はじめてのFreeBSD: インストールからカーネルモジュール作成まで
- 概要
- FreeBSDとは
- 実験環境
- FreeBSDの仮想ディスクイメージを起動
- Linux上のQEMU/KVMでFreeBSDインストーラでインストールする
- FreeBSDのユーザランドとカーネルをビルドしてインストール
- 簡単なFreeBSDカーネルモジュールを作成してロードする
- まとめ
- 参考文献
概要
本記事では、Linux上のQEMU/KVMを利用してFreeBSDを試し、ユーザランドやカーネルのビルド、さらにはカーネルモジュールの作成・ロードまで行う手順を紹介する。
Linuxユーザであっても、FreeBSD特有の概念や手順を追うことで、BSD系OSの世界を体験できると考えている。
本記事の目的は、はじめてFreeBSDを触る読者が仮想マシン上でのインストールから始め、システムをビルドして理解を深める道筋を示すことである。
FreeBSDとは
FreeBSDはBSD系UNIXを起源とするオープンソースのオペレーティングシステムである。BSD(Unix系のBerkeley Software Distribution)を由来とし、独自のBSDライセンスを採用している。Linuxと並んで広く使われるオープンソースOSであり、ネットワークの堅牢性や高いパフォーマンスが大きな特徴である。

FreeBSDでは、OSのベースシステム(ユーザランドとカーネル)を一体のプロジェクトとして開発しているため、全体の整合性を保ちやすく、品質を維持したままアップデートしやすい点が魅力でもある。さらに、大規模サーバ運用でも安定して動作し、ネットワーク関連の機能やZFSなどの先進的ファイルシステムにも強みがある。これらの特性から、個人の学習や趣味開発はもちろん、商用サービスやインフラ基盤としても根強い人気を誇っている。
実験環境
ここでは、実際にFreeBSDを試した環境を示す。 今回はLinux上にQEMU/KVMを用意し、その上でFreeBSDを動かす構成を採用した。
| 環境 | 概要 |
|---|---|
| マザーボード | ASRock B450M Steel Legend |
| CPU | AMD Ryzen 3 3300X |
| RAM | DDR4-2666 16GB ×2 |
| OS | Ubuntu Desktop 24.04.01 LTS |
| Host kernel | 6.8.0-49-generic |
| QEMU | QEMU emulator version 8.2.2 |
FreeBSDの仮想ディスクイメージを起動
本章では、公式が配布している仮想ディスクイメージをQEMU/KVMで起動する手順をまとめる。 詳細なコマンドやオプションは、読者の環境に応じて調整してほしい。
公式サイトから仮想ディスクイメージ(
FreeBSD-14.2-RELEASE-amd64.qcow2)を取得する。-
$ qemu-system-x86_64 -enable-kvm \ -smp 4 -m 8G \ -drive file=FreeBSD-14.2-RELEASE-amd64.qcow2,format=qcow2,if=virtio \ -nic user,model=e1000 \ -nographic ブートローダメニューが表示されたら 3 を押下し、loaderのプロンプトに入る。
/ ______ ____ _____ _____ | ____| | _ \ / ____| __ \ | |___ _ __ ___ ___ | |_) | (___ | | | | | ___| '__/ _ \/ _ \| _ < \___ \| | | | | | | | | __/ __/| |_) |____) | |__| | | | | | | | || | | | |_| |_| \___|\___||____/|_____/|_____/ ``` ` s` `.....---.......--.``` -/ ╔══════════ Welcome to FreeBSD ═══════════╗ +o .--` /y:` +. ║ ║ yo`:. :o `+- ║ 1. Boot Multi user [Enter] ║ y/ -/` -o/ ║ 2. Boot Single user ║ .- ::/sy+:. ║ 3. Escape to loader prompt ║ / `-- / ║ 4. Reboot ║ `: :` ║ 5. Cons: Video ║ `: :` ║ ║ / / ║ Options: ║ .- -. ║ 6. Kernel: default/kernel (1 of 1) ║ -- -. ║ 7. Boot Options ║ `:` `:` ║ ║ .-- `--. ║ ║ .---.....----. ╚═════════════════════════════════════════╝loaderのプロンプトからシリアルコンソール経由でカーネルを起動する。
set console=comconsole bootログインプロンプトが表示されたら root でログインする。
FreeBSD/amd64 (freebsd) (ttyu0) login: root
Linux上のQEMU/KVMでFreeBSDインストーラでインストールする
イメージをそのまま使うのではなく、インストーラからインストールする手順を試してみる。最終的には自前でカスタマイズできる環境を作ることを目的とする。
公式サイトからインストール用ISOイメージ
FreeBSD-14.2-RELEASE-amd64-disc1.iso)を取得する。インストール用ハードディスクイメージ(100GB)を作成する
$ qemu-img create -f qcow2 freebsd.qcow2 100Gインストーラを起動する
$ qemu-system-x86_64 -enable-kvm \ -smp 4 -m 8G \ -drive freebsd.qcow2,format=qcow2,if=virtio \ -cdrom FreeBSD-14.2-RELEASE-amd64-disc1.iso \ -boot d \ -nic user,model=e1000 \ -nographicインストールウィザードに従ってインストールを行う
インストールしたイメージを使ってFreeBSDを起動する。
$ qemu-system-x86_64 -enable-kvm \ -smp 4 -m 8G \ -drive file=freebsd.qcow2,format=qcow2,if=virtio \ -nic user,model=e1000 \ -nographic
FreeBSDのユーザランドとカーネルをビルドしてインストール
FreeBSDの特徴の一つとして、ユーザランドとカーネルを一体で管理し、再ビルドできる点が挙げられる。 ここではソースコードを取得し、実際にシステムをビルドしてインストールする流れを示す。
ソースコードの取得のために、gitパッケージをインストールする
# pkg install -y git-
# git clone https://git.FreeBSD.org/src.git /usr/src -
# cd /usr/src # make -j4 buildworld カーネルの設定ファイル(
MYKERNEL)をカスタマイズする((必要に応じてMYKERNEL内を編集する))# cd /usr/src/sys/amd64/conf # cp GENERIC MYKERNELカーネルをビルドする
# cd /usr/src # make buildkernel KERNCONF=MYKERNEL-
# make installworld # make installkernel KERNCONF=MYKERNEL システムを再起動する
# shutdown -r now
簡単なFreeBSDカーネルモジュールを作成してロードする
カーネルモジュールを自作し、システムに動的にロードする手順を確認する。Linuxでいうところのカーネルモジュール (LKM) に相当するが、FreeBSDではビルドやロードの方法が一部異なるため、以下に簡単な例を示す。
// 1: KMOD = hello SRCS = hello.c .include <bsd.kmod.mk>
// 1: #include <sys/param.h> #include <sys/kernel.h> #include <sys/module.h> #include <sys/conf.h> #include <sys/systm.h> static int hello_load(module_t mod __unused, int type, void *data __unused) { int err = 0; switch (type) { case MOD_LOAD: printf("hello: Load\n"); break; case MOD_UNLOAD: printf("hello: Unload\n"); break; case MOD_SHUTDOWN: printf("hello: Shutdown\n"); break; default: err = EOPNOTSUPP; /* Operation not supported */ break; } return err; } DEV_MODULE(hello, hello_load, NULL); MODULE_VERSION(hello, 0);
ソースファイルをコンパイルする
root@test:~/hello # makekldloadコマンドでモジュールをロードするroot@test:~/mykmod # kldload ./hello.ko hello: Load実際にロードされているモジュールを確認する
root@test:~/mykmod # kldstat Id Refs Address Size Name 1 7 0xffffffff80200000 1f3c6c0 kernel 2 1 0xffffffff82818000 3220 intpm.ko 3 1 0xffffffff8281c000 2178 smbus.ko 4 1 0xffffffff8281f000 20b8 hello.kokldunloadコマンドでモジュールをアンロードするroot@test:~/mykmod # kldunload hello.ko hello: Unload
まとめ
以上の手順を通じ、Linux上の仮想環境でFreeBSDをインストールし、OSのソースツリーをビルドし、カーネルモジュールを作成してロードするまでを試してみた。 FreeBSDはベースシステムと追加ソフトウェアを区別して管理し、カーネルとユーザランドを一貫してアップデートできる点が魅力的である。 Linuxとは異なる部分も多いため、BSD独自の思想に触れながらOSの仕組みを学べるのが大きなメリットといえる。
初めてのFreeBSD体験が、読者にとってもOSの理解を深める一助となれば幸いである。
参考文献
Raspberry Pi 4 でファイル書き込み中の USBフラッシュドライブの強制挿抜を試してみる
背景
USB(Universal Serial Bus) は、デバイス同士を接続するためのシリアルバス規格の1つであり、ストレージデバイスや入力デバイス、通信機器、マルチメディア機器など、多岐にわたる用途で利用されている。
その手軽さや汎用性の高さから、近年では家庭用や業務用のコンピュータだけでなく、組み込みシステムやIoTデバイスにも採用されている。一方で、USBデバイスには以下のような問題が発生する可能性がある。
- 意図しない切断
- 電力供給不足
- ソフトウェアの不具合
これらの問題は再挿入やリセットで復旧可能な場合が多いが、USBストレージデバイスではデータ損失のリスクが高まる。 ただし、USBストレージデバイスのような不揮発性メモリを使用している場合、復旧が難しくなることもある。
例えば、USBストレージデバイスがファイルシステムに書き込んでいる最中に切断すると、以下のような問題が発生する恐れがある。
- 書き込み中のデータ損失
- ファイルシステムの破損
- システムクラッシュや予期しない動作
これらの問題を未然に防ぐためには、USBデバイスの不意の切断や再接続によるリスクを理解し、それを考慮したソフトウェア設計が必要である。 本記事では、Raspberry Pi 4を使用してUSBストレージデバイスを対象とした強制挿抜テストを実施し、その影響を評価した。
目的
本記事では、Raspberry Pi 4に接続されたUSBフラッシュドライブを対象に強制挿抜テストを行い、以下の3つの観点からシステムへの影響を確認した。
- システムの復旧性: デバイスを再接続後、システムが正常に認識し、動作を再開できるか
- ファイルシステムの復旧性: デバイスを再接続後、ファイルシステムが利用可能な状態であるか
- データの復旧性: ファイルシステム内のファイルやディレクトリを回収できるか
これにより、LinuxシステムにおけるUSBデバイスの強制挿抜リスクを理解し、安全性と信頼性を向上させるための運用設計の指針を提供することを目指した。
実行環境
Raspberry Pi 4はmicroSDカード経由でRaspberry Pi OSを起動する。 評価対象のUSBフラッシュドライブはUSB 3.0ポートに接続する。

