync_mode == WB_SYNC_ALL || wbc->tagged_writepages) { tag_pages_for_writeback(mapping, index, end); tag = PAGECACHE_TAG_TOWRITE; } else { tag = PAGECACHE_TAG_DIRTY; } done_index = index; while (!done && (index <= end)) { int i; nr_pages = pagevec_lookup_range_tag(&pvec, mapping, &index, end, tag); if (nr_pages == 0) break; for (i = 0; i < nr_pages; i++) { struct page *page = pvec.pages[i]; done_index = page->index; lock_page(page); /* * Page truncated or invalidated. We can freely skip it * then, even for data integrity operations: the page * has disappeared concurrently, so there could be no * real expectation of this data integrity operation * even if there is now a new, dirty page at the same * pagecache address. */ if (unlikely(page->mapping != mapping)) { continue_unlock: unlock_page(page); continue; } if (!PageDirty(page)) { /* someone wrote it for us */ goto continue_unlock; } if (PageWriteback(page)) { if (wbc->sync_mode != WB_SYNC_NONE) wait_on_page_writeback(page); else goto continue_unlock; } BUG_ON(PageWriteback(page)); if (!clear_page_dirty_for_io(page)) goto continue_unlock; trace_wbc_writepage(wbc, inode_to_bdi(mapping->host)); error = (*writepage)(page, wbc, data); if (unlikely(error)) { /* * Handle errors according to the type of * writeback. There's no need to continue for * background writeback. Just push done_index * past this page so media errors won't choke * writeout for the entire file. For integrity * writeback, we must process the entire dirty * set regardless of errors because the fs may * still have state to clear for each page. In * that case we continue processing and return * the first error. */ if (error == AOP_WRITEPAGE_ACTIVATE) { unlock_page(page); error = 0; } else if (wbc->sync_mode != WB_SYNC_ALL) { ret = error; done_index = page->index + 1; done = 1; break; } if (!ret) ret = error; } /* * We stop writing back only if we are not doing * integrity sync. In case of integrity sync we have to * keep going until we have written all the pages * we tagged for writeback prior to entering this loop. */ if (--wbc->nr_to_write <= 0 && wbc->sync_mode == WB_SYNC_NONE) { done = 1; break; } } pagevec_release(&pvec); cond_resched(); } /* * If we hit the last page and there is more work to be done: wrap * back the index back to the start of the file for the next * time we are called. */ if (wbc->range_cyclic && !done) done_index = 0; if (wbc->range_cyclic || (range_whole && wbc->nr_to_write > 0)) mapping->writeback_index = done_index; return ret; }
write_cache_pages関数では、それぞれのページキャッシュに対して、次のような処理を実施していく。
- ページキャッシュをロックを取得する
- 引数の
writepage(__mpage_writepage関数)を呼び出す - ページキャッシュのロックを解放する
そのために、pagevec_lookup_range_tag関数からPAGECACHE_TAG_DIRTY(tag)を検索していき、pvec(pagevec構造体)で管理する。
検索して得られたページがDirtyフラグが立っていない、Writebackフラグが立っている場合には、continu_unlockラベル (ロック解放して次のページを移る) にジャンプする。
