関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、vfs_write関数から各ファイルシステムが定義しているwriteまたはwrite_iterを呼ぶところまでを確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
本記事では、VFSレイヤを対象に解説を始める。
処理シーケンス図としては、下記の赤枠部分が該当する。
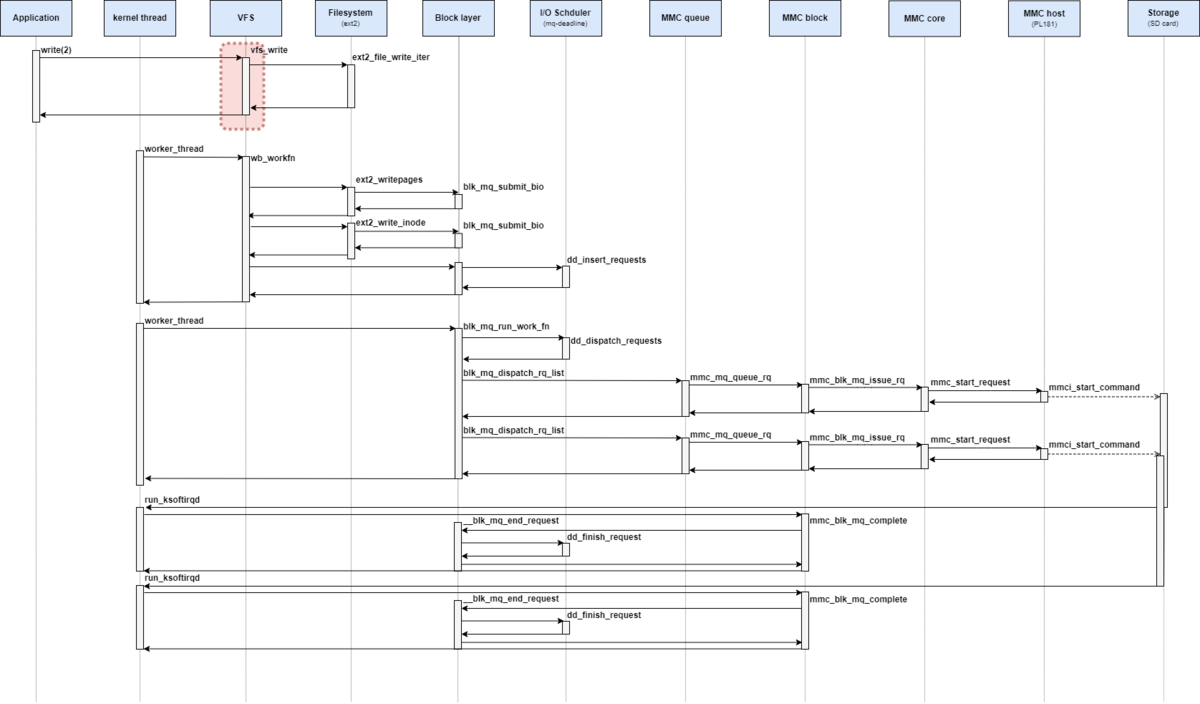
VFSレイヤの概要
LinuxはVFSレイヤで以下のようなオブジェクトを利用する。
file: openシステムコールでユーザプログラムが操作できるようになったファイルpath: マウントポイントとdentrydentry: ファイル名とinodeの対応関係inode: ファイルのメタデータaddress_space:inodeとページキャッシュの対応関係super_block: ファイルシステム全般に関する情報
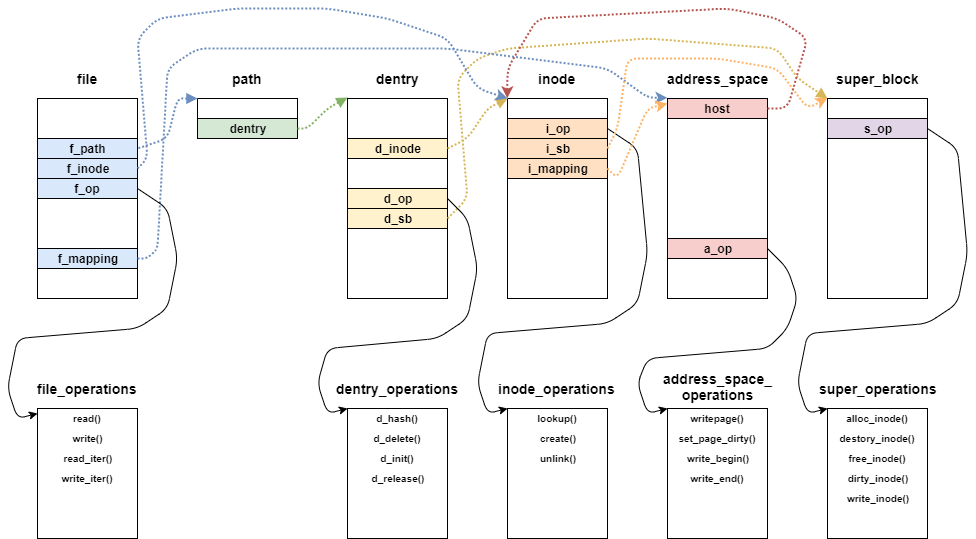
ファイルシステムは上記のoperations関数を固有で定義することで、それぞれのファイルシステムで違う操作を実現している。
これを踏まえて、前回からの続きのvfs_write関数を追いかける。
VFSレイヤはvfs_で始まる関数で定義される。
writeシステムコールの場合はvfs_write関数が該当する。
// 574: ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos) { ssize_t ret; if (!(file->f_mode & FMODE_WRITE)) return -EBADF; if (!(file->f_mode & FMODE_CAN_WRITE)) return -EINVAL; if (unlikely(!access_ok(buf, count))) return -EFAULT; ret = rw_verify_area(WRITE, file, pos, count); if (ret) return ret; if (count > MAX_RW_COUNT) count = MAX_RW_COUNT; file_start_write(file); if (file->f_op->write) ret = file->f_op->write(file, buf, count, pos); else if (file->f_op->write_iter) ret = new_sync_write(file, buf, count, pos); else ret = -EINVAL; if (ret > 0) { fsnotify_modify(file); add_wchar(current, ret); } inc_syscw(current); file_end_write(file); return ret; }
vfs_write関数では、大きく分けて下記の三つを実施する。
- アクセスするデータの領域の正当性確認
- ファイルシステムのwrite操作を実行する
- 書き込みが発生したことを監視中のユーザプログラムに通知する
それぞれの挙動について、以降の節で解説する。
アクセスするデータ領域の確認
vfs_write関数の下記の部分に該当する。
// 578: if (!(file->f_mode & FMODE_WRITE)) return -EBADF; if (!(file->f_mode & FMODE_CAN_WRITE)) return -EINVAL; if (unlikely(!access_ok(buf, count))) return -EFAULT; ret = rw_verify_area(WRITE, file, pos, count); if (ret) return ret; if (count > MAX_RW_COUNT) count = MAX_RW_COUNT;
ここでは、下記のような処理をする。
- ファイルがREADモード(