以下に、使用するRaspberry Pi 4と関連コンポーネントのスペックを示す。
| 項目 | Raspberry Pi 4 |
|---|---|
| CPU | Cortex-A72 (ARM v8) 1.5GHz |
| メモリ | 4GB LPDDR4-3200 |
| micro SD card | KTHN-MW016G |
| OS | Raspberry Pi OS (Oct 22nd 2024) |
| Linux kernel | 6.6.51 |
| fsck.vfat | dosfstools 4.2 |
| fsstress | ltp@ec41611 |
| USB 3.0 (1) | USM32GU |
| ファイルシステム | FAT32 |
実験概要
Raspberry Pi 4に接続したUSBストレージデバイスへのファイル書き込み中に強制抜去し、そのときのストレージ状態からシステムへの影響を評価する。
以下に、今回の実験でポイントとなる要素を挙げる。
- USBデバイスの論理的な挿抜: 物理的な負担を避けるため、ソフトウェアレベルでUSBデバイスの接続や切断をシミュレートした。
- 負荷プログラム:
ファイルシステムに対するランダムな操作をシミュレートするため、
fsstressを使用した。 - システムへの影響度の評価方法: システムの状態を5段階に分類し、それぞれの影響を評価した。
USBデバイスの論理的な挿抜
物理的な抜き差しはデバイスやポートに負担を与えるため、LinuxのUSBサブシステムを利用して論理的に挿抜をシミュレートした。 今回の実験では、USBデバイスを頻繁に挿抜する必要がある。 しかし、これをすべて手作業で行うのは非現実的であり、デバイスやポートへの物理的な負担も懸念される。 そこで、実際にUSBデバイスを物理的に抜き差しするのではなく、ソフトウェアレベルで挿抜をシミュレートする方法を用いる。
LinuxのUSBサブシステムでは、USBデバイスが検出されると、自動的に適切なドライバにバインド(bind)され、Linuxから操作可能な状態にセットアップされる。 一方、Linuxではユーザ空間から特定のUSBデバイスを手動でドライバにバインドしたり、逆にアンバインド(unbind)したりすることができる。 この操作により、USBデバイスを論理的に挿抜(接続または切断) するような制御ができる。
以下は、Bus 1, Port 1, Config 1, Interface 2に接続されたUSBデバイスを手動でドライバにバインドする例である。
pi@raspberrypi:~$ echo -n "1-1:1.2" > /sys/bus/usb/drivers/usb/bind
次に、同じデバイスを手動でドライバからアンバインドする例を示す。
pi@raspberrypi:~$ echo -n "1-1:1.2" > /sys/bus/usb/drivers/usb/unbind
負荷プログラム
ストレージにどのようなデータを保存するか、そのデータをどのように取り扱うかはユーザによって異なる。 今回の実験で、すべてのユースケースを網羅することは現実的でないため、負荷プログラムを利用することで代用する。
fsstressはXFSテストスイートとして開発されたファイルシステム負荷プログラムであり、Linux Test Project (LTP) の一部として提供されている。 このプログラムは、ファイルシステムの耐久性や信頼性をテストするために、さまざまなファイル操作をシミュレートして負荷をかけるツールである。 多くのオプションが提供されており、アクセスパターンや操作回数などを自由に調整できるため、初心者でも簡単に利用できるのが特徴である。
Raspberry Pi 4 では4つのコアを持つため、プロセスを4つ生成して負荷プログラムをかける。
以下は、ディレクトリ/mnt/testに対して、4つのプロセスが並列してランダムなファイル操作を行う例である。
pi@raspberrypi:~$ fsstress -p 4 -z -n 1000 -d /mnt/test
システムへの影響度の評価方法
データの重要性や扱い方はユーザによって異なるため、システム破損状態の深刻度を定量的に測定することはできない。 そこで、今回の実験では次の5つの状態を独自に定義し、それぞれの状態からシステムへの影響度を評価する。
- 致命的なエラー(Fatal Error): デバイスが物理的または論理的に重大な破損を受け、システムから完全に認識されなくなる状態
- 重大なエラー(Serious Error): デバイス上のファイルシステムがマウントできなくなるくらい破損してしまった状態
- 中度なエラー(Moderate Error): デバイス上のファイルシステムにある一部のファイルやディレクトリが読み取りできなくなった状態
- 軽度なエラー(Mild Error): ファイルシステム内のファイルやディレクトリがすべて読み取り可能であるものの、一部のファイルが正しく動作しない、あるいはファイル名や内容が破損している状態。
- 問題なし(Fine): fsck.vfatによる整合性チェックで問題ないと確認された状態

それぞれの状態を判断する際に使用する具体的な手順は以下の通りである。
デバイスの認識確認: 次のコマンドでデバイスファイルの存在を確認する。
pi@raspberrypi:~$ test -e /dev/sdaファイルシステムのマウント確認: 読み取り専用でマウントを試みる。
pi@raspberrypi:~$ mount -o ro /dev/sda /mntファイルやディレクトリの読み取り確認: ファイルシステム内の全ファイルとディレクトリを再帰的に読み取る。
pi@raspberrypi:~$ ls -laR /mnt pi@raspberrypi:~$ find /mnt -type f -exec cat {} +ファイルシステムの整合性確認: fsck.vfatコマンドを使用する。この際、FATファイルシステムが設定するdirty volume flagsに関する情報は無視するものとする。以下は具体例である。
pi@raspberrypi:~$ fsck.vfat -n /dev/sda There are differences between boot sector and its backup. This is mostly harmless. Differences: (offset:original/backup) 65:01/00 Not automatically fixing this. Dirty bit is set. Fs was not properly unmounted and some data may be corrupt. Automatically removing dirty bit.
実験準備
実験を実施するために、以下の手順で環境を整備した。
サンプルプログラムのビルド
開発マシンでLTP(Linux Test Project) のビルドを行い、fsstressをRaspberry Pi 4上で実行可能にした。
開発マシンにLTPのビルドに必要なパッケージと AArch64用のクロスコンパイラをインストールする
user@builder:~$ sudo apt install gcc git make pkgconf autoconf automake bison flex m4 linux-headers-$(uname -r) user@builder:~$ sudo apt install libc6-dev crossbuild-essential-arm64開発マシンにLTPをダウンロードし、AArch64用のビルドの設定する
user@builder:~$ git clone --recurse-submodules https://github.com/linux-test-project/ltp.git user@builder:~$ cd ltp user@builder:~$ make autotools user@builder:~/ltp$ ./configure --host=aarch64-linux-gnu開発マシンでfsstressをビルドする
user@builder:~/ltp$ cd testcases/kernel/fs/fsstress user@builder:~/ltp/testcases/kernel/fs/fsstress$ make
ビルド成果物の fsstress を、Raspberry Pi 4 の /usr/local/binにコピーする。
USBデバイスの接続
USBフラッシュドライブをRaspberry Pi 4に接続した。 以下のコマンドで接続状態を確認し、アドレス情報を取得した。
Raspberry Pi 4 にUSBフラッシュドライブを接続する
pi@raspberrypi:~$ lsusb -t /: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/4p, 5000M |__ Port 1: Dev 2, If 0, Class=Mass Storage, Driver=usb-storage, 5000M /: Bus 01.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/1p, 480M |__ Port 1: Dev 2, If 0, Class=Hub, Driver=hub/4p, 480M
USBフラッシュドライブは、Bus 2, Port 1 のUSBハブに繋がっていることが確認できる。
これらの値はこの後に使用するため、シェル変数USB_ADDRに代入しておく
pi@raspberrypi:~$ USB_ADDR=$(dmesg | awk '/usb [0-9]+-[0-9]+:/ && /Product: Storage Media/ {sub(/.*usb /, ""); sub(/:.*/, ""); print; exit}')
また、このUSBフラッシュドライブのブロックデバイスファイルもシェル変数DEVICE_FILEに代入しておく。
pi@raspberrypi:~$ DEVICE_FILE=$(readlink -f /dev/disk/by-path/platform-fd500000.pcie-pci-0000:01:00.0-usb-0:1:1.0-scsi-0:0:0:0)
実験手順
マウントポイント用のテンポラリディレクトリを作成する
TMPDIR="$(mktemp -d)"-
mkfs.vfat ${DEVICE_FILE} FAT32フラッシュドライブでフォーマットされたUSBフラッシュドライブをマウントする
mount -t vfat ${MNTOPT} ${DEVICE_FILE} ${TMPDIR}テスト用のディレクトリを作成しておく
mkdir ${TMPDIR}/test; sync負荷プログラムをバッググラウンドプロセスとして実行させる
fsstress -p 4 -z -n 1000 -d ${TMPDIR}/test &ランダムな時間(0〜59秒) 経過後に、USBデバイスを強制抜去する
sleep $((RANDOM % 60)); echo -n ${USB_ADDR} > /sys/bus/usb/drivers/usb/unbind負荷プログラムを終了させる
pkill -9 fsstressマウントされていたFAT32ファイルシステムをアンマウントする
umount ${TMPDIR}USBデバイスを再度、挿入する
echo -n ${USB_ADDR} > /sys/bus/usb/drivers/usb/bindUSBフラッシュドライブ上のファイルシステム状態を確認する
fsck.vfat -n ${DEVICE_FILE} mount -o ro ${DEVICE_FILE} ${TMPDIR} ls -lAR ${TMPDIR} find ${TMPDIR} -type f -exec cat {} + umount ${DEVICE_FILE}
実験結果
本実験では、マウントオプション(${MNTOPT}) を -o defaults と -o sync の2種類で設定し、それぞれ1000回の強制抜去テストを実施した。
システムへの影響度は 「実験概要」 で示した5段階(致命的なエラー、重大なエラー、中度なエラー、軽度なエラー、問題なし) に基づいて分類した。
以下のグラフは、強制抜去までの時間(横軸)とシステムへの影響度の発生回数(縦軸)を示しており、-o defaults と-o syncの結果を比較する。
デフォルトの結果

中度なエラー(Moderate Error) ファイルやディレクトリが正常に読めなくなるケースが多発し、全体の約80%を占めた。
軽度なエラー(Mild Error) 強制抜去までの時間が短い(5秒未満)場合に多く発生し、全体の約15%を占めた。
問題なし(Fine) 問題なしと判定されたケースは非常に少なく、全体の約5%に留まった。
syncオプションの結果

中度なエラー(Moderate Error)
稀に発生し、全体の約0.2%に留まった。軽度なエラー(Mild Error)
ファイルやディレクトリが正常に読み取り可能なケースが支配的であり、全体の約98%を占めた。問題なし(Fine)
問題なしと判定されたケースは全体の約1%に留まった。
考察
Linuxでは、ファイルへの書き込みにwriteback方式が採用されている。 writeback方式では、アプリケーションからの書き込み要求が即座にストレージへ反映されるわけではなく、一時的にカーネルのページキャッシュに蓄えられ、その後適切なタイミングでまとめてディスクへ反映される。 この方式はシステム性能の向上に寄与する一方で、システムの異常終了やデバイスの強制抜去といった予期しない状況下ではリスクを伴う。
特に、以下の問題が生じる可能性がある。
- データのキャッシュ残存: 書き込みデータがキャッシュに残ったままストレージに反映されない場合、データ損失が発生する。
- メタデータの不完全更新: ファイルシステムのメタデータ更新が未完了の状態で抜去が行われると、ファイルシステム全体の不整合を招く。
writeback方式の特徴として、データがキャッシュにとどまったままストレージに反映されない場合、データ損失が発生することがある。また、ファイルシステムのメタデータ更新が未完了の状態で抜去が行われると、ファイルシステム全体の不整合を招く可能性が高い。
FAT32ファイルシステムの特性リスク
本実験で使用したFAT32ファイルシステムは、以下の3つの領域で構成されている。
- Reserved Region: ファイルシステム全体のメタデータを格納
- FAT Region: ファイルやディレクトリが占有するクラスタの繋がり(チェイン)を管理
- Data Region: ファイルやディレクトリ本体のデータが実際に格納される領域