__mpage_writepage関数
__mpage_writepage関数の定義は次の通りとなっている。
// 478: static int __mpage_writepage(struct page *page, struct writeback_control *wbc, void *data) { struct mpage_data *mpd = data; struct bio *bio = mpd->bio; struct address_space *mapping = page->mapping; struct inode *inode = page->mapping->host; const unsigned blkbits = inode->i_blkbits; unsigned long end_index; const unsigned blocks_per_page = PAGE_SIZE >> blkbits; sector_t last_block; sector_t block_in_file; sector_t blocks[MAX_BUF_PER_PAGE]; unsigned page_block; unsigned first_unmapped = blocks_per_page; struct block_device *bdev = NULL; int boundary = 0; sector_t boundary_block = 0; struct block_device *boundary_bdev = NULL; int length; struct buffer_head map_bh; loff_t i_size = i_size_read(inode); int ret = 0; int op_flags = wbc_to_write_flags(wbc); if (page_has_buffers(page)) { struct buffer_head *head = page_buffers(page); struct buffer_head *bh = head; /* If they're all mapped and dirty, do it */ page_block = 0; do { BUG_ON(buffer_locked(bh)); if (!buffer_mapped(bh)) { /* * unmapped dirty buffers are created by * __set_page_dirty_buffers -> mmapped data */ if (buffer_dirty(bh)) goto confused; if (first_unmapped == blocks_per_page) first_unmapped = page_block; continue; } if (first_unmapped != blocks_per_page) goto confused; /* hole -> non-hole */ if (!buffer_dirty(bh) || !buffer_uptodate(bh)) goto confused; if (page_block) { if (bh->b_blocknr != blocks[page_block-1] + 1) goto confused; } blocks[page_block++] = bh->b_blocknr; boundary = buffer_boundary(bh); if (boundary) { boundary_block = bh->b_blocknr; boundary_bdev = bh->b_bdev; } bdev = bh->b_bdev; } while ((bh = bh->b_this_page) != head); if (first_unmapped) goto page_is_mapped; /* * Page has buffers, but they are all unmapped. The page was * created by pagein or read over a hole which was handled by * block_read_full_page(). If this address_space is also * using mpage_readahead then this can rarely happen. */ goto confused; } /* * The page has no buffers: map it to disk */ BUG_ON(!PageUptodate(page)); block_in_file = (sector_t)page->index << (PAGE_SHIFT - blkbits); last_block = (i_size - 1) >> blkbits; map_bh.b_page = page; for (page_block = 0; page_block < blocks_per_page; ) { map_bh.b_state = 0; map_bh.b_size = 1 << blkbits; if (mpd->get_block(inode, block_in_file, &map_bh, 1)) goto confused; if (buffer_new(&map_bh)) clean_bdev_bh_alias(&map_bh); if (buffer_boundary(&map_bh)) { boundary_block = map_bh.b_blocknr; boundary_bdev = map_bh.b_bdev; } if (page_block) { if (map_bh.b_blocknr != blocks[page_block-1] + 1) goto confused; } blocks[page_block++] = map_bh.b_blocknr; boundary = buffer_boundary(&map_bh); bdev = map_bh.b_bdev; if (block_in_file == last_block) break; block_in_file++; } BUG_ON(page_block == 0); first_unmapped = page_block; page_is_mapped: end_index = i_size >> PAGE_SHIFT; if (page->index >= end_index) { /* * The page straddles i_size. It must be zeroed out on each * and every writepage invocation because it may be mmapped. * "A file is mapped in multiples of the page size. For a file * that is not a multiple of the page size, the remaining memory * is zeroed when mapped, and writes to that region are not * written out to the file." */ unsigned offset = i_size & (PAGE_SIZE - 1); if (page->index > end_index || !offset) goto confused; zero_user_segment(page, offset, PAGE_SIZE); } /* * This page will go to BIO. Do we need to send this BIO off first? */ if (bio && mpd->last_block_in_bio != blocks[0] - 1) bio = mpage_bio_submit(REQ_OP_WRITE, op_flags, bio); alloc_new: if (bio == NULL) { if (first_unmapped == blocks_per_page) { if (!bdev_write_page(bdev, blocks[0] << (blkbits - 9), page, wbc)) goto out; } bio = mpage_alloc(bdev, blocks[0] << (blkbits - 9), BIO_MAX_VECS, GFP_NOFS|__GFP_HIGH); if (bio == NULL) goto confused; wbc_init_bio(wbc, bio); bio->bi_write_hint = inode->i_write_hint; } /* * Must try to add the page before marking the buffer clean or * the confused fail path above (OOM) will be very confused when * it finds all bh marked clean (i.e. it will not write anything) */ wbc_account_cgroup_owner(wbc, page, PAGE_SIZE); length = first_unmapped << blkbits; if (bio_add_page(bio, page, length, 0) < length) { bio = mpage_bio_submit(REQ_OP_WRITE, op_flags, bio); goto alloc_new; } clean_buffers(page, first_unmapped); BUG_ON(PageWriteback(page)); set_page_writeback(page); unlock_page(page); if (boundary || (first_unmapped != blocks_per_page)) { bio = mpage_bio_submit(REQ_OP_WRITE, op_flags, bio); if (boundary_block) { write_boundary_block(boundary_bdev, boundary_block, 1 << blkbits); } } else { mpd->last_block_in_bio = blocks[blocks_per_page - 1]; } goto out; confused: if (bio) bio = mpage_bio_submit(REQ_OP_WRITE, op_flags, bio); if (mpd->use_writepage) { ret = mapping->a_ops->writepage(page, wbc); } else { ret = -EAGAIN; goto out; } /* * The caller has a ref on the inode, so *mapping is stable */ mapping_set_error(mapping, ret); out: mpd->bio = bio; return ret; }
__mpage_writepage関数は、該当ページが連続しているかどうかを考慮しつつ、bioを準備する関数となっている。
連続している場合 (かつ、ページキャッシュ内のデータがすべて書き込み対象である) には、それに対応するbioを生成する。

一方で、連続していない場合には、連続しているブロックのみのbioを発行し、残りのブロックのためのbioを生成する。
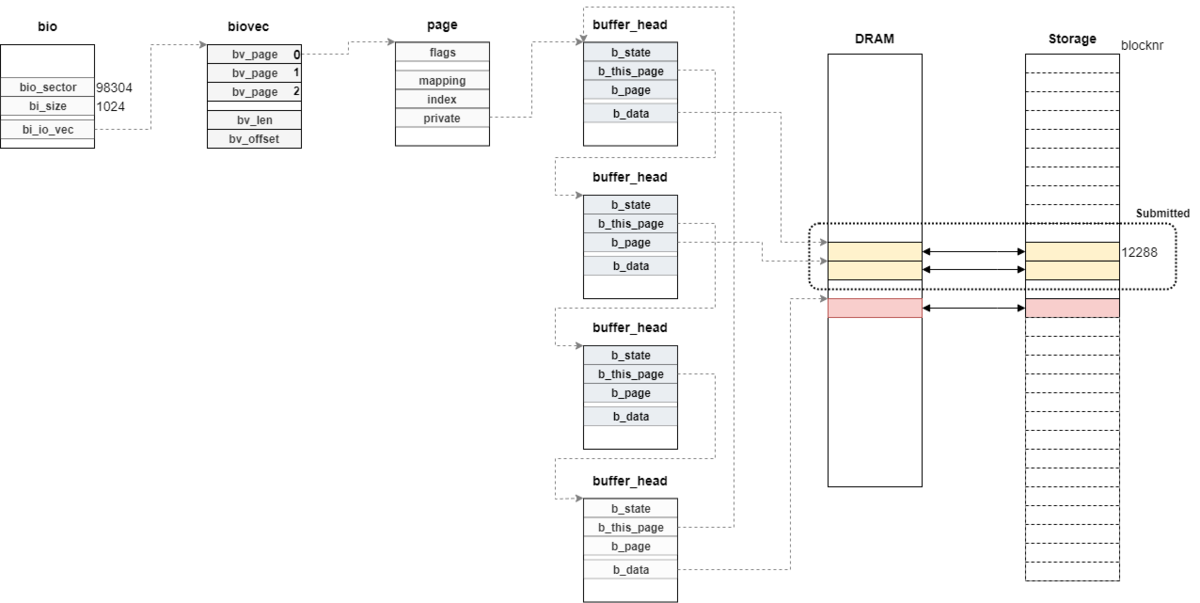
これらを踏まえて、ソースコード上の動作も確認する。

__mpage_writepage関数は、それぞれの状態に応じてラベルにジャンプしたり条件分岐することで多数の状態に対応している。
page_is_mapped
ページキャッシュが記憶装置のブロックとマッピングされている場合の処理となる。

- ページキャッシュに載っている書き込み対象でない範囲のゼロ埋めを実施する。
- 非連続となっているブロックの
bioを発行する
ページキャッシュをゼロ埋めをする処理はzero_user_segment関数が担う。
// 222: static inline void zero_user_segment(struct page *page, unsigned start, unsigned end) { zero_user_segments(page, start, end, 0, 0); }
zero_user_segment関数は、zero_user_segments関数のラッパ関数となっている。
// 201: static inline void zero_user_segments(struct page *page, unsigned start1, unsigned end1, unsigned start2, unsigned end2) { void *kaddr = kmap_atomic(page); unsigned int i; BUG_ON(end1 > page_size(page) || end2 > page_size(page)); if (end1 > start1) memset(kaddr + start1, 0, end1 - start1); if (end2 > start2) memset(kaddr + start2, 0, end2 - start2); kunmap_atomic(kaddr); for (i = 0; i < compound_nr(page); i++) flush_dcache_page(page + i); }
kunmap_ztomic関数やflush_dcache_page関数は、以前の記事 (write_iter) と同様である。
alloc_new
mmcドライバではできないので詳細は割愛するが、bdev_write_page関数によってページキャッシュによる書き込みができるドライバであれば、実施して終了する。
// 357: int bdev_write_page(struct block_device *bdev, sector_t sector, struct page *page, struct writeback_control *wbc) { int result; const struct block_device_operations *ops = bdev->bd_disk->fops; if (!ops->rw_page || bdev_get_integrity(bdev)) return -EOPNOTSUPP; result = blk_queue_enter(bdev->bd_disk->queue, 0); if (result) return result; set_page_writeback(page); result = ops->rw_page(bdev, sector + get_start_sect(bdev), page, REQ_OP_WRITE); if (result) { end_page_writeback(page); } else { clean_page_buffers(page); unlock_page(page); } blk_queue_exit(bdev->bd_disk->queue); return result; }
ちなみに、Linux v5.10現在で対応しているのは次の3種類のみとなっている。
