関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 23: MMC (4) mmc_attach_sd
- 概要
- はじめに
- blk-mqの概要
- writepages関数から呼ばれるblk_mq_submit_bio関数
- write_inode関数から呼ばれるblk_mq_submit_bio関数
- おわりに
- 変更履歴
- 参考
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、blk_mq_submit_bio関数を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。

本記事では、writebackカーネルスレッドがblk_mq_submit_bio関数を呼び出すところから、blk_mq_submit_bio関数を呼ぶところまでを確認する。
blk-mqの概要
Multi-Queue Block (blk-mq) はブロックデバイスに IOリクエストを複数個のキューで管理することで高速なストレージデバイスでの並列処理によりボトルネックを解消するカーネルの機構の一つである。
blk-mqには、Software Staging queues と Hardware dispatch queues の2つの種類キューを持つ。
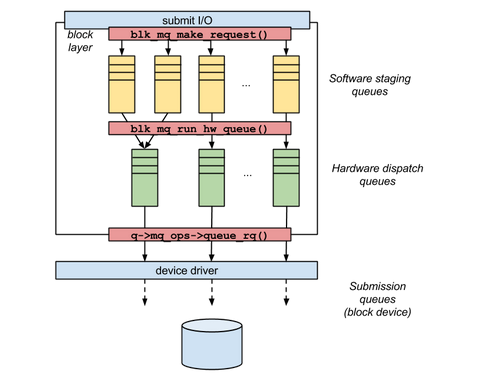
Software Staging queues と Hardware dispatch queue
Software staging queues (struct blk_mq_ctx) は複数個のキューがあり、隣接したセクターをマージしたり、Hardware dispatch queuesにキューイングする前にrequestを並び替える。
Hardware dispatch queues (struct blk_mq_hw_ctx) はデバイス側のキューと同数が生成され、デバイスドライバがrequestを投げる。

この時、CPUがIOリクエストを特定できるよう Tagging がされる。
sbitmap
blk-mq では、Tagging に sbitmap と呼ばれるデータ構造を用いて管理する。
通常の bitmap では、管理した特定のデータを 1bit 単位に分割して、 0 or 1 を管理する。
この時、管理するデータが大きくなると、排他制御によるパフォーマンスの劣化が問題となっていた。
sbitmapでは、ビットマップを細分化して、0 or 1 を管理する。
これにより、排他制御によるパフォーマンスの劣化問題を緩和させている。

sbitmapは、Linux Kernelの sbitmap構造体によって管理される。
sbitmap構造体には、sbitmap_wordを管理するためのメンバ (depthやmap_nrなど) が存在している。
この構造体のメンバmapが実際に 0 or 1 を管理するbitmap (sbitmap_word)となっている。
また、sbitmap構造体は sbitmap_queueによる Wait Queue を用いて管理される。

writepages関数から呼ばれるblk_mq_submit_bio関数

blk_mq_submit_bio関数は、ブロックデバイス (Multi-Queue)にrequestを作成する。
blk_mq_submit_bio関数の定義は下記の通りとなっている。
// 2177: blk_qc_t blk_mq_submit_bio(struct bio *bio) { struct request_queue *q = bio->bi_bdev->bd_disk->queue; const int is_sync = op_is_sync(bio->bi_opf); const int is_flush_fua = op_is_flush(bio->bi_opf); struct blk_mq_alloc_data data = { .q = q, }; struct request *rq; struct blk_plug *plug; struct request *same_queue_rq = NULL; unsigned int nr_segs; blk_qc_t cookie; blk_status_t ret; bool hipri; blk_queue_bounce(q, &bio); __blk_queue_split(&bio, &nr_segs); if (!bio_integrity_prep(bio)) goto queue_exit; if (!is_flush_fua && !blk_queue_nomerges(q) && blk_attempt_plug_merge(q, bio, nr_segs, &same_queue_rq)) goto queue_exit; if (blk_mq_sched_bio_merge(q, bio, nr_segs)) goto queue_exit; rq_qos_throttle(q, bio); hipri = bio->bi_opf & REQ_HIPRI; data.cmd_flags = bio->bi_opf; rq = __blk_mq_alloc_request(&data); if (unlikely(!rq)) { rq_qos_cleanup(q, bio); if (bio->bi_opf & REQ_NOWAIT) bio_wouldblock_error(bio); goto queue_exit; } trace_block_getrq(bio); rq_qos_track(q, rq, bio); cookie = request_to_qc_t(data.hctx, rq); blk_mq_bio_to_request(rq, bio, nr_segs); ret = blk_crypto_init_request(rq); if (ret != BLK_STS_OK) { bio->bi_status = ret; bio_endio(bio); blk_mq_free_request(rq); return BLK_QC_T_NONE; } plug = blk_mq_plug(q, bio); if (unlikely(is_flush_fua)) { /* Bypass scheduler for flush requests */ blk_insert_flush(rq); blk_mq_run_hw_queue(data.hctx, true); } else if (plug && (q->nr_hw_queues == 1 || blk_mq_is_sbitmap_shared(rq->mq_hctx->flags) || q->mq_ops->commit_rqs || !blk_queue_nonrot(q))) { /* * Use plugging if we have a ->commit_rqs() hook as well, as * we know the driver uses bd->last in a smart fashion. * * Use normal plugging if this disk is slow HDD, as sequential * IO may benefit a lot from plug merging. */ unsigned int request_count = plug->rq_count; struct request *last = NULL; if (!request_count) trace_block_plug(q); else last = list_entry_rq(plug->mq_list.prev); if (request_count >= blk_plug_max_rq_count(plug) || (last && blk_rq_bytes(last) >= BLK_PLUG_FLUSH_SIZE)) { blk_flush_plug_list(plug, false); trace_block_plug(q); } blk_add_rq_to_plug(plug, rq); } else if (q->elevator) { /* Insert the request at the IO scheduler queue */ blk_mq_sched_insert_request(rq, false, true, true); } else if (plug && !blk_queue_nomerges(q)) { /* * We do limited plugging. If the bio can be merged, do that. * Otherwise the existing request in the plug list will be * issued. So the plug list will have one request at most * The plug list might get flushed before this. If that happens, * the plug list is empty, and same_queue_rq is invalid. */ if (list_empty(&plug->mq_list)) same_queue_rq = NULL; if (same_queue_rq) { list_del_init(&same_queue_rq->queuelist); plug->rq_count--; } blk_add_rq_to_plug(plug, rq); trace_block_plug(q); if (same_queue_rq) { data.hctx = same_queue_rq->mq_hctx; trace_block_unplug(q, 1, true); blk_mq_try_issue_directly(data.hctx, same_queue_rq, &cookie); } } else if ((q->nr_hw_queues > 1 && is_sync) || !data.hctx->dispatch_busy) { /* * There is no scheduler and we can try to send directly * to the hardware. */ blk_mq_try_issue_directly(data.hctx, rq, &cookie); } else { /* Default case. */ blk_mq_sched_insert_request(rq, false, true, true); } if (!hipri) return BLK_QC_T_NONE; return cookie; queue_exit: blk_queue_exit(q); return BLK_QC_T_NONE; }
| type | name | Description |
|---|---|---|
| request_queue | *q | |
| blk_mq_req_flags_t | flags | |
| unsigned int | shallow_depth | |
| unsigned int | cmd_flags | |
| struct blk_mq_ctx | *ctx | Software staging queues |
| struct blk_mq_hq_ctx | *hctx | Hardware dispatch queues |
bounce buffersの作成
blk_queue_bounce関数は、bounce buffersを作成する関数となっている。
デバイスブロックとデバイスのやり取りは、bioに設定されているページとDMAで行っています。もしそのページがハイメモリ等の、デバイスとDMAでやり取りできないページだと、元のbioを複製した物に、DMAとやり取りするページを割り当てる事でDMA転送を行います。このbioをバウンスバッファーと言うそうです。新たに作成したbioには、bi_privateメンバーに、元のbioが設定されており、読み込みなら、新たに設定したブロックIO終了コールバック関数で、DMA転送されたデータを、元のbioのページに転送する事になります。
// 324: static inline void blk_queue_bounce(struct request_queue *q, struct bio **bio) { if (unlikely(blk_queue_may_bounce(q) && bio_has_data(*bio))) __blk_queue_bounce(q, bio); }
// 317: static inline bool blk_queue_may_bounce(struct request_queue *q) { return IS_ENABLED(CONFIG_BOUNCE) && q->limits.bounce == BLK_BOUNCE_HIGH && max_low_pfn >= max_pfn; }
bounce buffersを作成する条件としては、blk_queue_may_bounce関数で判定することができる。
ただし、ここではq->limits.bounce = BLK_BOUNCE_NONE (bounceしない)ようとなっているので、bounce buffersは作成しない。
bioの分割
