関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- 概要
- はじめに
- write_beginの概要
- ページキャッシュを取得する
- バッファキャッシュ用のデータ構造を作成する
- バッファキャッシュを準備する
- バッファキャッシュを確保する
- 循環ループを作成する
- バッファキャッシュとファイルシステムを紐付ける
- write_begin処理内で失敗した場合
- おわりに
- 変更履歴
- 参考
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、ext2_write_begin関数を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
処理シーケンス図としては、下記の赤枠部分が該当する。
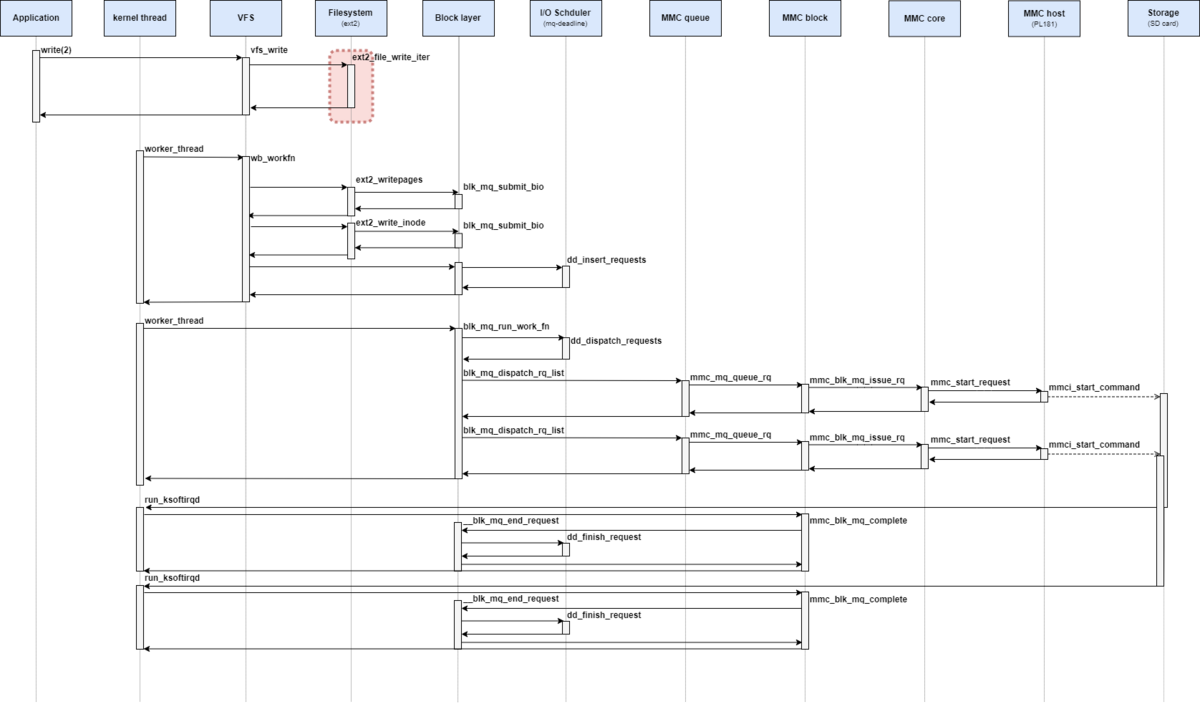
本記事では、ext2ファイルシステムのwrite_iter操作から呼び出されるwrite_begin操作を解説する。
write_beginの概要
前回解説したwrite_iter操作(generic_file_write_iter)は、write_begin操作とwrite_end操作を呼び出すことになっている。
このwrite_begin操作やwrite_end操作はページキャッシュに対する操作となっており、address_space_opearationsのメンバの一つとして定義される。
ここで、address_spaceについて再掲する。

address_spaceは、inodeとページキャッシュ(ファイルのデータ)を紐づけるデータ型となっている。
ファイルに紐づいているページキャッシュは、xarray型のi_pagesで管理される。 (バージョン4.20より前はradix treeで管理される)
詳細については、下記の記事に詳しく記載されているのでそちらを参照。
ext2ファイルシステムのaddress_space_operationsは、ext2_aops、ext2_nobh_aopsとext2_dax_aopsが定義されている。
これらは、マウントオプションnobhやdaxが指定された場合に、使用するappress_space_operationsを変更することになっている。
今回は処理が簡単なext2_aopsを用いて考えていく。
ext2_aopsの定義は下記の通り。
// 964: const struct address_space_operations ext2_aops = { .set_page_dirty = __set_page_dirty_buffers, .readpage = ext2_readpage, .readahead = ext2_readahead, .writepage = ext2_writepage, .write_begin = ext2_write_begin, .write_end = ext2_write_end, .bmap = ext2_bmap, .direct_IO = ext2_direct_IO, .writepages = ext2_writepages, .migratepage = buffer_migrate_page, .is_partially_uptodate = block_is_partially_uptodate, .error_remove_page = generic_error_remove_page, };
まずは、write_begin操作のext2_write_begin関数から確認する。
write_begin操作は、write_iter操作(で呼び出されるgeneric_perform_write関数)から呼び出される。
// 3770: status = a_ops->write_begin(file, mapping, pos, bytes, flags, &page, &fsdata);
| 変数名 | 値 |
|---|---|
| file | オープンしたファイル |
| mapping | ファイルが持っているページキャッシュのXArray(radix-tree) |
| pos | 書き込み先の位置 |
| bytes | 書き込むバイト数 |
| flags | 0 |
| page | 取得したページを格納する |
| fsdata | ext2ファイルシステムでは使用しない |
ext2ファイルシステムの場合には、write_begin操作でext2_write_begin関数を実行する。
// 884: static int ext2_write_begin(struct file *file, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata) { int ret; ret = block_write_begin(mapping, pos, len, flags, pagep, ext2_get_block); if (ret < 0) ext2_write_failed(mapping, pos + len); return ret; }
この関数では、カーネル内で定義されている汎用の関数block_write_begin関数に、ext2ファイルシステムにおけるブロック取得のext2_get_block関数(次回解説)を渡している。
// 2109: int block_write_begin(struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, get_block_t *get_block) { pgoff_t index = pos >> PAGE_SHIFT; struct page *page; int status; page = grab_cache_page_write_begin(mapping, index, flags); if (!page) return -ENOMEM; status = __block_write_begin(page, pos, len, get_block); if (unlikely(status)) { unlock_page(page); put_page(page); page = NULL; } *pagep = page; return status; }
block_write_begin関数では、下記を実施する。
- ページキャッシュを取得する
- バッファキャッシュ用のデータ構造を作成する