FAT32ファイルシステムはジャーナリング機能のような機能を持たないため、システムの異常終了やデバイスの強制抜去が発生した場合、以下のようなリスクが生じる。
- Reserved Regionの破損: ファイルシステム全体がマウント不能になる重大なエラーを引き起こす。
- FAT Regionの破損: 一部または全てのファイルやディレクトリが見えなくなる。
- Data Regionの破損: ファイルの内容が破損し、読み取り不能になる。
これらの領域が持つ役割のいずれかが更新途中で停止すると、FAT32ファイルシステム全体に深刻な影響を及ぼす可能性が高い。
syncオプションと中度なエラー
LinuxのVFATファイルシステムで-o syncオプションを指定することで、データが即座にストレージに反映されるため、writeback方式によるキャッシュ残存リスクを低減できる。
しかし、同期I/Oであっても書き込み操作がアトミックではないため、強制抜去のタイミングによっては以下の問題が発生する。
非アトミック性による不整合
FAT Region や Data Region の更新が途中で停止した場合、データやクラスタチェインが不完全な状態で保存される。 このため、一部のファイルやディレクトリが正常にアクセスできなくなる中度なエラーが発生する。
デバイス固有の特性
使用しているストレージデバイスの内部キャッシュ機能や、摩耗による書き込みセルの劣化もエラーの一因となる。 特に、仕様違反や低品質のデバイスでは、OSが要求する同期書き込みが正しく実行されない場合がある。
高負荷環境下での競合
fsstressのような高負荷操作を並行実行している環境では、複数の書き込み処理が競合し、不完全な更新が発生するリスクが高まる
まとめ
本実験を通じて、USBストレージデバイスにおける異常抜去リスクに対する深い理解が得られた。
-o syncオプションは信頼性を向上させる有効な手段であるが、完全な安全性を保証するものではない。
そのため、耐障害性が求められるシステムでは、ジャーナリングなどの機能を持つファイルシステムの採用や、高品質なデバイスの利用を推奨する。また、運用ポリシーの見直しやバックアップ体制の強化が不可欠である。
変更履歴
- 2024/12/12: 記事公開
参考文献
Linuxカーネルのファイルアクセスの処理を追いかける (24) MMC: mmc_blk_probe
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、MMCブロックシステムの初期化処理について確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
MMCブロックの Probe
カーネルがMMCデバイスを認識したとき、mmc_probe関数が呼ばれる。
このとき、ブロックデバイスとして扱う必要がある場合には、MMCブロックのprobe処理も必要になる。
MMCメモリカード追加によって呼び出されるdevice_add関数では、関連コンポーネントの probeを実施する。
MMCバスのProbe処理によって、MMCブロックのProbe mmc_blk_probe関数を実施する。
mmc_blk_probe関数の定義は次のようになっている。
// 2885: static int mmc_blk_probe(struct mmc_card *card) { struct mmc_blk_data *md; int ret = 0; /* * Check that the card supports the command class(es) we need. */ if (!(card->csd.cmdclass & CCC_BLOCK_READ)) return -ENODEV; mmc_fixup_device(card, mmc_blk_fixups); card->complete_wq = alloc_workqueue("mmc_complete", WQ_MEM_RECLAIM | WQ_HIGHPRI, 0); if (!card->complete_wq) { pr_err("Failed to create mmc completion workqueue"); return -ENOMEM; } md = mmc_blk_alloc(card); if (IS_ERR(md)) { ret = PTR_ERR(md); goto out_free; } ret = mmc_blk_alloc_parts(card, md); if (ret) goto out; /* Add two debugfs entries */ mmc_blk_add_debugfs(card, md); pm_runtime_set_autosuspend_delay(&card->dev, 3000); pm_runtime_use_autosuspend(&card->dev); /* * Don't enable runtime PM for SD-combo cards here. Leave that * decision to be taken during the SDIO init sequence instead. */ if (card->type != MMC_TYPE_SD_COMBO) { pm_runtime_set_active(&card->dev); pm_runtime_enable(&card->dev); } return 0; out: mmc_blk_remove_parts(card, md); mmc_blk_remove_req(md); out_free: destroy_workqueue(card->complete_wq); return ret; }
mmc_blk_probe関数では、MMCメモリカードをブロックデバイスとしてアクセスできるようにセットアップする関数である。
MMCメモリカードのプロパティや状態を管理している cardを引数として受け取り、この関数が正常に完了(return 0)すると、LinuxカーネルがMMCデバイスをブロックデバイスとして扱えるようになる。
この関数では、以下の処理を実施する。
それぞれの処理について、順番に確認していく。
特定のデバイスに対する調整
MMCメモリカードやSDメモリカードなどのメディアでは、メーカーごとにハードウェア固有の調整や設定が追加で必要となることもある。
mmc_fixup_device関数では、事前に登録された fixupリストを参照して、該当デバイスが追加の修正が必要かどうかを確認し、必要に応じて適用する。
// 148: static inline void mmc_fixup_device(struct mmc_card *card, const struct mmc_fixup *table) { const struct mmc_fixup *f; u64 rev = cid_rev_card(card); for (f = table; f->vendor_fixup; f++) { if ((f->manfid == CID_MANFID_ANY || f->manfid == card->cid.manfid) && (f->oemid == CID_OEMID_ANY || f->oemid == card->cid.oemid) && (f->name == CID_NAME_ANY || !strncmp(f->name, card->cid.prod_name, sizeof(card->cid.prod_name))) && (f->cis_vendor == card->cis.vendor || f->cis_vendor == (u16) SDIO_ANY_ID) && (f->cis_device == card->cis.device || f->cis_device == (u16) SDIO_ANY_ID) && (f->ext_csd_rev == EXT_CSD_REV_ANY || f->ext_csd_rev == card->ext_csd.rev) && rev >= f->rev_start && rev <= f->rev_end) { dev_dbg(&card->dev, "calling %ps\n", f->vendor_fixup); f->vendor_fixup(card, f->data); } } }
MMCメモリカード系の fixupリストは drivers/mmc/core/quirks.h で定義されている。
今回の環境は fixup の必要がないため、詳細は割愛する。
完了通知の Work Queue
MMCサブシステムでは、ホストコントローラがMMCコマンドなどが完了した後に、上位層に通知をするために Work Queue mmc_complete が用意されている。
この Work Queue mmc_complete は、上位層のページキャッシュを回収することがあるために、 WQ_MEM_RECLAIM | WQ_HIGHPRIフラグを付与しておく。
MMCブロックデバイスの初期化
Linuxカーネルでは、MMC デバイスに対応するブロックデバイス構造体(mmc_blk_data)が用意されており、mmc_blk_alloc関数で初期化と設定をする。
// 2455: static struct mmc_blk_data *mmc_blk_alloc(struct mmc_card *card) { sector_t size; if (!mmc_card_sd(card) && mmc_card_blockaddr(card)) { /* * The EXT_CSD sector count is in number or 512 byte * sectors. */ size = card->ext_csd.sectors; } else { /* * The CSD capacity field is in units of read_blkbits. * set_capacity takes units of 512 bytes. */ size = (typeof(sector_t))card->csd.capacity << (card->csd.read_blkbits - 9); } return mmc_blk_alloc_req(card, &card->dev, size, false, NULL, MMC_BLK_DATA_AREA_MAIN, 0); }
mmc_blk_alloc関数は、容量(セクタ数) を計算するだけとなっており、その結果を mmc_blk_alloc_req関数となっている。
SDメモリカードでは利用されないが、e.MMC は Extended Card Specific Data (EXT_CSD) レジスタに、カード固有のパラメータ(容量や書き込みモード、セキュリティ設定など)に関する情報が格納差されている。そのため、EXT_CSD レジスタから取得した値を size に設定する。
一方で、SDメモリカードでは Card Specific Data (CSD) レジスタに、カードの基本情報や機能情報が格納されている。
そのため、 CSDレジスタから取得した値をread_blkbitsから 512バイト単位で size に設定する。
こうして得られた size と他パラメータを使って、mmc_blk_alloc_req関数を呼び出す。
// 2336: static struct mmc_blk_data *mmc_blk_alloc_req(struct mmc_card *card, struct device *parent, sector_t size, bool default_ro, const char *subname, int area_type, unsigned int part_type) { struct mmc_blk_data *md; int devidx, ret; char cap_str[10]; devidx = ida_simple_get(&mmc_blk_ida, 0, max_devices, GFP_KERNEL); if (devidx < 0) { /* * We get -ENOSPC because there are no more any available * devidx. The reason may be that, either userspace haven't yet * unmounted the partitions, which postpones mmc_blk_release() * from being called, or the device has more partitions than * what we support. */ if (devidx == -ENOSPC) dev_err(mmc_dev(card->host), "no more device IDs available\n"); return ERR_PTR(devidx); } md = kzalloc(sizeof(struct mmc_blk_data), GFP_KERNEL); if (!md) { ret = -ENOMEM; goto out; } md->area_type = area_type; /* * Set the read-only status based on the supported commands * and the write protect switch. */ md->read_only = mmc_blk_readonly(card); md->disk = mmc_init_queue(&md->queue, card); if (IS_ERR(md->disk)) { ret = PTR_ERR(md->disk); goto err_kfree; } INIT_LIST_HEAD(&md->part); INIT_LIST_HEAD(&md->rpmbs); kref_init(&md->kref); md->queue.blkdata = md; md->part_type = part_type; md->disk->major = MMC_BLOCK_MAJOR; md->disk->minors = perdev_minors; md->disk->first_minor = devidx * perdev_minors; md->disk->fops = &mmc_bdops; md->disk->private_data = md; md->parent = parent; set_disk_ro(md->disk, md->read_only || default_ro); md->disk->flags = GENHD_FL_EXT_DEVT; if (area_type & (MMC_BLK_DATA_AREA_RPMB | MMC_BLK_DATA_AREA_BOOT)) md->disk->flags |= GENHD_FL_NO_PART_SCAN | GENHD_FL_SUPPRESS_PARTITION_INFO; /* * As discussed on lkml, GENHD_FL_REMOVABLE should: * * - be set for removable media with permanent block devices * - be unset for removable block devices with permanent media * * Since MMC block devices clearly fall under the second * case, we do not set GENHD_FL_REMOVABLE. Userspace * should use the block device creation/destruction hotplug * messages to tell when the card is present. */ snprintf(md->disk->disk_name, sizeof(md->disk->disk_name), "mmcblk%u%s", card->host->index, subname ? subname : ""); set_capacity(md->disk, size); if (mmc_host_cmd23(card->host)) { if ((mmc_card_mmc(card) && card->csd.mmca_vsn >= CSD_SPEC_VER_3) || (mmc_card_sd(card) && card->scr.cmds & SD_SCR_CMD23_SUPPORT)) md->flags |= MMC_BLK_CMD23; } if (mmc_card_mmc(card) && md->flags & MMC_BLK_CMD23 && ((card->ext_csd.rel_param & EXT_CSD_WR_REL_PARAM_EN) || card->ext_csd.rel_sectors)) { md->flags |= MMC_BLK_REL_WR; blk_queue_write_cache(md->queue.queue, true, true); } string_get_size((u64)size, 512, STRING_UNITS_2, cap_str, sizeof(cap_str)); pr_info("%s: %s %s %s %s\n", md->disk->disk_name, mmc_card_id(card), mmc_card_name(card), cap_str, md->read_only ? "(ro)" : ""); /* used in ->open, must be set before add_disk: */ if (area_type == MMC_BLK_DATA_AREA_MAIN) dev_set_drvdata(&card->dev, md); device_add_disk(md->parent, md->disk, mmc_disk_attr_groups); return md; err_kfree: kfree(md); out: ida_simple_remove(&mmc_blk_ida, devidx); return ERR_PTR(ret); }
mmc_blk_alloc_req関数では、MMCブロックデバイスに対するリクエストで必要となるデータ構造(mmc_blk_data)のリソースを割り当て、初期化するための関数となっている。
この関数では、MMCブロックデバイス構造体の様々なメンバーが初期化されるが、分類で分けて考えていく。
- IDA (ID Allocator) による ID取得
- kzalloc関数による構造体の割り当て
- mmc queueの初期化と紐づけ ((
mmc_init_queue関数は次回以降で確認する)) - デバイスの登録:
- その他のパラメータ設定
Linuxでは、ID Allocator (IDA) と呼ばれる仕組みによって識別子を割り当てができる。
MMCブロックデバイスの識別子に IDR (mmc_blk_ida) を使用する。
これによって、最初に識別されたMMCブロックデバイスは0、次に識別されたMMCブロックデバイスは1となる。
mmc_blk_data型のmdの領域(376バイト)は kzalloc関数で確保する。
このデータmdは、mmc_blk_alloc_req関数とそこで呼び出される mmc_init_queue関数によって初期化される。

MMCメモリカードやSDメモリカードでは、ブロック単位でデータを管理する。 この時、ブロックごとに書き込みする方式 (CMD17, CMD24) 以外にも、複数のブロックを書き込みする方式 (CMD18, 25) が定義されている。
SDメモリカードでは、UHS104 や SDXC 向けのコマンドが用意されており、CMD23はこれに該当する。 どのコマンドがサポートされているかどうかは、SCRのフィールドにで管理されている。

また、MMCメモリカードでは Reliable Write と呼ばれるデータの信頼性を保証するためにMMCが提供する書き込み操作の一種である。 Reliable Write は、CMD23の引数内で特定のビットを設定することで有効化することができる。
そこで、カードが Reliable Writeをサポートしているかどうか(EXT_CSD_WR_REL_PARAM) とReliable Writeの書き込み単位 (MMC_BLK_REL_WR) を確認する。
Reliable Writeがサポートされている場合には、blk_queue_write_cache 関数でリクエストキューに対して書き込みキャッシュ(wc)とFUAfuaを有効化する。