openシステムコールでO_RDONLYを指定) の場合は-EBADFを返す - ファイルシステムがwrite操作をサポートしていない場合は
-EINVALを返す - 書き込み先のアドレスを確認して、不適切であれば
-EFAULTを返す - ファイルが強制ロックがかけられている場合はエラー番号を返す
- 書き込むデータの長さが長い場合には一定サイズに切り詰める
READモードのチェックとwrite操作をサポートしていない場合に関しては、明解であるので説明を省略する。
同様に、サイズを切り詰める処理も省略する。
書き込み先のアドレスを確認する
access_okマクロで、writeシステムコールの引数の書き込み先アドレスを確認する。
このマクロは書き込み先のアドレスと書き込み対象の長さを引数にとる。
ちなみに、access_okはアーキテクチャによって処理が異なるので注意が必要である。
// 251: #define access_ok(addr, size) (__range_ok(addr, size) == 0)
__range_okマクロはCONFIG_MMUに依存しており、このコンフィグが無効の場合はなにもしない。
コンフィグが有効の場合、下記のマクロが実行される。
// 62: #define __range_ok(addr, size) ({ \ unsigned long flag, roksum; \ __chk_user_ptr(addr); \ __asm__(".syntax unified\n" \ "adds %1, %2, %3; sbcscc %1, %1, %0; movcc %0, #0" \ : "=&r" (flag), "=&r" (roksum) \ : "r" (addr), "Ir" (size), "0" (TASK_SIZE) \ : "cc"); \ flag; })
まずは、__chk_user_ptrマクロに着目する。
// 7: #ifdef __CHECKER__ /* address spaces */ # define __kernel __attribute__((address_space(0))) # define __user __attribute__((noderef, address_space(__user))) # define __iomem __attribute__((noderef, address_space(__iomem))) # define __percpu __attribute__((noderef, address_space(__percpu))) # define __rcu __attribute__((noderef, address_space(__rcu))) static inline void __chk_user_ptr(const volatile void __user *ptr) { }
// 29: #else /* __CHECKER__ */ /* address spaces */ # define __kernel # ifdef STRUCTLEAK_PLUGIN # define __user __attribute__((user)) # else # define __user # endif # define __iomem # define __percpu # define __rcu # define __chk_user_ptr(x) (void)0 # define __chk_io_ptr(x) (void)0
__chk_user_ptrマクロは、__CHECKER__が偽の場合に、(void)0を返す。
これはコンパイル時、インラインの
access_okの引数が__userとなっているかのチェック故かと思います。 https://wiki.bit-hive.com/north/pg/access_ok
次にインラインアセンブラについて着目する。 インラインアセンブラ命令を展開すると下記のようなコードとなり、そのときの入力と出力が下記の表のようになっている。
// 65: .syntax unified adds %1, %2, %3 sbcscc %1, %1, %0 movcc %0, #0