まずは、ページキャッシュを取得するgrab_cache_page_write_begin関数を確認する。
ページキャッシュを取得する
// 3715: /* * Find or create a page at the given pagecache position. Return the locked * page. This function is specifically for buffered writes. */ struct page *grab_cache_page_write_begin(struct address_space *mapping, pgoff_t index, unsigned flags) { struct page *page; int fgp_flags = FGP_LOCK|FGP_WRITE|FGP_CREAT; if (flags & AOP_FLAG_NOFS) fgp_flags |= FGP_NOFS; page = pagecache_get_page(mapping, index, fgp_flags, mapping_gfp_mask(mapping)); if (page) wait_for_stable_page(page); return page; } EXPORT_SYMBOL(grab_cache_page_write_begin);
grab_cache_page_write_begin関数では、下記を実施する。
- ページキャッシュを取得する
- ページキャッシュの割り当て中にアクセスされたページをフラッシュする
ただし、後者('wait_for_stable_page`関数)については、本質でない(かつ未調査である)ため説明を省略する。(該当パッチ)
まずは、ページキャッシュを取得するpagecache_get_page関数を確認する。
このとき、引数のfgp_flagsには次のような値が設定されている。
| フラグ名 | 説明 |
|---|---|
| FGP_LOCK | 得られたページをロックする |
| FGP_WRITE | ページに書き込みをする |
| FGP_CREAT | ページが見つからない場合はページを作る |
また、引数のgfp_maskには次のような値が設定されている。(実機で0x1100ccaであることを確認済み)
| パラメータ名 | 説明 |
|---|---|
| ___GFP_HIGHMEM | ZONE_HIGHMEMメモリゾーンに属するページフレームを取得する |
| ___GFP_MOVABLE | ページ圧縮中にこのページは移動可能であることを示す |
| ___GFP_IO | ページフレームを開放するためにI/O転送処置を行ってもよい |
| ___GFP_FS | ファイルシステム関連の操作を行っても良い |
| ___GFP_DIRECT_RECLAIM | メモリ確保を読んだタスクのコンテキストでメモリ回収する |
| ___GFP_KSWAPD_RECLAIM | kswapdカーネルスレッドを起動してメモリ回収できる |
| ___GFP_HARDWALL | cpusetのメモリ割り当てポリシーを強制する |
| ___GFP_SKIP_KASAN_POISON | KASANがページの割り当て解除時にポイズニングをスキップする |
pagecache_get_page関数の定義は下記のとおりである。
// 1888: struct page *pagecache_get_page(struct address_space *mapping, pgoff_t index, int fgp_flags, gfp_t gfp_mask) { struct page *page; repeat: page = mapping_get_entry(mapping, index); if (xa_is_value(page)) { if (fgp_flags & FGP_ENTRY) return page; page = NULL; } if (!page) goto no_page; if (fgp_flags & FGP_LOCK) { if (fgp_flags & FGP_NOWAIT) { if (!trylock_page(page)) { put_page(page); return NULL; } } else { lock_page(page); } /* Has the page been truncated? */ if (unlikely(page->mapping != mapping)) { unlock_page(page); put_page(page); goto repeat; } VM_BUG_ON_PAGE(!thp_contains(page, index), page); } if (fgp_flags & FGP_ACCESSED) mark_page_accessed(page); else if (fgp_flags & FGP_WRITE) { /* Clear idle flag for buffer write */ if (page_is_idle(page)) clear_page_idle(page); } if (!(fgp_flags & FGP_HEAD)) page = find_subpage(page, index); no_page: if (!page && (fgp_flags & FGP_CREAT)) { int err; if ((fgp_flags & FGP_WRITE) && mapping_can_writeback(mapping)) gfp_mask |= __GFP_WRITE; if (fgp_flags & FGP_NOFS) gfp_mask &= ~__GFP_FS; page = __page_cache_alloc(gfp_mask); if (!page) return NULL; if (WARN_ON_ONCE(!(fgp_flags & (FGP_LOCK | FGP_FOR_MMAP)))) fgp_flags |= FGP_LOCK; /* Init accessed so avoid atomic mark_page_accessed later */ if (fgp_flags & FGP_ACCESSED) __SetPageReferenced(page); err = add_to_page_cache_lru(page, mapping, index, gfp_mask); if (unlikely(err)) { put_page(page); page = NULL; if (err == -EEXIST) goto repeat; } /* * add_to_page_cache_lru locks the page, and for mmap we expect * an unlocked page. */ if (page && (fgp_flags & FGP_FOR_MMAP)) unlock_page(page); } return page; }