パラメータを初期化した後に、ブロックデバイスをシステムに登録するためにdevice_add_disk関数を呼び出す。
この関数は、ブロックデバイスをカーネルのデバイスモデルに追加し、ユーザ空間からそのディスクをアクセスできるようにすることを目的とする。 これ以外にも、次のような役割もあるがここでは割愛する。
- ディスクキューの初期化
- 関連するイベントの通知
- デバイスノードの作成
MMC物理パーティション
mmc_blk_alloc_parts 関数は、MMCデバイスのパーティションの初期化と管理する。
// 2654: static int mmc_blk_alloc_parts(struct mmc_card *card, struct mmc_blk_data *md) { int idx, ret; if (!mmc_card_mmc(card)) return 0; for (idx = 0; idx < card->nr_parts; idx++) { if (card->part[idx].area_type & MMC_BLK_DATA_AREA_RPMB) { /* * RPMB partitions does not provide block access, they * are only accessed using ioctl():s. Thus create * special RPMB block devices that do not have a * backing block queue for these. */ ret = mmc_blk_alloc_rpmb_part(card, md, card->part[idx].part_cfg, card->part[idx].size >> 9, card->part[idx].name); if (ret) return ret; } else if (card->part[idx].size) { ret = mmc_blk_alloc_part(card, md, card->part[idx].part_cfg, card->part[idx].size >> 9, card->part[idx].force_ro, card->part[idx].name, card->part[idx].area_type); if (ret) return ret; } } return 0; }
e·MMCでは、パーティションの構成が仕様として規定されている。

2つのブートパーティションと1つのReplay Protected Memory Block(RPMB)パーティション、1つのユーザエリアパーティションから構成される。
Linuxカーネルからは RPMBパーティションとユーザエリアパーティション を取り扱う。
mmc_blk_alloc_parts関数では、これがパーティション内にあるかどうかを確認し、必要に応じて初期化・設定する。
debugfsにエントリの追加
mmc_blk_add_debugfs 関数は、メモリカードのデバッグ情報を debugfs として提供する。
// 2825: static int mmc_blk_add_debugfs(struct mmc_card *card, struct mmc_blk_data *md) { struct dentry *root; if (!card->debugfs_root) return 0; root = card->debugfs_root; if (mmc_card_mmc(card) || mmc_card_sd(card)) { md->status_dentry = debugfs_create_file_unsafe("status", 0400, root, card, &mmc_dbg_card_status_fops); if (!md->status_dentry) return -EIO; } if (mmc_card_mmc(card)) { md->ext_csd_dentry = debugfs_create_file("ext_csd", S_IRUSR, root, card, &mmc_dbg_ext_csd_fops); if (!md->ext_csd_dentry) return -EIO; } return 0; }
mmc_blk_add_debugfs関数で登録するエントリは次の2つである。
デバイスの runtime PM を有効化
Linux では、Runtime Power Management (Runtime PM) のためのフレームワークが用意されており、必要に応じて消費電力を削減することに貢献する。
MMCブロックでも Runtime Power Management のサポートされており、probe時に設定する。
pm_runtime_use_autosuspend関数は、デバイスで自動サスペンド機能を有効にする。
自動サスペンドまでの待機時間は、pm_runtime_set_autosuspend_delay関数で3秒に設定されている。
ただし、これらは SDIO のような コンボカードでは適用されない。
runtime PM を有効にするためには、pm_runtime_set_active関数で"active"ステータスに設定したうえで、pm_runtime_enable関数で有効化する。
おわりに
本記事では、MMCブロックのprobeで呼び出される mmc_blk_probe関数について確認した。
この関数では、e·MMCやSDメモリカードなどブロックデバイスとしての初期化ロジックが組み込まれている。
変更履歴
- 2024/11/30: 記事公開
参考
- SD and MMC Device Partitions — The Linux Kernel documentation
- SD や MMC のパーティションについて
- Runtime Power Management Framework for I/O Devices — The Linux Kernel documentation
- LinuxにおけるRuntime PMの仕組みについて
- Device Power Management Basics — The Linux Kernel documentation
- デバイスの電源管理について
- 【FileSystem】車載外部ストレージ その11【SDカード⑦】 | シミュレーションの世界に引きこもる部屋
- SDメモリカードにおけるMultiple blockについて
Raspberry Pi 4 で OverlayFS を併用した Read-Only な rootfs を構築する
背景
組込み機器では、セキュリティやストレージデバイスの摩耗を抑えるなどといった観点からルートファイルシステムを読み取り専用にすることがある。
Raspberry Pi OS では、raspi-configで overlayroot によってルートファイルシステムを読み取り専用に変更することができる。
overlayroot では、既存のルートファイルシステムに OverlayFS を導入しやすくするのツールの一つである。 このパッケージによって読み取り専用となったルートファイルシステムに対して、tmpfsのような一時ファイルシステムを上位のレイヤに追加することで、達成することができる。

Linux では、読み取り専用ファイルシステムがいくつかサポートしている。 こういったファイルシステムは、読み取り専用に設計されているため、圧縮や重複除去といった機能がサポートされている。 Android では、SquashFS(Android 9 以前)、EROFS をシステムパーティションとして利用している。
本稿では、Raspberry Pi 4 のルートファイルシステムを読み取り専用に変更し、そのうえで SquashFS や EROFS として作成することを目指す。
実行環境
Raspberry Pi 4 は microSDカード経由でRaspberry Pi OSを起動させる。

ここで使用するRaspberry Pi 4のスペックについて、必要な情報だけ抜粋したものを下記に示す。
| 項目 | Raspberry Pi 4 |
|---|---|
| CPU | Cortex-A72 (ARM v8) 1.5GHz |
| メモリ | 4GB LPDDR4-3200 |
| OS | Raspberry Pi OS (Mar 15th 2024) |
| Linux kernel | 6.6.261 |
| micro SD card | KTHN-MW016G |
ファイルシステムを Read-Only化する
raspi-configから Non-Interactiveモードで OverlayFS による Read-Only な rootfs を有効化する。(必要であれば追加パッケージのインストールされる)pi@raspberrypi:~$ sudo raspi-config nonint enable_overlayfsシステムを再起動する
pi@raspberrypi:~$ sudo systemctl reboot再起動後にシステムのマウント状況を確認する
pi@raspberrypi:~$ mount | grep -E 'mmc|root-ro|root-rw' /dev/mmcblk0p2 on /media/root-ro type ext4 (ro,relatime) tmpfs-root on /media/root-rw type tmpfs (rw,relatime) overlayroot on / type overlay (rw,relatime,lowerdir=/media/root-ro,upperdir=/media/root-rw/overlay,workdir=/media/root-rw/overlay-workdir/_,uuid=on) /dev/mmcblk0p1 on /boot/firmware type vfat (rw,relatime,fmask=0022,dmask=0022,codepage=437,iocharset=ascii,shortname=mixed,errors=remount-ro)
読み取り専用ファイルシステムを使用する
ルートファイルシステムをSquashFSに変更する
SquashFS は 読み取り専用の圧縮ファイルシステムとなっており、ファイルやディレクトリ、それらメタデータを圧縮することができる。(gzip/xz/lzo/zstdなどがサポートされている)
SquashFSファイルシステムを作成するためには、mksquashfs プログラムを使用する必要がある。 mksquashfs では、圧縮アルゴリズムの選択や作成されるファイルシステムのメタ情報を調整することができる。
ここでは、デフォルトのパラメータ(gzipによる圧縮)でSquashFSファイルシステムを作成する。
Raspberry Pi OS の SDメモリカードのイメージをバックアップする
$ sudo dd if=/dev/sdd1 of=bootfs.img $ sudo dd if=/dev/sdd2 of=rootfs.img-
$ sudo mksquashfs /mnt/ rootfs_gzip.sfs 作成したSquashFSファイルシステムを SDメモリカードに書き込む
$ sudo dd if=rootfs_gzip.sfs of=/dev/sdd2
また、overlayrootのインストールによって、カーネルコマンドラインにも変更が加わっている。
SquashFSでマウントするように次のような修正をする。
// 1: --- cmdline.txt.orig 2024-05-05 17:51:26.000000000 +0900 +++ cmdline.txt 2024-05-05 17:51:50.000000000 +0900 @@ -1 +1 @@ -overlayroot=tmpfs console=serial0,115200 console=tty1 root=PARTUUID=9e2953b9-02 rootfstype=ext4 fsck.repair=yes rootwait quiet splash plymouth.ignore-serial-consoles cfg80211.ieee80211_regdom=JP +overlayroot=tmpfs console=serial0,115200 console=tty1 root=PARTUUID=9e2953b9-02 rootfstype=squashfs fsck.repair=yes rootwait quiet splash plymouth.ignore-serial-consoles cfg80211.ieee80211_regdom=JP
このSDメモリカードを Raspberry Pi 4 を起動させたとき、SquashFSでマウントされていることが確認できる。
pi@raspberrypi:~$ mount | grep 'mmcblk0p2'
/dev/mmcblk0p2 on /media/root-ro type squashfs (ro,relatime,errors=continue)
ルートファイルシステムをEROFSに変更する
EROFS も 読み取り専用の(圧縮)ファイルシステムとなっており、ファイルやディレクトリ、それらメタデータを圧縮することができる。(lz4/lzmaなどがサポートされている)
SquashFSファイルシステムを作成するためには、mkfs.erofs プログラムを使用する必要がある。 mkfs.erofs では、圧縮アルゴリズムの選択や作成されるファイルシステムのメタ情報を調整することができる。
ここでは、デフォルトのパラメータ(非圧縮)でSquashFSファイルシステムを作成する。
EROFSファイルシステムを作成する
$ sudo mkfs.erofs rootfs.erofs /mnt作成したEROFSファイルシステムを SDメモリカードに書き込む
$ sudo dd if=rootfs.erofs of=/dev/sdd2
また、EROFSでマウントするようにカーネルコマンドラインを次のような修正をする。
// 1: --- cmdline.txt.orig 2024-05-05 17:51:26.000000000 +0900 +++ cmdline.txt 2024-05-05 17:51:50.000000000 +0900 @@ -1 +1 @@ -overlayroot=tmpfs console=serial0,115200 console=tty1 root=PARTUUID=9e2953b9-02 rootfstype=ext4 fsck.repair=yes rootwait quiet splash plymouth.ignore-serial-consoles cfg80211.ieee80211_regdom=JP +overlayroot=tmpfs console=serial0,115200 console=tty1 root=PARTUUID=9e2953b9-02 rootfstype=erofs fsck.repair=yes rootwait quiet splash plymouth.ignore-serial-consoles cfg80211.ieee80211_regdom=JP
このSDメモリカードを Raspberry Pi 4 を起動させたとき、SquashFSでマウントされていることが確認できる。
pi@raspberrypi:~$ mount | grep mmcblk0p2
/dev/mmcblk0p2 on /media/root-ro type erofs (ro,relatime,user_xattr,acl,cache_strategy=readaround)
測定
起動時間と圧縮率の二つの観点でそれぞれの起動方法を評価していく。
起動時間は systemd-analyzeから kernel と userpaceの合計時間(s)、圧縮率はデフォルトのイメージサイズ (4580120.72 KB) との割合から計測した。
| S No. | 項目 | mkfsのオプション | 起動時間(s) | 圧縮率 |
|---|---|---|---|---|
| 1 | ext4 (R/W) | - | 16.553 | - |
| 2 | ext4 (R/O) | - | 15.988 | - |
| 3 | SquashFS (uncompressed) | -noD -noI -noX -noF |
18.789 | - |
| 4 | SquashFS (gzip) | none | 19.000 | 38.45% |
| 5 | SquashFS (LZ4HC) | -comp lz4 -Xhc |
16.751 | 44.18% |
| 6 | SquashFS (xz) | -comp xz |
28.728 | 32.74% |
| 7 | SquashFS (lzo) | -comp lzo |
17.563 | 41.63% |
| 8 | SquashFS (zstd) | -comp zstd |
16.891 | 36.11% |
| 9 | EROFS (uncompressed) | none | 15.842 | - |
| 10 | EROFS (LZ4HC) | -zlz4hc,12 |
15.842 | 54.70% |
| 11 | EROFS (lzma) | -zlzma |
22.001 | 32.75% |
| 12 | EROFS (big pcluster) | -zlz4hc -C65536 |
15.779 | 48.81% |
| 13 | EROFS (multiple) | --well-compressed=docs/compress-hints.example -zlz4hc,12 |
17.419 | 45.01% |
| 14 | EROFS (well-compressed) | -C1048576 -Eztailpacking -Eall-fragments -Ededupe -zlz4hc,12 |
18.820 | 43.39% |
x軸を起動時間として、y軸を圧縮率としたときに次のようなグラフが得られた。