__blk_queue_split関数はbioを分割し、後続のbioを発行する。
// 305: void __blk_queue_split(struct bio **bio, unsigned int *nr_segs) { struct request_queue *q = (*bio)->bi_bdev->bd_disk->queue; struct bio *split = NULL; switch (bio_op(*bio)) { case REQ_OP_DISCARD: case REQ_OP_SECURE_ERASE: split = blk_bio_discard_split(q, *bio, &q->bio_split, nr_segs); break; case REQ_OP_WRITE_ZEROES: split = blk_bio_write_zeroes_split(q, *bio, &q->bio_split, nr_segs); break; case REQ_OP_WRITE_SAME: split = blk_bio_write_same_split(q, *bio, &q->bio_split, nr_segs); break; default: /* * All drivers must accept single-segments bios that are <= * PAGE_SIZE. This is a quick and dirty check that relies on * the fact that bi_io_vec[0] is always valid if a bio has data. * The check might lead to occasional false negatives when bios * are cloned, but compared to the performance impact of cloned * bios themselves the loop below doesn't matter anyway. */ if (!q->limits.chunk_sectors && (*bio)->bi_vcnt == 1 && ((*bio)->bi_io_vec[0].bv_len + (*bio)->bi_io_vec[0].bv_offset) <= PAGE_SIZE) { *nr_segs = 1; break; } split = blk_bio_segment_split(q, *bio, &q->bio_split, nr_segs); break; } if (split) { /* there isn't chance to merge the splitted bio */ split->bi_opf |= REQ_NOMERGE; bio_chain(split, *bio); trace_block_split(split, (*bio)->bi_iter.bi_sector); submit_bio_noacct(*bio); *bio = split; blk_throtl_charge_bio_split(*bio); } }
特殊なbio (REQ_OP_DISCARD, REQ_OP_SECURE_ERASE, REQ_OP_WRITE_ZEROES, REQ_OP_WRITE_SAME)でない限り、
分割可能か(簡易)チェックが入る。
- RAIDやzonedによって
chunk_sectorsが設定されていない場合 - 配列bio_vecに格納されているエントリ数が1つのみの場合
- データ開始位置のページ内オフセット + データ長がページサイズ内に収まる場合
上記の条件をすべて満たす場合には、分割不可能と判断してbioの分割は実施しない。
ブロックレイヤのデータ整合性
bio_integrity_prep関数は、ブロックレイヤにおけるデータ整合性の機能に必要な準備をする関数となっている。
この関数は、KconfigのCONFIG_BLK_DEV_INTEGRITYによって呼び出し先の関数が異なる。
この環境では CONFIG_BLK_DEV_INTEGRITY=nとなっているため trueを返すだけの関数となっている。
// 732: static inline bool bio_integrity_prep(struct bio *bio) { return true; }
リクエストのマージ確認
// 2199: if (!is_flush_fua && !blk_queue_nomerges(q) && blk_attempt_plug_merge(q, bio, nr_segs, &same_queue_rq)) goto queue_exit; if (blk_mq_sched_bio_merge(q, bio, nr_segs)) goto queue_exit;
REQ_FUAかREQ_PREFLUSHが設定されていない- デバイスが
QUEUE_FLAG_NOMERGES
上記の条件をすべて満たす場合、かつblk_attempt_plug_merge関数がtrueとなった場合、queue_exitラベルでblk_mq_submit_bio関数を終了する。
blk_attempt_plug_merge関数は、plugged list内のBIOをマージする関数となっている。
// 1043: bool blk_attempt_plug_merge(struct request_queue *q, struct bio *bio, unsigned int nr_segs, struct request **same_queue_rq) { struct blk_plug *plug; struct request *rq; struct list_head *plug_list; plug = blk_mq_plug(q, bio); if (!plug) return false; plug_list = &plug->mq_list; list_for_each_entry_reverse(rq, plug_list, queuelist) { if (rq->q == q && same_queue_rq) { /* * Only blk-mq multiple hardware queues case checks the * rq in the same queue, there should be only one such * rq in a queue **/ *same_queue_rq = rq; } if (rq->q != q) continue; if (blk_attempt_bio_merge(q, rq, bio, nr_segs, false) == BIO_MERGE_OK) return true; } return false; }
plugged list内のmq_listから、各requestに対してblk_attempt_bio_merge関数を実行する。