まずは、mapping_get_entry関数の定義を確認する。
// 1817: static struct page *mapping_get_entry(struct address_space *mapping, pgoff_t index) { XA_STATE(xas, &mapping->i_pages, index); struct page *page; rcu_read_lock(); repeat: xas_reset(&xas); page = xas_load(&xas); if (xas_retry(&xas, page)) goto repeat; /* * A shadow entry of a recently evicted page, or a swap entry from * shmem/tmpfs. Return it without attempting to raise page count. */ if (!page || xa_is_value(page)) goto out; if (!page_cache_get_speculative(page)) goto repeat; /* * Has the page moved or been split? * This is part of the lockless pagecache protocol. See * include/linux/pagemap.h for details. */ if (unlikely(page != xas_reload(&xas))) { put_page(page); goto repeat; } out: rcu_read_unlock(); return page; }
mapping_get_entry関数はmappingからページキャッシュを検索する。
ページキャッシュは、Read-copy update (RCU) による排他制御を実現している。
ここで、RCUとはロックを取得しないという特徴があり、ページキャッシュのような書き込みより読み込みのほうが多いデータ構造に適用される。
RCUの仕組みについて下記の図を用いて解説する。
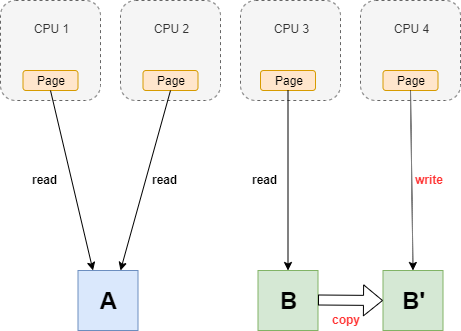
4コアのシステムで共通の資源(pageが示すAとB)を扱う場合
- readの場合、CPU1とCPU2はAをreadできる
- writeの場合、CPU3はBをreadして、CPU4はBの複製B'にwriteする
- 新しくBを参照する場合、B'に対してread/writeする
- Bを参照しなくなったら、BへのポイントをB'に更新する
より詳しく知りたい人は下記の記事で解説されているので、そちらを参照。
mapping_get_entry関数の先頭と末尾にあるrcu_read_lock関数とrcu_read_unlock関数は、RCUにおけるreadの開始と終わりを表す。
rcu_read_lock関数とrcu_read_unlock関数は、ロックを取るわけではなく、プリエンプトを無効にするだけとなっている。
RCUを宣言したら、XArrayからページキャッシュの取得を試みる。
XA_STATEマクロでXArrayデータ構造の宣言をするxas_reset関数でXArrayの状態を初期化するxas_load関数でXA_STATEで宣言したxasを辿りデータを取得することができる。- internal entryを返すことがある(multi-index entryの場合)ため、必要に応じて
xas_retry関数で再試行する xa_is_value関数で取得したデータが値エントリであることを確認するpage_cache_get_speculative関数でページキャッシュのリファレンスカウントを更新する- 取得したページキャッシュが移動されていないか
xas_reload関数で確認する
これらを踏まえて、pagecache_get_page関数に戻る。
pagecache_get_page関数は、find_get_entry関数で取得したページキャッシュが有効かどうかで処理が変わる。
ページキャッシュが存在する場合
pagecache_get_page関数は1901行目のgoto文は実行されず、処理を続ける。
// 1893: repeat: page = mapping_get_entry(mapping, index); if (xa_is_value(page)) { if (fgp_flags & FGP_ENTRY) return page; page = NULL; } if (!page) goto no_page; if (fgp_flags & FGP_LOCK) { if (fgp_flags & FGP_NOWAIT) { if (!trylock_page(page)) { put_page(page); return NULL; } } else { lock_page(page); } /* Has the page been truncated? */ if (unlikely(page->mapping != mapping)) { unlock_page(page); put_page(page); goto repeat; } VM_BUG_ON_PAGE(!thp_contains(page, index), page); } if (fgp_flags & FGP_ACCESSED) mark_page_accessed(page); else if (fgp_flags & FGP_WRITE) { /* Clear idle flag for buffer write */ if (page_is_idle(page)) clear_page_idle(page); } if (!(fgp_flags & FGP_HEAD)) page = find_subpage(page, index);
ページキャッシュが有効である場合の挙動は以下の通りとなる。
- 既に