- zram
- brd
- nvdimm
そうではない場合には、mpage_alloc関数によってbioを生成し、書き込み対象をbiovecに追加する処理となる。
// 71: static struct bio * mpage_alloc(struct block_device *bdev, sector_t first_sector, int nr_vecs, gfp_t gfp_flags) { struct bio *bio; /* Restrict the given (page cache) mask for slab allocations */ gfp_flags &= GFP_KERNEL; bio = bio_alloc(gfp_flags, nr_vecs); if (bio == NULL && (current->flags & PF_MEMALLOC)) { while (!bio && (nr_vecs /= 2)) bio = bio_alloc(gfp_flags, nr_vecs); } if (bio) { bio_set_dev(bio, bdev); bio->bi_iter.bi_sector = first_sector; } return bio; }
mpage_alloc関数は、bioの生成するためにbio_alloc関数を呼び出す。
// 442: static inline struct bio *bio_alloc(gfp_t gfp_mask, unsigned int nr_iovecs) { return bio_alloc_bioset(gfp_mask, nr_iovecs, &fs_bio_set); }
bioの生成には、bio_alloc_bioset関数と呼ばれるAPIを実行する。(詳細は割愛)
その後、新規に生成したbioに対して、IO対象となるページキャッシュを追加する。

bioをマージできる条件として次のようなものがある。
- ページキャッシュが同じ場合
- 書き込み先が連続している場合
// 1004: int bio_add_page(struct bio *bio, struct page *page, unsigned int len, unsigned int offset) { bool same_page = false; if (!__bio_try_merge_page(bio, page, len, offset, &same_page)) { if (bio_full(bio, len)) return 0; __bio_add_page(bio, page, len, offset); } return len; }
これらの場合には、__bio_try_merge_page関数でbioのマージ (bv_lenとbi_sizeの更新) を試みる。
confused
生成できているだけのbioを発行する。
mpage_bio_submit関数
mpage_bio_submit関数
// 61: static struct bio *mpage_bio_submit(int op, int op_flags, struct bio *bio) { bio->bi_end_io = mpage_end_io; bio_set_op_attrs(bio, op, op_flags); guard_bio_eod(bio); submit_bio(bio); return NULL; }
bi_end_ioはI/Oが完了時に呼び出すハンドラとなっている。(詳細は別記事)
bio_set_op_attrs関数は、bio構造体のbi_opfにフラグを設定する
// 438: static inline void bio_set_op_attrs(struct bio *bio, unsigned op, unsigned op_flags) { bio->bi_opf = op | op_flags; }
今回のケースでは、op_flagsはwbc_to_write_flags関数によって更新される。
//97: static inline int wbc_to_write_flags(struct writeback_control *wbc) { int flags = 0; if (wbc->punt_to_cgroup) flags = REQ_CGROUP_PUNT; if (wbc->sync_mode == WB_SYNC_ALL) flags |= REQ_SYNC; else if (wbc->for_kupdate || wbc->for_background) flags |= REQ_BACKGROUND; return flags; }
| 変数名 | wb_check_start_all | wb_check_old_data_flush | wb_check_background_flush |
|---|---|---|---|
| sync_mode | WB_SYNC_NONE | WB_SYNC_NONE | WB_SYNC_NONE |
| for_kupdate | 0 | 1 | 0 |
| for_background | 0 | 0 | 1 |
wb_check_old_data_flush関数やwb_check_background_flush関数の場合には、REQ_BACKGROUNDが付与される。
// 600: void guard_bio_eod(struct bio *bio) { sector_t maxsector = bdev_nr_sectors(bio->bi_bdev); if (!maxsector) return; /* * If the *whole* IO is past the end of the device, * let it through, and the IO layer will turn it into * an EIO. */ if (unlikely(bio->bi_iter.bi_sector >= maxsector)) return; maxsector -= bio->bi_iter.bi_sector; if (likely((bio->bi_iter.bi_size >> 9) <= maxsector)) return; bio_truncate(bio, maxsector << 9); }
また、bioの書き込み範囲がブロックデバイスを超えている場合、guard_bio_eod関数により切り詰める。
こうして得られたbioをsubmit_bio関数を実行して、IOを発行する。
おわりに
本記事では、ext2ファイルシステムのwritepages操作 (ext2_writepages)を解説した。
今回の環境でext2_writepages関数を実行することで、次のようなbio構造体が生成された。

変更履歴
- 2022/05/01: 記事公開
- 2022/06/13: 動作後のイメージ図の追加
- 2022/09/19: カーネルバージョンを5.15に変更
参考
- mpage_writepages() - Linuxカーネルメモ
- writepage関数の実装に関するメモ
- Driver porting: the BIO structure [LWN.net]
- BIO構造体について
- 第65章 ブロック I/O ( bio )
- biovecとページの関係