| 名称 | レジスタ | 対応するデータ | コードとの対応関係 |
|---|---|---|---|
| 出力オペランド | 汎用レジスタ | flag |
%0 |
| 汎用レジスタ | roksum |
%1 |
|
| 入力オペランド | 汎用レジスタ | addr |
%2 |
| リンクレジスタ | size |
%3 |
|
| 出力オペランド0で割り当てたレジスタ | TASK_SIZE |
%0 |
|
| 破壊レジスタ | 条件レジスタ | N/A | N/A |
これらを基にCプログラムのような形に書き起こしてみると、下記のようになる。
unsigned long __range_ok(const char __user *addr, size_t size) { unsigned long flag, roksum; __chk_user_ptr(addr); roksum = addr + size; roksum = roksum - TASK_SIZE; if (roksum < 0) flag = 1; return flag; }
つまり、__range_okインライン関数では、addr + sizeがTASK_SIZE以内であるかどうかを確認する処理である。
ちなみに、.syntax unifiedは、「ARM命令 と THUMB命令 を統一した書式で記述する」となっている。
.syntax unifiedは、「ARM命令 と THUMB命令 を統一した書式で記述する https://jhalfmoon.com/dbc/2019/09/27/%E3%81%90%E3%81%A0%E3%81%90%E3%81%A0%E4%BD%8E%E3%83%AC%E3%83%99%E3%83%AB%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9F%E3%83%B3%E3%82%B07-syntax-%E3%82%B3%E3%83%A1%E3%83%B3%E3%83%88%E3%80%81/
そして、TASK_SIZEは下記の定義となっている。
// 38: #ifndef CONFIG_KASAN #define TASK_SIZE (UL(CONFIG_PAGE_OFFSET) - UL(SZ_16M)) #else #define TASK_SIZE (KASAN_SHADOW_START) #endif
TASK_SIZEは、ユーザプロセスの最大サイズとなっており、The Kernel Address Sanitizer (KASAN) の機能が定義されているかどうかで値が異なる。
CONFIG_KASAN=yの場合は、TASK_SIZEはshadow addressの開始アドレスとなる。
https://lists.cs.columbia.edu/pipermail/kvmarm/2020-January/038743.html
CONFIG_KASAN=nの場合は、CONFIG_PAGE_OFFSET - SZ_16M がTASK_SIZEとなる。
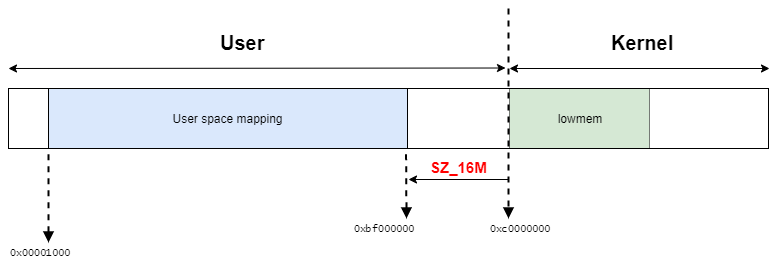
つまり、__range_okマクロは、引数として渡されたアドレスがUser space mapping領域の範囲内かどうかを確認する。

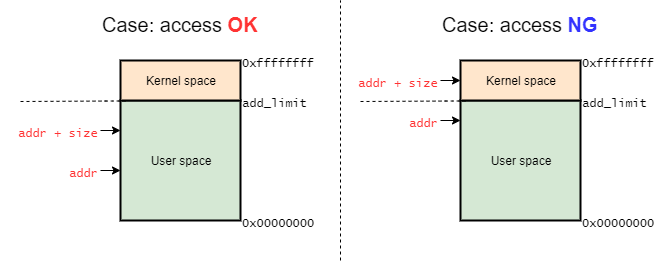
参照先のアドレスに範囲内であれば、rw_verify_area関数によって書き込み先の検証をする。
rw_verify_area関数の定義は次の通りとなっている。