PG_lockedフラグが設定されている場合、ページキャッシュが獲得するまでwaitする。(lock_page関数) - これまでの間にページキャッシュが切り捨てられてしまった場合には、フラグの解除とリファレンスカウントを下げて、再度ページキャッシュの取得を試みる。
- ページがidle状態になっていれば、PAGE_EXT_IDLEフラグを落とす。
- 取得したページキャッシュを返す*1。
状況によって異なるが、参考としてページキャッシュ取得時のフラグを下記に示す。
| フラグ名 | 説明 |
|---|---|
| PG_uptodate | ページ読み込みが完了している |
| PG_lru | LRUリスト内にある |
| PG_private | privateメンバを使用している |
ページキャッシュが存在していない場合
下記の文献を参照。
次に、ページキャッシュが有効である場合(xa_is_valueがtrue)について考える。
pagecache_get_page関数はno_pageラベルにジャンプする。
// 1932: no_page: if (!page && (fgp_flags & FGP_CREAT)) { int err; if ((fgp_flags & FGP_WRITE) && mapping_can_writeback(mapping)) gfp_mask |= __GFP_WRITE; if (fgp_flags & FGP_NOFS) gfp_mask &= ~__GFP_FS; page = __page_cache_alloc(gfp_mask); if (!page) return NULL; if (WARN_ON_ONCE(!(fgp_flags & (FGP_LOCK | FGP_FOR_MMAP)))) fgp_flags |= FGP_LOCK; /* Init accessed so avoid atomic mark_page_accessed later */ if (fgp_flags & FGP_ACCESSED) __SetPageReferenced(page); err = add_to_page_cache_lru(page, mapping, index, gfp_mask); if (unlikely(err)) { put_page(page); page = NULL; if (err == -EEXIST) goto repeat; } /* * add_to_page_cache_lru locks the page, and for mmap we expect * an unlocked page. */ if (page && (fgp_flags & FGP_FOR_MMAP)) unlock_page(page); } return page; }
もし、有効なページキャッシュが存在していなかった場合、__page_cache_alloc関数でページを確保する。
__page_cache_alloc関数の定義は下記の通りである。
// 299: #ifdef CONFIG_NUMA extern struct page *__page_cache_alloc(gfp_t gfp); #else static inline struct page *__page_cache_alloc(gfp_t gfp) { return alloc_pages(gfp, 0); } #endif
今回の環境はCONFIG_NUMA=nであるので、__page_cache_alloc関数はalloc_pagesを呼び出す。
// 595: static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order) { return alloc_pages_node(numa_node_id(), gfp_mask, order); }
numa_node_id()はマクロであり、現在使用しているCPU(今回の場合は0)となる。
alloc_pages関数は、alloc_pages_node関数を呼び出す。
// 578: static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order) { if (nid == NUMA_NO_NODE) nid = numa_mem_id(); return __alloc_pages_node(nid, gfp_mask, order); }
// 564: static inline struct page * __alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order) { VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES); VM_WARN_ON((gfp_mask & __GFP_THISNODE) && !node_online(nid)); return __alloc_pages(gfp_mask, order, nid, NULL); }
__alloc_pages_node関数はパラメータのチェックをして、__alloc_pages関数を呼び出す。
__alloc_pages関数については、下記の記事に解説が載っているので、解説は省略する。
ページキャッシュを取得できたら、add_to_page_cache_lru関数を実行する。
最近参照したデータほど再度参照する可能性が高いということから、LRUリストでも管理している。
add_to_page_cache_lru関数はLRUリストに追加する関数であり、定義は下記のようになっている。
// 977: int add_to_page_cache_lru(struct page *page, struct address_space *mapping, pgoff_t offset, gfp_t gfp_mask) { void *shadow = NULL; int ret; __SetPageLocked(page); ret = __add_to_page_cache_locked(page, mapping, offset, gfp_mask, &shadow); if (unlikely(ret)) __ClearPageLocked(page); else { /* * The page might have been evicted from cache only * recently, in which case it should be activated like * any other repeatedly accessed page. * The exception is pages getting rewritten; evicting other * data from the working set, only to cache data that will * get overwritten with something else, is a waste of memory. */ WARN_ON_ONCE(PageActive(page)); if (!(gfp_mask & __GFP_WRITE) && shadow) workingset_refault(page, shadow); lru_cache_add(page); } return ret; }