このグラフでは、プロットが左にあればあるほど起動時間が短く、下にあればあるほどrootfsのイメージサイズが小さいことを表している。
変更履歴
- 2024/05/12: 記事公開
参考文献
- Raspberry Pi で Overlay File System (read-only file system) を試す #RaspberryPi - Qiita
- Raspberry Pi OSのrootfs ROM 化 ― RAMディスク化しつつ、好きなパッケージを後から追加する方法 #RaspberryPi - Qiita
- erofs-utils/docs/PERFORMANCE.md at dev · erofs/erofs-utils · GitHub
- 2024年4月17日現在の Raspberry Pi OS のカーネルでは、SquashFS や EROFS がビルドインされていないため、カーネルは手元でビルドしたものに更新している。↩
Linuxカーネルのファイルアクセスの処理を追いかける (23) MMC: mmc_attach_sd
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、MMCサブシステムの初期化処理について確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
注意
一部の仕様書は非公開となっているため、公開情報からの推測が含まれています。そのため、内容に誤りが含まれている恐れがります。
SD判定
ここまで、MMCサブシステムから デバイス検出処理 (mmc_rescan関数) が、非同期による遅延処理が実行される。
その処理内で、 mmc_attach_sd関数によって、デバイスがSDであるかの検出とSDの初期化に入る。
mmc_attach_sd関数の定義は次のようになっている。
// 1804: int mmc_attach_sd(struct mmc_host *host) { int err; u32 ocr, rocr; WARN_ON(!host->claimed); err = mmc_send_app_op_cond(host, 0, &ocr); if (err) return err; mmc_attach_bus(host, &mmc_sd_ops); if (host->ocr_avail_sd) host->ocr_avail = host->ocr_avail_sd; /* * We need to get OCR a different way for SPI. */ if (mmc_host_is_spi(host)) { mmc_go_idle(host); err = mmc_spi_read_ocr(host, 0, &ocr); if (err) goto err; } /* * Some SD cards claims an out of spec VDD voltage range. Let's treat * these bits as being in-valid and especially also bit7. */ ocr &= ~0x7FFF; rocr = mmc_select_voltage(host, ocr); /* * Can we support the voltage(s) of the card(s)? */ if (!rocr) { err = -EINVAL; goto err; } /* * Detect and init the card. */ err = mmc_sd_init_card(host, rocr, NULL); if (err) goto err; mmc_release_host(host); err = mmc_add_card(host->card); if (err) goto remove_card; mmc_claim_host(host); return 0; remove_card: mmc_remove_card(host->card); host->card = NULL; mmc_claim_host(host); err: mmc_detach_bus(host); pr_err("%s: error %d whilst initialising SD card\n", mmc_hostname(host), err); return err; }
初めに、 mmc_send_app_op_cond関数によって SDかどうかを判定する。
mmc_send_app_op_cond関数では、ACMD41(SD_SEND_OP_COND) のレスポンスで判断する。*1
SD仕様に準拠したメモリカードである場合には、このコマンドでレスポンスが返ってくる。
"inquiry CMD41"の場合には、レスポンスとしてOCR(Operation Conditions Register?)が取得できる。
Vddの選択
OCR は、メモリカードの動作電圧範囲が 100mV 単位で表現される。
SPIモードでは、OCR の取得方法が異なり、mmc_spi_read_ocr関数によって取得する。 (しかし、今回はSPIモードではないため割愛する)
ここでパッチ概要によると、一部のメモリカードでは、この OCRの特定ビットを無効な電圧範囲とすることがある。
取得したOCRとホストコントローラの対応電圧を使い、mmc_select_voltage関数は 供給電圧を設定する。
mmc_select_voltage関数の定義は次のようになっている。
// 1109: u32 mmc_select_voltage(struct mmc_host *host, u32 ocr) { int bit; /* * Sanity check the voltages that the card claims to * support. */ if (ocr & 0x7F) { dev_warn(mmc_dev(host), "card claims to support voltages below defined range\n"); ocr &= ~0x7F; } ocr &= host->ocr_avail; if (!ocr) { dev_warn(mmc_dev(host), "no support for card's volts\n"); return 0; } if (host->caps2 & MMC_CAP2_FULL_PWR_CYCLE) { bit = ffs(ocr) - 1; ocr &= 3 << bit; mmc_power_cycle(host, ocr); } else { bit = fls(ocr) - 1; ocr &= 3 << bit; if (bit != host->ios.vdd) dev_warn(mmc_dev(host), "exceeding card's volts\n"); } return ocr; }
mmc_select_voltage関数では、OCRで取得された値とホストコントローラがサポートしている電圧から、最大VDDを設定する。
例えば、inquiry CMD41でocrが0xff8000 、ホストコントローラの対応範囲host->ocr_availが0x300000の場合には、3.3~3.4Vとなる。

カード初期化
OCRの値がホストコントローラの対応電圧の範囲に入っている場合、mmc_sd_init_card関数によって、SDメモリカードの初期化の処理に入る。
mmc_sd_init_card関数の定義は次のようになっている。
// 1389: static int mmc_sd_init_card(struct mmc_host *host, u32 ocr, struct mmc_card *oldcard) { struct mmc_card *card; int err; u32 cid[4]; u32 rocr = 0; bool v18_fixup_failed = false; WARN_ON(!host->claimed); retry: err = mmc_sd_get_cid(host, ocr, cid, &rocr); if (err) return err; if (oldcard) { if (memcmp(cid, oldcard->raw_cid, sizeof(cid)) != 0) { pr_debug("%s: Perhaps the card was replaced\n", mmc_hostname(host)); return -ENOENT; } card = oldcard; } else { /* * Allocate card structure. */ card = mmc_alloc_card(host, &sd_type); if (IS_ERR(card)) return PTR_ERR(card); card->ocr = ocr; card->type = MMC_TYPE_SD; memcpy(card->raw_cid, cid, sizeof(card->raw_cid)); } /* * Call the optional HC's init_card function to handle quirks. */ if (host->ops->init_card) host->ops->init_card(host, card); /* * For native busses: get card RCA and quit open drain mode. */ if (!mmc_host_is_spi(host)) { err = mmc_send_relative_addr(host, &card->rca); if (err) goto free_card; } if (!oldcard) { err = mmc_sd_get_csd(card); if (err) goto free_card; mmc_decode_cid(card); } /* * handling only for cards supporting DSR and hosts requesting * DSR configuration */ if (card->csd.dsr_imp && host->dsr_req) mmc_set_dsr(host); /* * Select card, as all following commands rely on that. */ if (!mmc_host_is_spi(host)) { err = mmc_select_card(card); if (err) goto free_card; } err = mmc_sd_setup_card(host, card, oldcard != NULL); if (err) goto free_card; /* * If the card has not been power cycled, it may still be using 1.8V * signaling. Detect that situation and try to initialize a UHS-I (1.8V) * transfer mode. */ if (!v18_fixup_failed && !mmc_host_is_spi(host) && mmc_host_uhs(host) && mmc_sd_card_using_v18(card) && host->ios.signal_voltage != MMC_SIGNAL_VOLTAGE_180) { /* * Re-read switch information in case it has changed since * oldcard was initialized. */ if (oldcard) { err = mmc_read_switch(card); if (err) goto free_card; } if (mmc_sd_card_using_v18(card)) { if (mmc_host_set_uhs_voltage(host) || mmc_sd_init_uhs_card(card)) { v18_fixup_failed = true; mmc_power_cycle(host, ocr); if (!oldcard) mmc_remove_card(card); goto retry; } goto done; } } /* Initialization sequence for UHS-I cards */ if (rocr & SD_ROCR_S18A && mmc_host_uhs(host)) { err = mmc_sd_init_uhs_card(card); if (err) goto free_card; } else { /* * Attempt to change to high-speed (if supported) */ err = mmc_sd_switch_hs(card); if (err > 0) mmc_set_timing(card->host, MMC_TIMING_SD_HS); else if (err) goto free_card; /* * Set bus speed. */ mmc_set_clock(host, mmc_sd_get_max_clock(card)); /* * Switch to wider bus (if supported). */ if ((host->caps & MMC_CAP_4_BIT_DATA) && (card->scr.bus_widths & SD_SCR_BUS_WIDTH_4)) { err = mmc_app_set_bus_width(card, MMC_BUS_WIDTH_4); if (err) goto free_card; mmc_set_bus_width(host, MMC_BUS_WIDTH_4); } } if (!oldcard) { /* Read/parse the extension registers. */ err = sd_read_ext_regs(card); if (err) goto free_card; } /* Enable internal SD cache if supported. */ if (card->ext_perf.feature_support & SD_EXT_PERF_CACHE) { err = sd_enable_cache(card); if (err) goto free_card; } if (host->cqe_ops && !host->cqe_enabled) { err = host->cqe_ops->cqe_enable(host, card); if (!err) { host->cqe_enabled = true; host->hsq_enabled = true; pr_info("%s: Host Software Queue enabled\n", mmc_hostname(host)); } } if (host->caps2 & MMC_CAP2_AVOID_3_3V && host->ios.signal_voltage == MMC_SIGNAL_VOLTAGE_330) { pr_err("%s: Host failed to negotiate down from 3.3V\n", mmc_hostname(host)); err = -EINVAL; goto free_card; } done: host->card = card; return 0; free_card: if (!oldcard) mmc_remove_card(card); return err; }
カード識別モード
SDメモリカードには、カードを識別する番号 Card IDentification(CID) を持つ。
mmc_sd_init_card関数では、初めに CID を取得する。
mmc_sd_init_card関数の定義は次のようになっている。
// 808: int mmc_sd_get_cid(struct mmc_host *host, u32 ocr, u32 *cid, u32 *rocr) { int err; u32 max_current; int retries = 10; u32 pocr = ocr; try_again: if (!retries) { ocr &= ~SD_OCR_S18R; pr_warn("%s: Skipping voltage switch\n", mmc_hostname(host)); } /* * Since we're changing the OCR value, we seem to * need to tell some cards to go back to the idle * state. We wait 1ms to give cards time to * respond. */ mmc_go_idle(host); /* * If SD_SEND_IF_COND indicates an SD 2.0 * compliant card and we should set bit 30 * of the ocr to indicate that we can handle * block-addressed SDHC cards. */ err = mmc_send_if_cond(host, ocr); if (!err) ocr |= SD_OCR_CCS; /* * If the host supports one of UHS-I modes, request the card * to switch to 1.8V signaling level. If the card has failed * repeatedly to switch however, skip this. */ if (retries && mmc_host_uhs(host)) ocr |= SD_OCR_S18R; /* * If the host can supply more than 150mA at current voltage, * XPC should be set to 1. */ max_current = sd_get_host_max_current(host); if (max_current > 150) ocr |= SD_OCR_XPC; err = mmc_send_app_op_cond(host, ocr, rocr); if (err) return err; /* * In case the S18A bit is set in the response, let's start the signal * voltage switch procedure. SPI mode doesn't support CMD11. * Note that, according to the spec, the S18A bit is not valid unless * the CCS bit is set as well. We deliberately deviate from the spec in * regards to this, which allows UHS-I to be supported for SDSC cards. */ if (!mmc_host_is_spi(host) && rocr && (*rocr & 0x01000000)) { err = mmc_set_uhs_voltage(host, pocr); if (err == -EAGAIN) { retries--; goto try_again; } else if (err) { retries = 0; goto try_again; } } err = mmc_send_cid(host, cid); return err; }
カード認識するにあたってメモリカードを idle状態に設定する必要がある。
mmc_go_idle関数によって、メモリカードを idle状態に設定することができる。
mmc_go_idle関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。CMD0(FO_IDLE) はカードをidle状態に設定するコマンドである。
[ 1.173771][ T45] mmc0: starting CMD0 arg 00000000 flags 000000c0
SDメモリカードには、SDv1とSDv2の異なるバージョンが存在しており、それぞれで初期化のシーケンスが若干異なる。
SDv1かSDv2か判定するためには、SDv2で追加されたCMD8(SEND_IF_COND)のレスポンスによって判定する。
SDv2判定のためのCMD8は mmc_send_if_conf関数によってコマンドを発行する発行することができる。
mmc_send_if_cond関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.192937][ T45] mmc0: starting CMD8 arg 000001aa flags 000002f5
もし、レスポンスが返ってきた場合、SD High Capacity(SDHC) や SD eXtended Capacity(SDXC) を意味する Card Capacity Status(CCS) を設定する。(SDHC や SDXC は SDv2 で追加された仕様である)
一方で、UHS-I は 信号電圧を 1.8Vまで省電圧化されている。 もし、UHS-Iがサポートされている場合には、S18R (Switching to 1.8V Request) を設定する。
その後、sd_get_host_max_current関数にてホストが供給できる最大電流を取得する。
もし、150mAまで供給できる場合には XPC (SDXC Power Control?) のビットを設定する。
ここまでで設定したocrを引数として ACMD41(SD_SEND_OP_COND) を呼び出す。
ACMD41 は引数が設定されている場合には、inquiry ではなく first ACMD41 として扱われる。