// 366: int rw_verify_area(int read_write, struct file *file, const loff_t *ppos, size_t count) { if (unlikely((ssize_t) count < 0)) return -EINVAL; /* * ranged mandatory locking does not apply to streams - it makes sense * only for files where position has a meaning. */ if (ppos) { loff_t pos = *ppos; if (unlikely(pos < 0)) { if (!unsigned_offsets(file)) return -EINVAL; if (count >= -pos) /* both values are in 0..LLONG_MAX */ return -EOVERFLOW; } else if (unlikely((loff_t) (pos + count) < 0)) { if (!unsigned_offsets(file)) return -EINVAL; } } return security_file_permission(file, read_write == READ ? MAY_READ : MAY_WRITE); }
rw_verify_area関数で検証する内容は次の通りとなっている。
countの値が0以上であることFMODE_UNSIGNED_OFFSETフラグが立っていないならば、posの値が0以上であること- また、
posの絶対値がcountを上回っていないこと
- また、
FMODE_UNSIGNED_OFFSETフラグが立っていないならば、pos + countの値が0以上であること- Linux Security Module (LSM) が設定されているばらば、書き込み権限があること
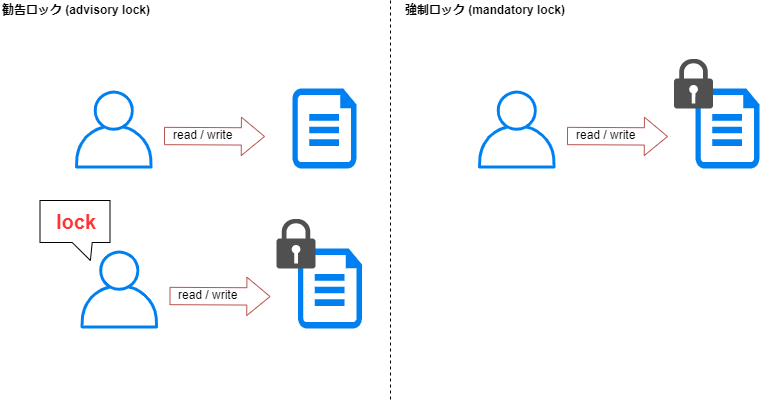
ファイルシステムのwrite操作を実行する
vfs_write関数の下記の部分に該当する。
// 590: file_start_write(file); if (file->f_op->write) ret = file->f_op->write(file, buf, count, pos); else if (file->f_op->write_iter) ret = new_sync_write(file, buf, count, pos); else ret = -EINVAL;
// 602: file_end_write(file);
ここでは、下記のような処理をする。
- super_blockにDirtyリストを更新することを通知する
- ファイルシステム固有のwrite処理を実行する
- super_blockにDirtyリストを更新終了したことを通知する
super_blockにファイル更新があることを通知する
アクセスするデータ領域の確認し問題がないと判断できた場合、対応するファイルシステムのwrite処理を実行する。
ただし、write処理の前後にfile_start_write関数とfile_end_write関数を実行しなければならない。
下記はfile_start_write関数を示している。
// 3004: static inline void file_start_write(struct file *file) { if (!S_ISREG(file_inode(file)->i_mode)) return; sb_start_write(file_inode(file)->i_sb); }
通常ファイル以外の場合はこの処理は実行されず、通常ファイルの場合はsuper_blockにファイル書き込みを通知する必要がある。
// 1880: static inline void sb_start_write(struct super_block *sb) { __sb_start_write(sb, SB_FREEZE_WRITE); }
ファイル書き込みの場合は、SB_FREEZE_WRITEとして通知する。
super_blockに通知する関数には複数のレベルを用意しており、Page faultsの場合などがある。
// 1810: static inline void __sb_start_write(struct super_block *sb, int level) { percpu_down_read(sb->s_writers.rw_sem + level - 1); }