938行目の__SetPageLockedマクロは引数のpageに対して、PG_lockedフラグを設定する。
| フラグ名 | 説明 |
|---|---|
| PG_locked | ページはロック状態 |
その後、939行目の__add_to_page_cache_locked関数でpageとaddress_space構造体を関連付ける。(概要は省略する)
// 442: void lru_cache_add(struct page *page) { struct pagevec *pvec; VM_BUG_ON_PAGE(PageActive(page) && PageUnevictable(page), page); VM_BUG_ON_PAGE(PageLRU(page), page); get_page(page); local_lock(&lru_pvecs.lock); pvec = this_cpu_ptr(&lru_pvecs.lru_add); if (pagevec_add_and_need_flush(pvec, page)) __pagevec_lru_add(pvec); local_unlock(&lru_pvecs.lock); }
lru_cache_add関数では、獲得したページをlruリストにすぐには登録しない。
pagevec_add関数で一旦CPU変数へ登録して、後ほどまとめてlryリストに登録する。
pagevec_add関数が0を返すとき、溜まったページキャッシュを__pagevec_lru_add関数でlruリストに登録する。
バッファキャッシュ用のデータ構造を作成する
Linuxではページキャッシュとは別にバッファキャッシュというデータ構造が存在している。
バッファキャッシュはストレージのデータをメモリにキャッシュするためのものである。
ファイルシステムの観点でいえば、ファイルの実データやinode, ディレクトリなどが対象となっている。
さらに、バッファキャッシュはページキャッシュと紐づけることになっている。
write_beginでは、__block_write_begin関数でバッファキャッシュを準備する。
// 2109: int block_write_begin(struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, get_block_t *get_block) { pgoff_t index = pos >> PAGE_SHIFT; struct page *page; int status; page = grab_cache_page_write_begin(mapping, index, flags); if (!page) return -ENOMEM; status = __block_write_begin(page, pos, len, get_block); if (unlikely(status)) { unlock_page(page); put_page(page); page = NULL; } *pagep = page; return status; }
grab_cache_page_write_begin関数によってページキャッシュが取得できたら、__block_write_begin関数でバッファキャッシュ用のデータ構造を作成する。
__block_write_begin関数の定義は下記のとおりである。
// 2057: int __block_write_begin(struct page *page, loff_t pos, unsigned len, get_block_t *get_block) { return __block_write_begin_int(page, pos, len, get_block, NULL); }
__block_write_begin関数は、仮引数と__block_write_begin_int関数に渡すだけとなっている。
__block_write_begin_int関数の定義は下記の通りである。
// 1972: int __block_write_begin_int(struct page *page, loff_t pos, unsigned len, get_block_t *get_block, const struct iomap *iomap) { unsigned from = pos & (PAGE_SIZE - 1); unsigned to = from + len; struct inode *inode = page->mapping->host; unsigned block_start, block_end; sector_t block; int err = 0; unsigned blocksize, bbits; struct buffer_head *bh, *head, *wait[2], **wait_bh=wait; BUG_ON(!PageLocked(page)); BUG_ON(from > PAGE_SIZE); BUG_ON(to > PAGE_SIZE); BUG_ON(from > to); head = create_page_buffers(page, inode, 0); blocksize = head->b_size; bbits = block_size_bits(blocksize); block = (sector_t)page->index << (PAGE_SHIFT - bbits); for(bh = head, block_start = 0; bh != head || !block_start; block++, block_start=block_end, bh = bh->b_this_page) { block_end = block_start + blocksize; if (block_end <= from || block_start >= to) { if (PageUptodate(page)) { if (!buffer_uptodate(bh)) set_buffer_uptodate(bh); } continue; } if (buffer_new(bh)) clear_buffer_new(bh); if (!buffer_mapped(bh)) { WARN_ON(bh->b_size != blocksize); if (get_block) { err = get_block(inode, block, bh, 1); if (err) break; } else { iomap_to_bh(inode, block, bh, iomap); } if (buffer_new(bh)) { clean_bdev_bh_alias(bh); if (PageUptodate(page)) { clear_buffer_new(bh); set_buffer_uptodate(bh); mark_buffer_dirty(bh); continue; } if (block_end > to || block_start < from) zero_user_segments(page, to, block_end, block_start, from); continue; } } if (PageUptodate(page)) { if (!buffer_uptodate(bh)) set_buffer_uptodate(bh); continue; } if (!buffer_uptodate(bh) && !buffer_delay(bh) && !buffer_unwritten(bh) && (block_start < from || block_end > to)) { ll_rw_block(REQ_OP_READ, 0, 1, &bh); *wait_bh++=bh; } } /* * If we issued read requests - let them complete. */ while(wait_bh > wait) { wait_on_buffer(*--wait_bh); if (!buffer_uptodate(*wait_bh)) err = -EIO; } if (unlikely(err)) page_zero_new_buffers(page, from, to); return err; }
__block_write_begin_int関数の最初に引数のチェックがある。
下記のどれかを満たしていない場合、BUG_ONマクロでカーネルパニックさせる。
- ページにロックがかかっていること
- 開始オフセットがページサイズより小さいこと
- 終了オフセットがページサイズより小さいこと
- 終了オフセットが開始オフセットより大きいこと
バッファキャッシュを準備する
引数をチェックし問題がなければ、create_page_buffers関数でbuffer_headを生成する。
// 1672: static struct buffer_head *create_page_buffers(struct page *page, struct inode *inode, unsigned int b_state) { BUG_ON(!PageLocked(page)); if (!page_has_buffers(page)) create_empty_buffers(page, 1 << READ_ONCE(inode->i_blkbits), b_state); return page_buffers(page); }
すでにバッファキャッシュが確保済みである場合は、page_has_buffersマクロがTrueとなりバッファキャッシュを再度確保せずに終了する。
そうでなければ、create_empty_buffers関数でバッファキャッシュの作成を試みる。
// 1555: void create_empty_buffers(struct page *page, unsigned long blocksize, unsigned long b_state) { struct buffer_head *bh, *head, *tail; head = alloc_page_buffers(page, blocksize, true); bh = head; do { bh->b_state |= b_state; tail = bh; bh = bh->b_this_page; } while (bh); tail->b_this_page = head; spin_lock(&page->mapping->private_lock); if (PageUptodate(page) || PageDirty(page)) { bh = head; do { if (PageDirty(page)) set_buffer_dirty(bh); if (PageUptodate(page)) set_buffer_uptodate(bh); bh = bh->b_this_page; } while (bh != head); } attach_page_private(page, head); spin_unlock(&page->mapping->private_lock); }
create_empty_buffers関数の処理は大きく分けて下記のとおりである。
- RAM上にバッファキャッシュを確保する
- バッファキャッシュ間で循環ループを作成する
- バッファキャッシュとファイルシステムのデータを同期させる
バッファキャッシュを確保する
バッファキャッシュの確保は、alloc_page_buffers関数で実施する。
ただし、今回は説明を簡略化するためにcgroupの話は省着する。
ブロックサイズが1024, ページサイズが4096の場合、4つのbuffer_headを生成する。
alloc_page_buffers関数によって得られるデータ構造のイメージは下記のとおりである。

alloc_page_buffers関数の定義は下記のとおりである。