mmc_send_app_op_cond関数(first ACMD41)が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.193312][ T45] mmc0: starting CMD55 arg 00000000 flags 000000f5
[ 1.193603][ T45] mmc0: starting CMD41 arg 40200000 flags 000000e1
first AMCD41のレスポンス rocr の特定ビット S18A(Switching to 1.8V Accepted) は、1.8Vへの切り替えが可能であることを意味する。
CIDの取得には、mmc_send_cid関数を用いる。
SDモードでは、CMD2(ALL_SEND_CID)によってCIDを取得することができる。
mmc_send_cid関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.193849][ T45] mmc0: starting CMD2 arg 00000000 flags 00000007
ここで取得した CID から既存のカードの置き換え処理でない場合には、mmc_alloc_card関数によって mmc_card構造体の変数cardの確保と初期化する。((もし、ホストコントローラ特有の初期化処理が必要な場合には、init_cardを呼び出すことができる))
SDモードでは、RCA(Relative Card Address) の取得が必要となる。 これは、CMD3(SEND_RELATIVE_ADDR)によって取得できる。
mmc_send_relative_addr関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.194188][ T45] mmc0: starting CMD3 arg 00000000 flags 00000075
SDメモリカードでは記憶容量などといった情報を CSD (Card-Specific Data?) レジスタに保持している。
このレジスタの値の取得とcardに情報を代入する処理を mmc_sd_get_csd関数が担う。
データ転送モード
SDメモリカードは、CMD9(SEND_CSD)を受け取ると CSDレジスタの値を返す。
mmc_sd_get_csd関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.448682][ T48] mmc0: starting CMD9 arg 45670000 flags 00000007
一部のSDメモリカードには DSR(Driver Stage Register) が実装されており、CMD/DATA出力の立ち上がり/立ち下がりの時間が強さを調整できる。
デバイスツリーに dsrプロパティを設定している場合、mmc_set_dsr関数によってCMD4 (SET_DSR)が発行される。
ただし、今回はこれが設定されていないため、CMD4は発行されない。
SDメモリカードでは、データ転送の前にCMD7(SELECT/DESELECT_CARD)でカードの選択をする。
mmc_select_card関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.194743][ T45] mmc0: starting CMD7 arg 45670000 flags 00000015
そして、mmc_sd_setup_card関数によってカードの取得・設定していく。
mmc_sd_setup_card関数の定義は次のようになっている。
// 919: int mmc_sd_setup_card(struct mmc_host *host, struct mmc_card *card, bool reinit) { int err; if (!reinit) { /* * Fetch SCR from card. */ err = mmc_app_send_scr(card); if (err) return err; err = mmc_decode_scr(card); if (err) return err; /* * Fetch and process SD Status register. */ err = mmc_read_ssr(card); if (err) return err; /* Erase init depends on CSD and SSR */ mmc_init_erase(card); /* * Fetch switch information from card. */ err = mmc_read_switch(card); if (err) return err; } /* * For SPI, enable CRC as appropriate. * This CRC enable is located AFTER the reading of the * card registers because some SDHC cards are not able * to provide valid CRCs for non-512-byte blocks. */ if (mmc_host_is_spi(host)) { err = mmc_spi_set_crc(host, use_spi_crc); if (err) return err; } /* * Check if read-only switch is active. */ if (!reinit) { int ro = mmc_sd_get_ro(host); if (ro < 0) { pr_warn("%s: host does not support reading read-only switch, assuming write-enable\n", mmc_hostname(host)); } else if (ro > 0) { mmc_card_set_readonly(card); } } return 0; }
SDメモリカードには、SCR(Sd Configuration Register) で SDメモリカードの特定の情報を持つ。
これには、mmc_app_send_scr関数が ACMD51 を発行する必要がある。
この関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.194989][ T45] mmc0: starting CMD55 arg 45670000 flags 00000095
[ 1.195346][ T45] mmc0: starting CMD51 arg 00000000 flags 000000b5
その後、SSR(Sd Status Register) を取得する。
これには、mmc_read_ssr関数が ACMD13 を発行する必要がある。
この関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.196964][ T45] mmc0: starting CMD55 arg 45670000 flags 00000095
[ 1.197161][ T45] mmc0: starting CMD13 arg 00000000 flags 000001b5
mmc_init_erase関数では、SSRなどから erase_size(eraseの最小単位) や preferred_erase_size(Allocation Unit size) を card に設定する。
mmc_read_switch関数は、SDメモリカードが対応しているバススピードモードを確認する。
これには、mmc_read_switch関数が CMD6 を発行する必要がある。
この関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.197741][ T45] mmc0: starting CMD6 arg 00fffff0 flags 000000b5
その後、バススピードやバス幅の設定をする。 ここでは、UHS-Iの場合とそうではない場合で分かれており、対応関係は次のようになっている。
| バスインターフェース | バススピードモード | バススピード |
|---|---|---|
| default | 12.5MB/s | |
| High speed | 25MB/s | |
| UHS-I | SDR50/DDR50 | 50MB/s |
| UHS-I | SDR104 | 104MB/s |
また、SD spec 6.x から 性能改善機能としてキャッシュなどが追加されており、これらをサポートしているカードに対しては CMD48(READ_EXTR_SINGLE)とCMD49(WRITE_EXTR_SINGLE)を発行することができる。
MMCバスに追加
mmc_add_card関数によって初期化の処理が完了したMMCメモリカードをLinuxデバイスモデルに登録する。
mmc_add_card関数の定義は次のようになっている。
// 308: int mmc_add_card(struct mmc_card *card) { int ret; const char *type; const char *uhs_bus_speed_mode = ""; static const char *const uhs_speeds[] = { [UHS_SDR12_BUS_SPEED] = "SDR12 ", [UHS_SDR25_BUS_SPEED] = "SDR25 ", [UHS_SDR50_BUS_SPEED] = "SDR50 ", [UHS_SDR104_BUS_SPEED] = "SDR104 ", [UHS_DDR50_BUS_SPEED] = "DDR50 ", }; dev_set_name(&card->dev, "%s:%04x", mmc_hostname(card->host), card->rca); switch (card->type) { case MMC_TYPE_MMC: type = "MMC"; break; case MMC_TYPE_SD: type = "SD"; if (mmc_card_blockaddr(card)) { if (mmc_card_ext_capacity(card)) type = "SDXC"; else type = "SDHC"; } break; case MMC_TYPE_SDIO: type = "SDIO"; break; case MMC_TYPE_SD_COMBO: type = "SD-combo"; if (mmc_card_blockaddr(card)) type = "SDHC-combo"; break; default: type = "?"; break; } if (mmc_card_uhs(card) && (card->sd_bus_speed < ARRAY_SIZE(uhs_speeds))) uhs_bus_speed_mode = uhs_speeds[card->sd_bus_speed]; if (mmc_host_is_spi(card->host)) { pr_info("%s: new %s%s%s card on SPI\n", mmc_hostname(card->host), mmc_card_hs(card) ? "high speed " : "", mmc_card_ddr52(card) ? "DDR " : "", type); } else { pr_info("%s: new %s%s%s%s%s%s card at address %04x\n", mmc_hostname(card->host), mmc_card_uhs(card) ? "ultra high speed " : (mmc_card_hs(card) ? "high speed " : ""), mmc_card_hs400(card) ? "HS400 " : (mmc_card_hs200(card) ? "HS200 " : ""), mmc_card_hs400es(card) ? "Enhanced strobe " : "", mmc_card_ddr52(card) ? "DDR " : "", uhs_bus_speed_mode, type, card->rca); } #ifdef CONFIG_DEBUG_FS mmc_add_card_debugfs(card); #endif card->dev.of_node = mmc_of_find_child_device(card->host, 0); device_enable_async_suspend(&card->dev); ret = device_add(&card->dev); if (ret) return ret; mmc_card_set_present(card); return 0; }
ここまでの処理によってカード種類などが判明しているため、カーネルメッセージに出力する。 例えば、今回の環境では次のようなデバッグメッセージが確認することができる。
[ 1.197018][ T45] mmc0: new SD card at address 4567
その後、mmc_add_card_debugfs関数で debugfs にエントリを追加し、device_add関数で sysfs にエントリを追加する。
mmc_add_card_debugfs関数の定義は次のようになっている。
// 253: void mmc_add_card_debugfs(struct mmc_card *card) { struct mmc_host *host = card->host; struct dentry *root; if (!host->debugfs_root) return; root = debugfs_create_dir(mmc_card_id(card), host->debugfs_root); card->debugfs_root = root; debugfs_create_x32("state", S_IRUSR, root, &card->state); }
mmc_add_card_debugfs関数によって メモリカードの状態を確認できるようなエントリが追加される。
// 1: /* Card states */ #define MMC_STATE_PRESENT (1<<0) /* present in sysfs */ #define MMC_STATE_READONLY (1<<1) /* card is read-only */ #define MMC_STATE_BLOCKADDR (1<<2) /* card uses block-addressing */ #define MMC_CARD_SDXC (1<<3) /* card is SDXC */ #define MMC_CARD_REMOVED (1<<4) /* card has been removed */ #define MMC_STATE_SUSPENDED (1<<5) /* card is suspended */
例えば、今回の環境で起動直後に確認した場合には次のような結果が得られる。
# cat /sys/kernel/debug/mmc0/mmc0\:4567/state
0x00000001
device_add関数はLinuxデバイスモデルに"Device"を登録するAPIである。
この関数によって、関連するコンポーネントとして bus の probe処理が呼ばれる。
今回は mmc_bus_probe関数 (と mmc_blk_probe関数) を実行する。
おわりに
本記事では、カーネル起動時に呼び出される mmc_attach_sd関数について確認した。
この関数では、SDメモリカードの初期化ロジックが組み込まれており、次のようなCMDが発行されている。