この結果、super_blockに存在するセマフォを獲得することになる。 ちなみにこの処理は、fsfreeze(8)やioctl経由でファイルシステムを凍結させることができる処理を大きく関係している。
通常、Linuxではwrite処理はライトバックとなり、一定間隔毎に記憶装置にフラッシュする。
その際に、super_blockはライトバックが必要なファイルの一覧をリストとして管理している。
下記はその様子を表しており、このリストはwriteなどの処理によって更新される。
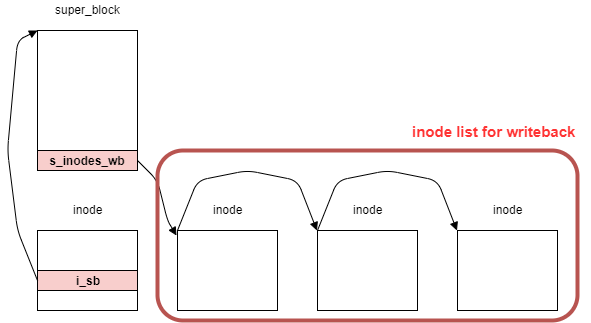
一方で、file_end_write関数はこれとは対になる処理で、リストの更新が終わったためセマフォを解放している。
// 3018: static inline void file_end_write(struct file *file) { if (!S_ISREG(file_inode(file)->i_mode)) return; __sb_end_write(file_inode(file)->i_sb, SB_FREEZE_WRITE); }
// 1805: static inline void __sb_end_write(struct super_block *sb, int level) { percpu_up_read(sb->s_writers.rw_sem + level-1); }
ファイルシステム固有のwrite処理を実行する
それぞれのファイルシステムは、writeとwrite_iter処理を定義することができる。
write: bufferで書き込み先を指定するwrite_iter:iov_iterで書き込み先を指定する
これを踏まえて、vfs_write関数を確認する。
// 591: if (file->f_op->write) ret = file->f_op->write(file, buf, count, pos); else if (file->f_op->write_iter) ret = new_sync_write(file, buf, count, pos); else ret = -EINVAL;
ユーザプログラムがwrite処理が実行すると、ファイルシステム固有のwrite処理またはwrite_iterを実行する。
- 両方とも定義されている場合:
write処理を実行する - 片方のみ定義されている場合: 定義されている方を実行する
- 両方とも定義されていない場合:
-EINVALを返す
まずは、write処理が定義されている場合を考える。
write処理の場合、「ユーザ空間にある書き込み対象のデータのあるアドレス」、「file構造体」、「書き込み対象のデータの長さ」の3つを引数とする。
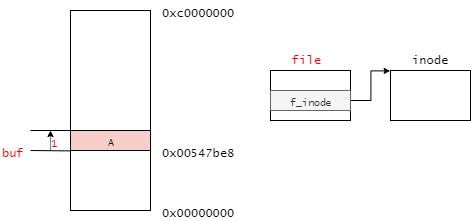
次に、write_iter処理のみ定義されている場合を考える。
write_iter処理の場合、new_sync_write関数を呼び出し、引数に渡すstruct kiocbとstruct iov_iterの設定をする。
// 496: static ssize_t new_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos) { struct iovec iov = { .iov_base = (void __user *)buf, .iov_len = len }; struct kiocb kiocb; struct iov_iter iter; ssize_t ret; init_sync_kiocb(&kiocb, filp); kiocb.ki_pos = (ppos ? *ppos : 0); iov_iter_init(&iter, WRITE, &iov, 1, len); ret = call_write_iter(filp, &kiocb, &iter); BUG_ON(ret == -EIOCBQUEUED); if (ret > 0 && ppos) *ppos = kiocb.ki_pos; return ret; }