ただし、ここではmq_listは一つのみであるので falseを返すだけの関数となっている。
また、一方でblk_mq_sched_bio_merge関数はIO schedulerによる IOのマージを試みる関数となっている。
// 33: static inline bool blk_mq_sched_bio_merge(struct request_queue *q, struct bio *bio, unsigned int nr_segs) { if (blk_queue_nomerges(q) || !bio_mergeable(bio)) return false; return __blk_mq_sched_bio_merge(q, bio, nr_segs); }
- デバイスが
QUEUE_FLAG_NOMERGES - bioが
REQ_NOMERGE_FLAGS
上記の条件をいずれも満たさない場合、blk_mq_sched_bio_merge関数を実行する。
__blk_mq_sched_bio_merge関数は、IOスケジューラによるbioのマージを実施する関数となっている。
// 366: bool __blk_mq_sched_bio_merge(struct request_queue *q, struct bio *bio, unsigned int nr_segs) { struct elevator_queue *e = q->elevator; struct blk_mq_ctx *ctx; struct blk_mq_hw_ctx *hctx; bool ret = false; enum hctx_type type; if (e && e->type->ops.bio_merge) return e->type->ops.bio_merge(q, bio, nr_segs); ctx = blk_mq_get_ctx(q); hctx = blk_mq_map_queue(q, bio->bi_opf, ctx); type = hctx->type; if (!(hctx->flags & BLK_MQ_F_SHOULD_MERGE) || list_empty_careful(&ctx->rq_lists[type])) return false; /* default per sw-queue merge */ spin_lock(&ctx->lock); /* * Reverse check our software queue for entries that we could * potentially merge with. Currently includes a hand-wavy stop * count of 8, to not spend too much time checking for merges. */ if (blk_bio_list_merge(q, &ctx->rq_lists[type], bio, nr_segs)) { ctx->rq_merged++; ret = true; } spin_unlock(&ctx->lock); return ret; }
IO Schedulerはマージ処理に対応している場合は固有のbio_merge処理を呼び出し、 そうでばければblk-mq汎用のマージ処理を試みる。
ここではmq_deadlineが設定されており、かつbio_mergeとしてdd_bio_merge処理が定義されているので、それを呼び出す。
MQ-deadline IO schedulerの詳細はここでは割愛する。
ここでは、e->type->ops.bio_mergeではfalseが返される。
requestの作成
__blk_mq_alloc_request関数は、requestを作成する関数となっている。
// 355: static struct request *__blk_mq_alloc_request(struct blk_mq_alloc_data *data) { struct request_queue *q = data->q; struct elevator_queue *e = q->elevator; u64 alloc_time_ns = 0; unsigned int tag; /* alloc_time includes depth and tag waits */ if (blk_queue_rq_alloc_time(q)) alloc_time_ns = ktime_get_ns(); if (data->cmd_flags & REQ_NOWAIT) data->flags |= BLK_MQ_REQ_NOWAIT; if (e) { /* * Flush/passthrough requests are special and go directly to the * dispatch list. Don't include reserved tags in the * limiting, as it isn't useful. */ if (!op_is_flush(data->cmd_flags) && !blk_op_is_passthrough(data->cmd_flags) && e->type->ops.limit_depth && !(data->flags & BLK_MQ_REQ_RESERVED)) e->type->ops.limit_depth(data->cmd_flags, data); } retry: data->ctx = blk_mq_get_ctx(q); data->hctx = blk_mq_map_queue(q, data->cmd_flags, data->ctx); if (!e) blk_mq_tag_busy(data->hctx); /* * Waiting allocations only fail because of an inactive hctx. In that * case just retry the hctx assignment and tag allocation as CPU hotplug * should have migrated us to an online CPU by now. */ tag = blk_mq_get_tag(data); if (tag == BLK_MQ_NO_TAG) { if (data->flags & BLK_MQ_REQ_NOWAIT) return NULL; /* * Give up the CPU and sleep for a random short time to ensure * that thread using a realtime scheduling class are migrated * off the CPU, and thus off the hctx that is going away. */ msleep(3); goto retry; } return blk_mq_rq_ctx_init(data, tag, alloc_time_ns); }