変更履歴
- 2024/05/10: 記事公開
参考
- SD規格の概要 | SD Association
- SD規格の概要
- MMC/SDCの使いかた
- MMC/SDC の仕組みの解説
- LINUX MMC 子系统分析之六 MMC card添加流程分析_mmc rescan流程分析-CSDN博客
- 車載外部ストレージ バックナンバー | シミュレーションの世界に引きこもる部屋
- SD初期化ルーチンの解説
- SDIOについて #sdio - Qiita
- SDカードのCMDリクエストとレスポンス
- Device drivers infrastructure — The Linux Kernel documentation
- device driverのAPIドキュメント
*1:ACMDは、直前にCMD55である場合に、そのコマンドをACMDとして解釈される
Raspberry Pi 4 で USBフラッシュドライブ に Bcachefs を試してみる
背景
Bcachefs は LInuxカーネル 6.7 からサポートされた Copy-On-Write (CoW) のファイルシステムである。 Bcachefs は、従来のLinuxでサポートされていた "bcache" をベースとしており、堅牢性と信頼性に加えて、多くの機能をサポートしていることで注目を浴びている。
目的
手元の Raspberry Pi 4 Model B (Raspberry Pi 4) で Bcachefs のドキュメントに従って実行することで、挙動や機能の概要を把握する。
実行環境
Raspberry Pi 4 は microSDカード経由でRaspberry Pi OSを起動させる。

ここで使用するRaspberry Pi 4のスペックについて、必要な情報だけ抜粋したものを下記に示す。
| 項目 | Raspberry Pi 4 |
|---|---|
| CPU | Cortex-A72 (ARM v8) 1.5GHz |
| メモリ | 4GB LPDDR4-3200 |
| OS | Raspberry Pi OS Lite (Mar 15th 2024) |
| Linux kernel | v6.9-rc31 |
| bcachefs-tools | version v0.1-nogit |
| fio | fio-3.33 |
| micro SD card | KTHN-MW016G |
| USB 3.0 (1) | USM32GU |
| USB 3.0 (2) | SP032GBUF3B02V1K |
| USB 2.0 (1) | USM32GR |
| ケース | 陽極酸化アルミニウム製ヒートシンクケース |
シングルドライブでの実験
単一のUSBフラッシュドライブのみに対して bcachefsを使用してみる。
ディスクパーティション /dev/sda を bcachefs でフォーマットするには、 bcacahefs format コマンドを実行する。
pi@raspberrypi:~$ sudo bcachefs format /dev/sda
External UUID: 87cb6bbc-c417-4d66-8053-a96e07bc1dc2
Internal UUID: 19bbba4a-3a3d-4f72-974d-dcaedc54bbdb
Device index: 0
Label:
Version: unwritten_extents
Oldest version on disk: unwritten_extents
Created: Wed Apr 17 05:53:46 2024
Sequence number: 0
Superblock size: 816
Clean: 0
Devices: 1
Sections: members
Features: new_siphash,new_extent_overwrite,btree_ptr_v2,extents_above_btree_updates,btree _updates_journalled,new_varint,journal_no_flush,alloc_v2,extentssCompat features:
Options:
block_size: 512 B
btree_node_size: 256 KiB
errors: continue [ro] panic
metadata_replicas: 1
data_replicas: 1
metadata_replicas_required: 1
data_replicas_required: 1
encoded_extent_max: 64.0 KiB
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
compression: [none] lz4 gzip zstd
background_compression: [none] lz4 gzip zstd
str_hash: crc32c crc64 [siphash]
metadata_target: none
foreground_target: none
background_target: none
promote_target: none
erasure_code: 0
inodes_32bit: 1
shard_inode_numbers: 1
inodes_use_key_cache: 1
gc_reserve_percent: 8
gc_reserve_bytes: 0 B
root_reserve_percent: 0
wide_macs: 0
acl: 1
usrquota: 0
grpquota: 0
prjquota: 0
journal_flush_delay: 1000
journal_flush_disabled: 0
journal_reclaim_delay: 100
nocow: 0
members (size 64):
Device: 0
UUID: 6b8b7038-fa14-4c21-8d1e-00b0cac0adf6
Size: 28.9 GiB
Bucket size: 256 KiB
First bucket: 0
Buckets: 118296
Last mount: (never)
State: rw
Label: (none)
Data allowed: journal,btree,user
Has data: (none)
Discard: 0
Freespace initialized: 0
initializing new filesystem
going read-write
initializing freespace
mounted version=unwritten_extents opts=noinodes_use_key_cache
kernel が bcachefs をサポートしている場合、従来のファイルシステムと同様に mountコマンドにより指定したマウントポイントに bcachefs をマウントすることができる。
pi@raspberrypi:~$ sudo mount -t bcachefs /dev/sda /mnt/
ここで、Flexible I/O tester (FIO) による簡易な読み書きパフォーマンスのベンチマークを取ってみる。
I/O サイズを 1 MB で順次書き込みをするようなジョブファイル write1.fioを使って書き込み帯域幅を確認する。
// 1: [global] ioengine=libaio size=4G invalidate=1 direct=1 verify=0 randrepeat=0 unlink=0 sync=0 ; 順次読み込みの場合は rw=read rw=write bs=1M time_based=1 [job] name=write_bandwidth_test ; ブロックデバイスでの測定の場合は file=/dev/sda directory=/mnt ramp_time=2 runtime=5m numjobs=4 group_reporting=1 iodepth=1
上記の測定結果(bcachefs上のファイルにアクセスした場合)に加えて、ブロックデバイスに直接アクセスした場合の書き込み/読み込み帯域幅を図示すると次のようになった。
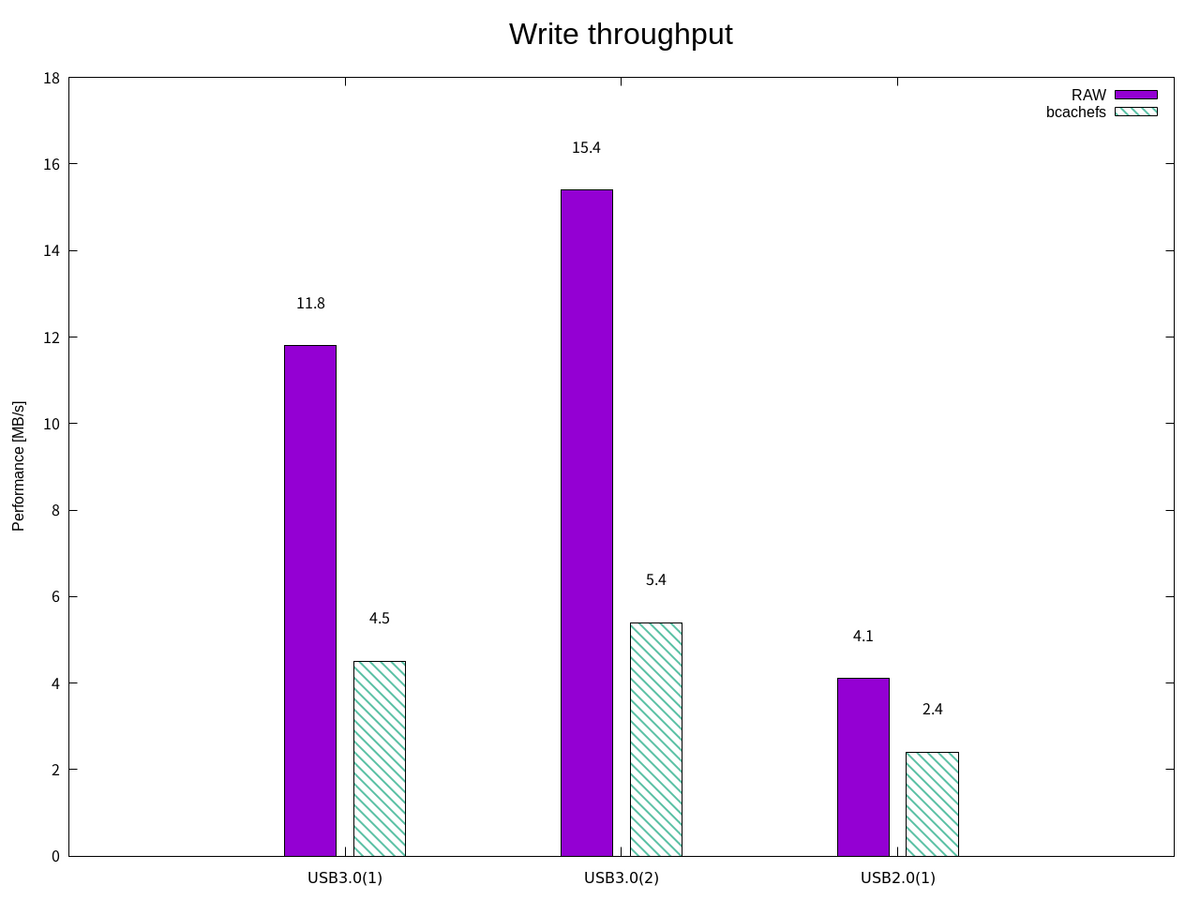
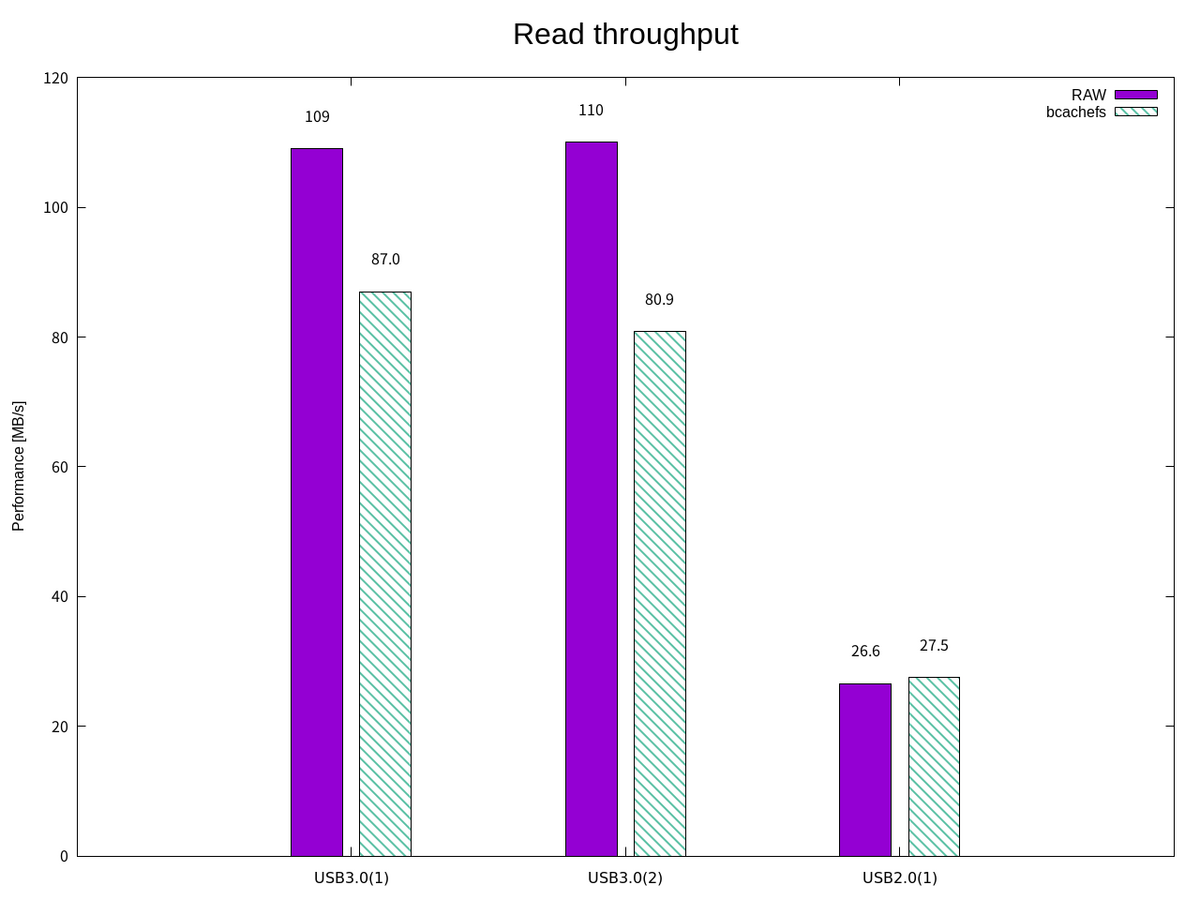
この結果だけ見ると、Bcachefs によるオーバーヘッドが大きく見えてしまうが、"データと"ファイル"へのアクセスを比較しているため、これを性能の優劣をつけることはできない。 本来であれば、測定結果の妥当性の確認もしておきたいが、それは本記事の目的から外れるため割愛する。
暗号化
Bcachefsでは、認証付暗号化方式 AEAD の暗号化 (ChaCha20/Poly1305) をサポートしている。 これにより、ファイルシステム全体に対して暗号化することができ、スーパーブロックを除くすべてのメタデータが暗号化される。
暗号化を使用して Bcachefs でフォーマットするには、bcachefs formatコマンドに --encryptedオプションを追加する。
このとき、passphrase の入力が求められる。
pi@raspberrypi:~$ sudo bcachefs format --encrypted /dev/sda
Enter passphrase:
Enter same passphrase again:
External UUID: 0ac05aa8-9b50-48fd-9bfc-95a016a0e74e
Internal UUID: 5da9ad34-0907-4eee-a2c4-e99378bb1719
Device index: 0
Label:
Version: unwritten_extents
Oldest version on disk: unwritten_extents
Created: Mon Apr 15 00:08:25 2024
Sequence number: 0
Superblock size: 880
Clean: 0
Devices: 1
Sections: members,crypt
Features: new_siphash,new_extent_overwrite,btree_ptr_v2,extents_above_btree_updates,btree _updates_journalled,new_varint,journal_no_flush,alloc_v2,extentssCompat features:
Options:
block_size: 512 B
btree_node_size: 256 KiB
errors: continue [ro] panic
metadata_replicas: 1
data_replicas: 1
metadata_replicas_required: 1
data_replicas_required: 1
encoded_extent_max: 64.0 KiB
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
compression: [none] lz4 gzip zstd
background_compression: [none] lz4 gzip zstd
str_hash: crc32c crc64 [siphash]
metadata_target: none
foreground_target: none
background_target: none
promote_target: none
erasure_code: 0
inodes_32bit: 1
shard_inode_numbers: 1
inodes_use_key_cache: 1
gc_reserve_percent: 8
gc_reserve_bytes: 0 B
root_reserve_percent: 0
wide_macs: 0
acl: 1
usrquota: 0
grpquota: 0
prjquota: 0
journal_flush_delay: 1000
journal_flush_disabled: 0
journal_reclaim_delay: 100
nocow: 0
members (size 64):
Device: 0
UUID: 466c5ef5-893c-4b7a-8781-0dcc2d2734ed
Size: 28.9 GiB
Bucket size: 256 KiB
First bucket: 0
Buckets: 118272
Last mount: (never)
State: rw
Label: (none)
Data allowed: journal,btree,user
Has data: (none)
Discard: 0
Freespace initialized: 0
暗号化された bcachefs ファイルシステムはロック状態となっているため、そのままではマウントすることはできない。
pi@raspberrypi:~$ sudo mount -t bcachefs /dev/sda /mnt/
mount: /mnt: mount(2) system call failed: Required key not available.
dmesg(1) may have more information after failed mount system call.
pi@raspberrypi:~$ sudo dmesg | grep bcachefs
[ 599.228656] bcachefs (cd0e560a-0916-4b26-9db8-5d4aa60500e4): error requesting encryption key: ENOKEY
暗号化された bcachefs ファイルシステムは、 bcachefs unlockコマンドによってロック解除することができる。
このとき、暗号化で使用した passphrase の入力が求められる。
pi@raspberrypi:~$ sudo bcachefs unlock /dev/sda
Enter passphrase:
これにより、暗号化キーがカーネル内のキーリングに追加される。
ただし、ここからマウントなどする場合には、キーをセッションに手動でリンクする必要があるらしい。(または、unlockのときに-k sessionオプションを追加する)
Re: Mounting a encrypted disk: Fatal error: Required key not available - Martin Steigerwald
pi@raspberrypi:~$ sudo keyctl link @u @s
これによって、現在のセッションで暗号化された bcachefs が利用 (マウント) できるようになる。
pi@raspberrypi:~$ sudo mount -t bcachefs /dev/sda /mnt/
ここで、FIO による簡易な読み書きパフォーマンスのベンチマークを取ってみる。 I/O サイズを 1 MB で順次書き込みをするようなジョブファイル write1.fioを使って書き込み帯域幅を確認する。
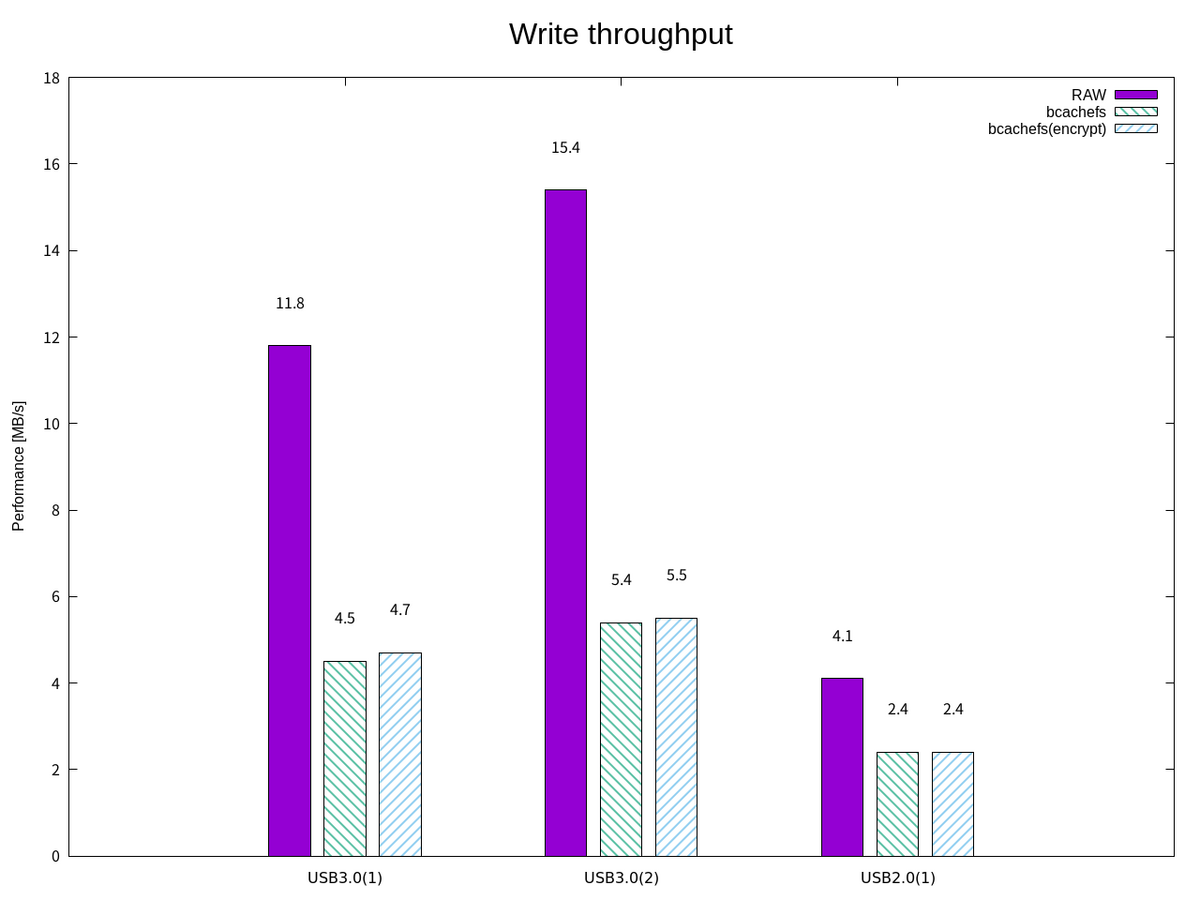