まずは、それぞれのデータ構造がどのようにつながっているのかを下記に示す。(赤字の値は例である)
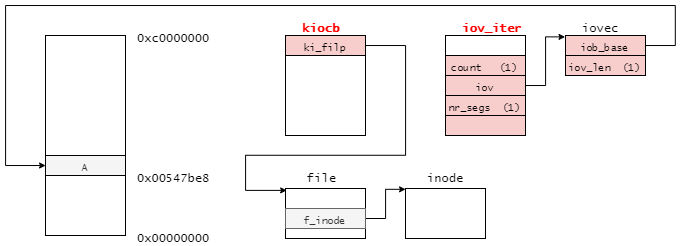
struct iovec(IO vector): 書き込み対象のデータに関する情報を格納する- 「ユーザ空間のデータのアドレス」と「書き込み対象のデータの長さ」を持つ
struct kiocb(kernel IO control block?): 書き込み時に必要となるメタ情報を格納する- 「
file構造体へのポインタ」や「オープンの時に指定したフラグ(の一部)」などを持つ
- 「
struct iov_iter(IO vector iterator?): 複数の書き込み対象のデータに関する情報を管理する- 「
iovec(など)構造体のポインタ」や「iovec構造体をいくつ管理しているか」、「データの合計の長さ」などの情報を持つ
- 「
これらをまとめると、今回はこれらの構造体に下記のようなパラメータが設定される。
| 構造体名 | メンバ名 | 値 |
|---|---|---|
| iovec | iov_base | ユーザ空間のバッファへのポインタ |
| iov_len | 6 |
|
| kiocb | ki_filp | 対応するファイルのファイル構造体へのポインタ |
| ki_pos | 0 |
|
| ki_complete | 0 |
|
| private | 0 |
|
| ki_flags | IOCB_APPEND |
|
| ki_hint | WRITE_LIFE_NOT_SET |
|
| ki_ioprio | 0 |
|
| iov_iter | type | WRITE | ITER_IOVEC |
| data_source | true |
|
| iov_offset | 0 |
|
| count | 6 |
|
| iovec | iovec構造体へのポインタ | |
| nr_segs | 1 |
|
| head | 1 |
|
| start_head | 0 |
|
| xattar_start | 1 |
init_syc_kiocb関数はkiocb構造体を設定し、 iov_iter_init関数はiov_iter構造体を設定する。
ここでは、これらの関数の詳細については解説しない。下記はそれらの関数である。
// 2325: static inline void init_sync_kiocb(struct kiocb *kiocb, struct file *filp) { *kiocb = (struct kiocb) { .ki_filp = filp, .ki_flags = iocb_flags(filp), .ki_hint = ki_hint_validate(file_write_hint(filp)), .ki_ioprio = get_current_ioprio(), }; }
// 463: void iov_iter_init(struct iov_iter *i, unsigned int direction, const struct iovec *iov, unsigned long nr_segs, size_t count) { WARN_ON(direction & ~(READ | WRITE)); *i = (struct iov_iter) { .iter_type = ITER_IOVEC, .data_source = direction, .iov = iov, .nr_segs = nr_segs, .iov_offset = 0, .count = count }; } EXPORT_SYMBOL(iov_iter_init);
これらの構造体の設定した後に、call_write_iter関数によりファイルシステム固有のwrite_iter処理を実行する。
// 2160: static inline ssize_t call_write_iter(struct file *file, struct kiocb *kio, struct iov_iter *iter) { return file->f_op->write_iter(kio, iter); }