最初の処理にあるblk_queue_rq_alloc_timeは、Kconfigによって処理が異なる関数となっている。
// 620: #ifdef CONFIG_BLK_RQ_ALLOC_TIME #define blk_queue_rq_alloc_time(q) \ test_bit(QUEUE_FLAG_RQ_ALLOC_TIME, &(q)->queue_flags) #else #define blk_queue_rq_alloc_time(q) false #endif
CONFIG_BLK_RQ_ALLOC_TIME=yの場合には、このrequestにbioが追加された最初の時間が記録されるようになる。
ただし、ここではCONFIG_BLK_RQ_ALLOC_TIME=nとなっているため、falseを返すだけの関数となる。
また、IO schedulerが登録されている場合には、
- bioが
REQ_FUAまたはREQ_PREFLUSHではない場合 - bioが
REQ_OP_DRV_INまたはREQ_OP_DRV_OUTではない場合 - IO scheduler が limit_depthをサポートしている場合
- allocate from reserved poolではない場合
上記のすべてを満たす場合、IO schedulerのlimit_depthを実行し、Hardware Queueの数をヒントとして持って置く。
キューの取得
その後、blk_mq_get_ctx関数で現在のCPU用のSoftware Queueを、blk_mq_map_queue関数でHardware Queueを取得する。
// 146: static inline struct blk_mq_ctx *blk_mq_get_ctx(struct request_queue *q) { return __blk_mq_get_ctx(q, raw_smp_processor_id()); }
// 134: static inline struct blk_mq_ctx *__blk_mq_get_ctx(struct request_queue *q, unsigned int cpu) { return per_cpu_ptr(q->queue_ctx, cpu); }
一方で、blk_mq_map_queue関数は次のような定義となっている。
// 105: static inline struct blk_mq_hw_ctx *blk_mq_map_queue(struct request_queue *q, unsigned int flags, struct blk_mq_ctx *ctx) { enum hctx_type type = HCTX_TYPE_DEFAULT; /* * The caller ensure that if REQ_HIPRI, poll must be enabled. */ if (flags & REQ_HIPRI) type = HCTX_TYPE_POLL; else if ((flags & REQ_OP_MASK) == REQ_OP_READ) type = HCTX_TYPE_READ; return ctx->hctxs[type]; }
Hardware queueには4種類あり、通常の書き込みであれば HCTX_TYPE_DEFAULTが選択される。
// 198: /** * enum hctx_type - Type of hardware queue * @HCTX_TYPE_DEFAULT: All I/O not otherwise accounted for. * @HCTX_TYPE_READ: Just for READ I/O. * @HCTX_TYPE_POLL: Polled I/O of any kind. * @HCTX_MAX_TYPES: Number of types of hctx. */ enum hctx_type { HCTX_TYPE_DEFAULT, HCTX_TYPE_READ, HCTX_TYPE_POLL, HCTX_MAX_TYPES, };
tagの取得
キューからタグを取得するためには、blk_mq_get_tag関数を呼び出す。
// 90: unsigned int blk_mq_get_tag(struct blk_mq_alloc_data *data) { struct blk_mq_tags *tags = blk_mq_tags_from_data(data); struct sbitmap_queue *bt; struct sbq_wait_state *ws; DEFINE_SBQ_WAIT(wait); unsigned int tag_offset; int tag; if (data->flags & BLK_MQ_REQ_RESERVED) { if (unlikely(!tags->nr_reserved_tags)) { WARN_ON_ONCE(1); return BLK_MQ_NO_TAG; } bt = tags->breserved_tags; tag_offset = 0; } else { bt = tags->bitmap_tags; tag_offset = tags->nr_reserved_tags; } tag = __blk_mq_get_tag(data, bt); if (tag != BLK_MQ_NO_TAG) goto found_tag; if (data->flags & BLK_MQ_REQ_NOWAIT) return BLK_MQ_NO_TAG; ws = bt_wait_ptr(bt, data->hctx); do { struct sbitmap_queue *bt_prev; /* * We're out of tags on this hardware queue, kick any * pending IO submits before going to sleep waiting for * some to complete. */ blk_mq_run_hw_queue(data->hctx, false); /* * Retry tag allocation after running the hardware queue, * as running the queue may also have found completions. */ tag = __blk_mq_get_tag(data, bt); if (tag != BLK_MQ_NO_TAG) break; sbitmap_prepare_to_wait(bt, ws, &wait, TASK_UNINTERRUPTIBLE); tag = __blk_mq_get_tag(data, bt); if (tag != BLK_MQ_NO_TAG) break; bt_prev = bt; io_schedule(); sbitmap_finish_wait(bt, ws, &wait); data->ctx = blk_mq_get_ctx(data->q); data->hctx = blk_mq_map_queue(data->q, data->cmd_flags, data->ctx); tags = blk_mq_tags_from_data(data); if (data->flags & BLK_MQ_REQ_RESERVED) bt = tags->breserved_tags; else bt = tags->bitmap_tags; /* * If destination hw queue is changed, fake wake up on * previous queue for compensating the wake up miss, so * other allocations on previous queue won't be starved. */ if (bt != bt_prev) sbitmap_queue_wake_up(bt_prev); ws = bt_wait_ptr(bt, data->hctx); } while (1); sbitmap_finish_wait(bt, ws, &wait); found_tag: /* * Give up this allocation if the hctx is inactive. The caller will * retry on an active hctx. */ if (unlikely(test_bit(BLK_MQ_S_INACTIVE, &data->hctx->state))) { blk_mq_put_tag(tags, data->ctx, tag + tag_offset); return BLK_MQ_NO_TAG; } return tag + tag_offset; }
blk_mq_get_tag関数は、waitの取り扱いに考慮しながら__blk_mq_get_tag関数を呼び出すことでタグを取得することができる。
// 168: static inline struct blk_mq_tags *blk_mq_tags_from_data(struct blk_mq_alloc_data *data) { if (data->q->elevator) return data->hctx->sched_tags; return data->hctx->tags; }
tagsのポインタは、IO schedulerが登録されている場合には sched_tags を、そうでなければ tags をそのまま返す。
sbitmapへのポインタは、"reserved pool"から取得するようなフラグが立っている場合*1 、nr_reserved_tagsを、そうでなければ、bitmap_tags となる。
これらの情報を基に __blk_mq_ge_tag関数によって、タグを取得する。
// 77: static int __blk_mq_get_tag(struct blk_mq_alloc_data *data, struct sbitmap_queue *bt) { if (!data->q->elevator && !(data->flags & BLK_MQ_REQ_RESERVED) && !hctx_may_queue(data->hctx, bt)) return BLK_MQ_NO_TAG; if (data->shallow_depth) return __sbitmap_queue_get_shallow(bt, data->shallow_depth); else return __sbitmap_queue_get(bt); }
タグが取得できた場合には、found_tagラベルにジャンプして終了ルーチンに入り、そうでなければ wait queueを用いてタグが取得できるまで待つことになる。 (BLK_MQ_REQ_NOWAITを除く)
リクエストの初期化
// 284: static struct request *blk_mq_rq_ctx_init(struct blk_mq_alloc_data *data, unsigned int tag, u64 alloc_time_ns) { struct blk_mq_tags *tags = blk_mq_tags_from_data(data); struct request *rq = tags->static_rqs[tag]; if (data->q->elevator) { rq->tag = BLK_MQ_NO_TAG; rq->internal_tag = tag; } else { rq->tag = tag; rq->internal_tag = BLK_MQ_NO_TAG; } /* csd/requeue_work/fifo_time is initialized before use */ rq->q = data->q; rq->mq_ctx = data->ctx; rq->mq_hctx = data->hctx; rq->rq_flags = 0; rq->cmd_flags = data->cmd_flags; if (data->flags & BLK_MQ_REQ_PM) rq->rq_flags |= RQF_PM; if (blk_queue_io_stat(data->q)) rq->rq_flags |= RQF_IO_STAT; INIT_LIST_HEAD(&rq->queuelist); INIT_HLIST_NODE(&rq->hash); RB_CLEAR_NODE(&rq->rb_node); rq->rq_disk = NULL; rq->part = NULL; #ifdef CONFIG_BLK_RQ_ALLOC_TIME rq->alloc_time_ns = alloc_time_ns; #endif if (blk_mq_need_time_stamp(rq)) rq->start_time_ns = ktime_get_ns(); else rq->start_time_ns = 0; rq->io_start_time_ns = 0; rq->stats_sectors = 0; rq->nr_phys_segments = 0; #if defined(CONFIG_BLK_DEV_INTEGRITY) rq->nr_integrity_segments = 0; #endif blk_crypto_rq_set_defaults(rq); /* tag