// 814: struct buffer_head *alloc_page_buffers(struct page *page, unsigned long size, bool retry) { struct buffer_head *bh, *head; gfp_t gfp = GFP_NOFS | __GFP_ACCOUNT; long offset; struct mem_cgroup *memcg, *old_memcg; if (retry) gfp |= __GFP_NOFAIL; /* The page lock pins the memcg */ memcg = page_memcg(page); old_memcg = set_active_memcg(memcg); head = NULL; offset = PAGE_SIZE; while ((offset -= size) >= 0) { bh = alloc_buffer_head(gfp); if (!bh) goto no_grow; bh->b_this_page = head; bh->b_blocknr = -1; head = bh; bh->b_size = size; /* Link the buffer to its page */ set_bh_page(bh, page, offset); } out: set_active_memcg(old_memcg); return head; /* * In case anything failed, we just free everything we got. */ no_grow: if (head) { do { bh = head; head = head->b_this_page; free_buffer_head(bh); } while (head); } goto out; }
alloc_page_buffers関数では、831行目のwhile文がメインとなる。
alloc_buffer_head関数でbuffer_headを取得する- 確保した
bhをひとつ前のheadに繋げる set_bh_page関数で、ページキャッシュとバッファを紐づける
alloc_buffer_head関数は、kmem_cache_zalloc関数をデータを確保する。
// 3334: struct buffer_head *alloc_buffer_head(gfp_t gfp_flags) { struct buffer_head *ret = kmem_cache_zalloc(bh_cachep, gfp_flags); if (ret) { INIT_LIST_HEAD(&ret->b_assoc_buffers); spin_lock_init(&ret->b_uptodate_lock); preempt_disable(); __this_cpu_inc(bh_accounting.nr); recalc_bh_state(); preempt_enable(); } return ret; } EXPORT_SYMBOL(alloc_buffer_head);
また、set_bh_page関数は下記の通りとなっている。
// 1442: void set_bh_page(struct buffer_head *bh, struct page *page, unsigned long offset) { bh->b_page = page; BUG_ON(offset >= PAGE_SIZE); if (PageHighMem(page)) /* * This catches illegal uses and preserves the offset: */ bh->b_data = (char *)(0 + offset); else bh->b_data = page_address(page) + offset; }
循環ループを作成する
alloc_page_buffers関数でbuffer_headのリストを生成した後、各データのb_state変数を設定する。
// 1561: bh = head; do { bh->b_state |= b_state; tail = bh; bh = bh->b_this_page; } while (bh); tail->b_this_page = head;
その後、末尾のbuffer_headと先頭のbuffer_headをつなげる。
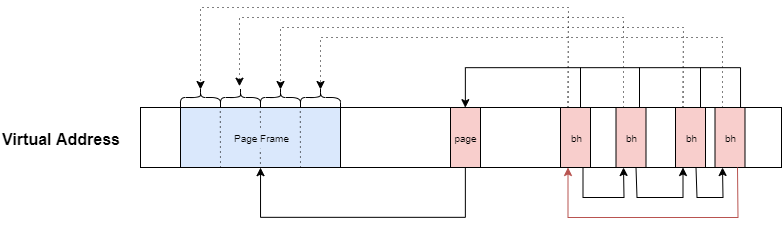
バッファキャッシュとファイルシステムを紐付ける
create_page_buffers関数によってバッファキャッシュを作成した後、取得したバッファキャッシュに書き込み対象ファイルのデータを読み込む。
// 1989: head = create_page_buffers(page, inode, 0); blocksize = head->b_size; bbits = block_size_bits(blocksize); block = (sector_t)page->index << (PAGE_SHIFT - bbits); for(bh = head, block_start = 0; bh != head || !block_start; block++, block_start=block_end, bh = bh->b_this_page) { block_end = block_start + blocksize; if (block_end <= from || block_start >= to) { if (PageUptodate(page)) { if (!buffer_uptodate(bh)) set_buffer_uptodate(bh); } continue; } if (buffer_new(bh)) clear_buffer_new(bh); if (!buffer_mapped(bh)) { WARN_ON(bh->b_size != blocksize); if (get_block) { err = get_block(inode, block, bh, 1); if (err) break; } else { iomap_to_bh(inode, block, bh, iomap); } if (buffer_new(bh)) { clean_bdev_bh_alias(bh); if (PageUptodate(page)) { clear_buffer_new(bh); set_buffer_uptodate(bh); mark_buffer_dirty(bh); continue; } if (block_end > to || block_start < from) zero_user_segments(page, to, block_end, block_start, from); continue; } } if (PageUptodate(page)) { if (!buffer_uptodate(bh)) set_buffer_uptodate(bh); continue; } if (!buffer_uptodate(bh) && !buffer_delay(bh) && !buffer_unwritten(bh) && (block_start < from || block_end > to)) { ll_rw_block(REQ_OP_READ, 0, 1, &bh); *wait_bh++=bh; } } /* * If we issued read requests - let them complete. */ while(wait_bh > wait) { wait_on_buffer(*--wait_bh); if (!buffer_uptodate(*wait_bh)) err = -EIO; } if (unlikely(err)) page_zero_new_buffers(page, from, to); return err; }
1989行の実行直後ではページディスクリプタは下記のようなフラグが立っている。
| フラグ名 | 説明 |
|---|---|
| PG_uptodate | ページ読み込みが完了している |
| PG_lru | LRUリスト内にある |
| PG_private | privateメンバを使用している |
create_page_buffers関数の以降の処理は下記の通りとなる。
- ページキャッシュに
PG_uptodate*2が付与されていた場合、バッファキャッシュにもBH_Uptodateを付与し、次のバッファキャッシュを確認する - バッファキャッシュに
BH_New*3が付与されていた場合、フラグをクリアする - バッファキャッシュに
BH_mapped*4が付与されていない場合、引数のget_blockハンドラを実行してバッファキャッシュにマッピングする get_blockハンドラでバッファキャッシュを新規にマッピングした場合、ブロックデバイスのバッファをフラッシュする (参考)get_blockハンドラでバッファキャッシュを新規にマッピングした場合かつページディスクリプタがPG_Uptodateである場合、BH_Newフラグを落としBH_Uptodateとmark_buffer_dirty関数を実行して次のバッファキャッシュを確認する。get_blockハンドラでバッファキャッシュを新規にマッピングした場合で、ページキャッシュのゼロ化が必要な場合、ゼロ化し次のバッファキャッシュを確認する- ページディスクリプタが
PG_Uptodateであるにもかかわらず、バッファキャッシュがBH_Uptodateでない場合、BH_Uptodateフラグを立てて次のバッファキャッシュを確認する。 - バッファキャッシュに
BH_Uptodate、BH_Delay*5かつBH_Unwritten*6の何れも立っていない場合、読み込みのためのIOを発行する。
各バッファキャッシュの更新を終えた後、読み込みのためのIOを発行していた場合は、2048行目のwait_on_bufferインライン関数でIOの完了を待つ。
write_begin処理内で失敗した場合
これまでの処理で何かしらも問題が発生した場合、block_write_begin関数の返り値に負の値が返る。
// 883: static int ext2_write_begin(struct file *file, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata) { int ret; ret = block_write_begin(mapping, pos, len, flags, pagep, ext2_get_block); if (ret < 0) ext2_write_failed(mapping, pos + len); return ret; }
その場合、ext2_write_failed関数を呼び、ページキャッシュの解放とaddress_spaceのロールバックをする。詳細は割愛。
// 59: static void ext2_write_failed(struct address_space *mapping, loff_t to) { struct inode *inode = mapping->host; if (to > inode->i_size) { truncate_pagecache(inode, inode->i_size); ext2_truncate_blocks(inode, inode->i_size); } }
おわりに
本記事では、ext2ファイルシステムのwrite_begin操作(ext2_write_begin)を解説した。
write_begin操作は、write_iter操作でページキャッシュに書き込むための準備をするための操作である。
変更履歴
- 2021/4/24: 記事公開
- 2022/09/19: カーネルバージョンを5.15に変更
参考
- XArray — The Linux Kernel documentation
- XArrayのAPIドキュメント
- ページキャッシュについて - Linuxカーネル@wiki
- Linux-4系におけるページキャッシュについての解説
- ページキャッシュ - Linuxの備忘録とか・・・(目次へ)
- ページキャッシュの取得について
- LinuxのRCUのコードを読んでみる (rcu_read_{lock,unlock}編) #Linux - Qiita
- RCUのロックについて
- RCU(Read Copy Update)をちゃんと知る(1)-2 実装よりの概要 - tkokamoの日記
- RCUの概要
- RCU concepts — The Linux Kernel documentation
- RCUのカーネルドキュメント
- Page reclaim | PPT
- メモリ回収 (Direct reclaimなど)
- 空きページの確保 - Linuxカーネルメモ
- 空きページの確保
- linux: page allocatorの辺りを読んでいこう - φ(・・*)ゞ ウーン カーネルとか弄ったりのメモ
- get_page_from_freelist()の処理 - φ(・・*)ゞ ウーン カーネルとか弄ったりのメモ
- buddy system: __alloc_pages_slowpath()のざっくりとした流れ。 - φ(・・*)ゞ ウーン カーネルとか弄ったりのメモ
- ページアロケータ周りの詳細な解説