write_iter処理を実行した後、オフセットが移動した場合には更新をしてから終了する。
監視中のユーザプログラムにイベントを通知する
vfs_write関数の下記の部分に該当する。
// 597: if (ret > 0) { fsnotify_modify(file); add_wchar(current, ret); } inc_syscw(current);
Linuxでは、ファイルへの書き込み (≠ ストレージへの書き出し) に関する情報をユーザプロセスに通知することができる。
ここでは、二つの通知の手法について説明する。
- Taskstats
- fsnotify
taskstats
taskstats はカーネルからユーザ空間のプロセスにタスクの統計情報やプロセスの統計情報を送信するためのインターフェイスである。
CONFIG_TASK_XACCTが有効の場合、Taskstatsで取得できる項目に「writeシステムコールを実行した回数」と「書き込みした総バイト数」が追加される。
// 11: #ifdef CONFIG_TASK_XACCT static inline void add_rchar(struct task_struct *tsk, ssize_t amt) { tsk->ioac.rchar += amt; } static inline void add_wchar(struct task_struct *tsk, ssize_t amt) { tsk->ioac.wchar += amt; } static inline void inc_syscr(struct task_struct *tsk) { tsk->ioac.syscr++; } static inline void inc_syscw(struct task_struct *tsk) { tsk->ioac.syscw++; }
そのため、vfs_write関数で書き込みが終了したタイミングで、add_wchar関数とinc_syscw関数を呼び出して統計情報の更新をする。
ちなみに、CONFIG_TASK_XACCTが無効の場合は、何も実行されない。
// 31: #else static inline void add_rchar(struct task_struct *tsk, ssize_t amt) { } static inline void add_wchar(struct task_struct *tsk, ssize_t amt) { } static inline void inc_syscr(struct task_struct *tsk) { } static inline void inc_syscw(struct task_struct *tsk) { } #endif
taskstasについては、カーネルドキュメントに詳細な説明が記載されているので、そちらを要参照。
fsnotify
fsnotifyは、ファイルシステム上でのイベント通知機構のバックエンドとなる機構である。
fsnotifyは、dnotify, inotify, fanotifyなどの通知機構のための基盤となっている。
- dnotify: ディレクトリの状態変化を通知する機構。のちにinotifyに取って代わる。
- inotify: ファイルの状態変化を通知する機構。
- fanotity: ファイルシステムの状態変化を通知する機能。
これらの機構の特徴をまとめると下記のようになる。
| 項目 | dnotify | inotify | fanotify |
|---|---|---|---|
| 権限 | ユーザー権限 | ユーザー権限 | 要root権限 |
| 監視範囲 | ディレクトリ | ファイル | マウントポイント |
| ツール | - | https://github.com/inotify-tools/inotify-tools | - |
| 制約 | リムーバルメディア非対応 | アクセス許可の判定は不可能 | create、delete、moveに関するイベントがサポートされていない |
これらの機構について詳しく知りたいのであれば、下記のサイトを拝見することを推奨する。