was already set */ WRITE_ONCE(rq->deadline, 0); rq->timeout = 0; rq->end_io = NULL; rq->end_io_data = NULL; data->ctx->rq_dispatched[op_is_sync(data->cmd_flags)]++; refcount_set(&rq->ref, 1); if (!op_is_flush(data->cmd_flags)) { struct elevator_queue *e = data->q->elevator; rq->elv.icq = NULL; if (e && e->type->ops.prepare_request) { if (e->type->icq_cache) blk_mq_sched_assign_ioc(rq); e->type->ops.prepare_request(rq); rq->rq_flags |= RQF_ELVPRIV; } } data->hctx->queued++; return rq; }
blk_mq_rq_ctx_init関数は、タグからリクエストを初期化する。

また、IOスケジューラが登録されている場合に、このタイミングでprepare_request処理を実施する。
リクエストとbioの関連付け
初期化したリクエストは blk_mq_bio_to_request関数によって bioと関連付けされる。
// 1952: static void blk_mq_bio_to_request(struct request *rq, struct bio *bio, unsigned int nr_segs) { int err; if (bio->bi_opf & REQ_RAHEAD) rq->cmd_flags |= REQ_FAILFAST_MASK; rq->__sector = bio->bi_iter.bi_sector; rq->write_hint = bio->bi_write_hint; blk_rq_bio_prep(rq, bio, nr_segs); /* This can't fail, since GFP_NOIO includes __GFP_DIRECT_RECLAIM. */ err = blk_crypto_rq_bio_prep(rq, bio, GFP_NOIO); WARN_ON_ONCE(err); blk_account_io_start(rq); }
// 624: static inline void blk_rq_bio_prep(struct request *rq, struct bio *bio, unsigned int nr_segs) { rq->nr_phys_segments = nr_segs; rq->__data_len = bio->bi_iter.bi_size; rq->bio = rq->biotail = bio; rq->ioprio = bio_prio(bio); if (bio->bi_bdev) rq->rq_disk = bio->bi_bdev->bd_disk; }
これにより、rqとbioのデータ構造が関連付けられる。

リクエストの追加
rqの初期化が完了した後は、IOリクエストの種類によって処理が異なる。
// 2240: } else if (plug && (q->nr_hw_queues == 1 || blk_mq_is_sbitmap_shared(rq->mq_hctx->flags) || q->mq_ops->commit_rqs || !blk_queue_nonrot(q))) {
今回のケースでは、nr_hw_queue == 1であり、 shared bitmapであるため、この条件分岐にマッチする。
// 2243: /* * Use plugging if we have a ->commit_rqs() hook as well, as * we know the driver uses bd->last in a smart fashion. * * Use normal plugging if this disk is slow HDD, as sequential * IO may benefit a lot from plug merging. */ unsigned int request_count = plug->rq_count; struct request *last = NULL; if (!request_count) trace_block_plug(q); else last = list_entry_rq(plug->mq_list.prev); if (request_count >= blk_plug_max_rq_count(plug) || (last && blk_rq_bytes(last) >= BLK_PLUG_FLUSH_SIZE)) { blk_flush_plug_list(plug, false); trace_block_plug(q); } blk_add_rq_to_plug(plug, rq);
この場合、blk_plugにリクエストを追加する。 (plugがmaxの場合は、事前に flush する必要がある)
blk_plugへのリクエストの追加は blk_add_rq_to_plug関数によって実施される。
// 2136: static void blk_add_rq_to_plug(struct blk_plug *plug, struct request *rq) { list_add_tail(&rq->queuelist, &plug->mq_list); plug->rq_count++; if (!plug->multiple_queues && !list_is_singular(&plug->mq_list)) { struct request *tmp; tmp = list_first_entry(&plug->mq_list, struct request, queuelist); if (tmp->q != rq->q) plug->multiple_queues = true; } }
multiple_queueを使用している場合には multiple_queuesフラグを立てる。
ただし、今回の環境では存在していないので、リストplug->mq_listに 要素rq_queuelistを追加するだけとなる。
write_inode関数から呼ばれるblk_mq_submit_bio関数
writepages関数から呼ばれた場合とシーケンスが同じになるため、省略する。
おわりに
本記事では、ブロックレイヤのblk_mq_submit_bio関数を確認した。
変更履歴
- 2022/11/26: 記事公開