https://blog.1mg.org/20190803_01/blog.1mg.org
これらを踏まえると、vfs_write関数で書き込みが終了したタイミングで、fsnotify_modify関数によりイベントを(必要に応じて)通知させる必要がある。
fsnotifyの仕組みについてソースコードを追いかけるとなると膨大になってしまうので、ここでは説明を省略する。
下記に、一部のみ掲載してあるが、やっていることはファイルに変更があったことを(必要に応じて)通知する処理である。
// 262: static inline void fsnotify_modify(struct file *file) { fsnotify_file(file, FS_MODIFY); }
// 92: static inline int fsnotify_file(struct file *file, __u32 mask) { const struct path *path = &file->f_path; if (file->f_mode & FMODE_NONOTIFY) return 0; return fsnotify_parent(path->dentry, mask, path, FSNOTIFY_EVENT_PATH); }
おわりに
本記事では、VFS(vfs_write関数)からファイルシステム固有のwrite(またはwrite_iter操作)を呼び出すまでを解説した。次回の記事で、ファイルシステム固有のwrite_iter操作を解説したいと思う。
変更履歴
参考
- 割り込みの後半部、ファイルシステム
- .syntax, コメント、ローカルラベル | デバイスビジネス開拓団
- 低レベルプログラミング (ARM命令とか解説)
- arm-inline-asm - Linuxメモ(跡地)
- インラインアセンブラの英文章を翻訳したもの
- http://caspar.hazymoon.jp/OpenBSD/annex/gcc_inline_asm.html
- インラインアセンブラの書き方について (オペランドの制約とか規則の解説がメイン)
- GCC拡張インラインアセンブラ構文 - kikairoya’s diary
- インラインアセンブラの書き方について (ただしx86)
- GCCのインラインアセンブラの書き方 for x86 - OSのようなもの
- インラインアセンブラの書き方について (ただしx86)
- currentマクロ - Linuxの備忘録とか・・・(目次へ)
- スタックポインタとプロセスの関係について
- access_ok - Linuxの備忘録とか・・・(目次へ)
- 領域がアクセス可能かどうか確認する
- Linux: 強制ロック(mandatory lock) #Python - Qiita
- ファイルの強制ロックを実施している
- O'Reilly Japan Blog - ファイルロックと新OFDロック
- ファイルのロックについて解説
- 勧告ロックと強制ロック - Linuxの備忘録とか・・・(目次へ)
- 勧告ロックと強制ロックの解説
- ファイルシステムの凍結 - Linuxの備忘録とか・・・(目次へ)
- ファイルシステムのフリーズ処理について
- Linuxのfsfreezeを調査する #Linux - Qiita
- fsfreezeについて解説
- http://delihiros.jp/#!io.md
- ファイルのIOについて解説
- https://www.ipa.go.jp/security/fy22/reports/tech1-tg/b_03.html
- fsnotifyについて簡易な説明あり
- https://blog.1mg.org/20190803_01/
- inotifyについて使い方を解説
- Linux でファイルの変更を検出する(inotify/fanotify)
- inotifyとfanotifyの違いについてまとめてある
- inotify(file change notification system)覚書-Part1 – Siguniang's Blog
- inotifyについて解説