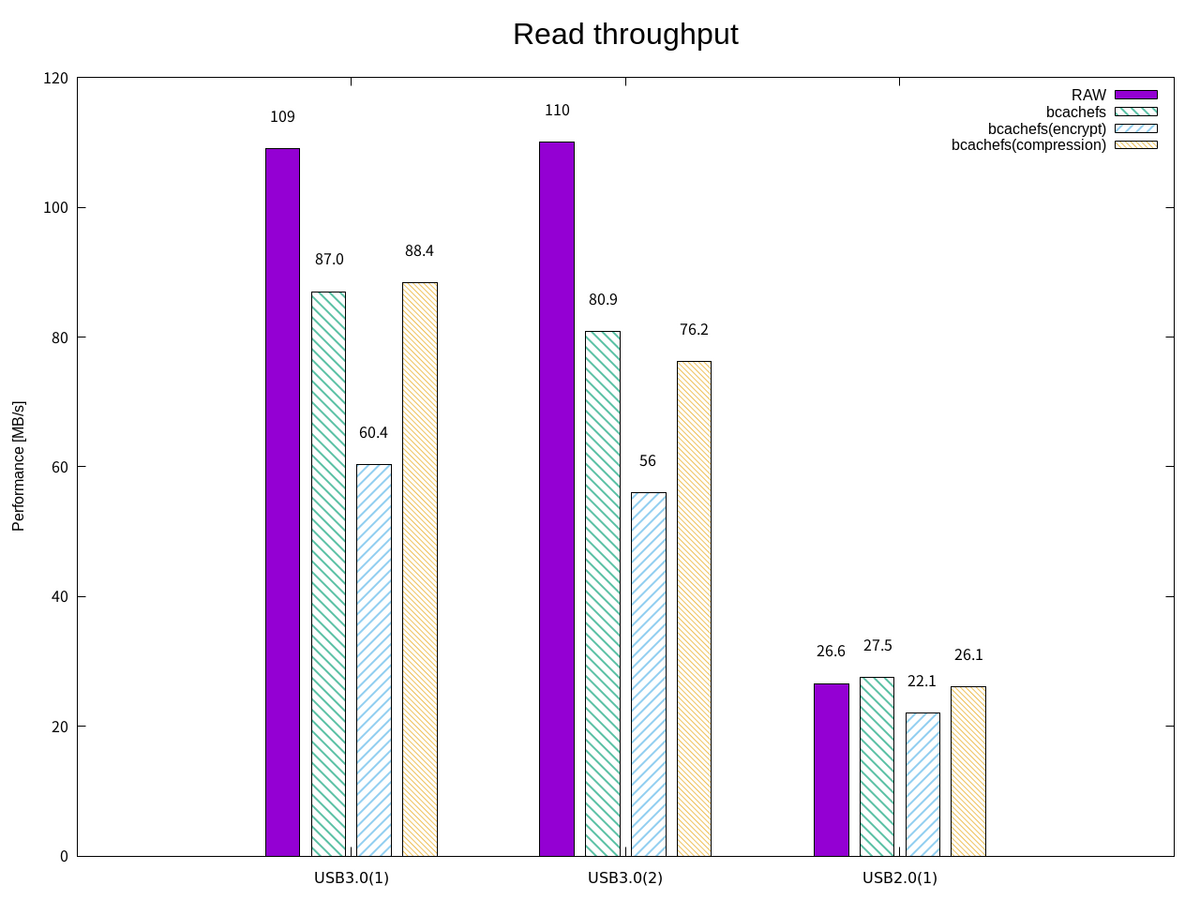
今回の測定では、暗号化機能を有効にした場合の書き込み帯域幅のオーバーヘッドは微小であった。 一方で、USB3.0(1)と(2)の読み込み帯域幅は25%程度の低下が見られた。また、USB2.0(1)の低下が微小であった。オーバーヘッドが微小であるのは、ストレージデバイスへのアクセスで律速しているケースと考えられる、
また、この機能を有効化していない場合、ブロックデバイス経由でbcachefsにあるファイルの名前が確認できたが、
pi@raspberrypi:~$ sudo xxd -a /dev/sda | grep -E "job\.[0-3]\.0"
002801d0: 086a 6f62 2e30 2e30 0600 0000 0000 0000 .job.0.0........
0210fb70: 0210 0000 0000 0000 086a 6f62 2e33 2e30 .........job.3.0
03f19970: 0310 0000 0000 0000 086a 6f62 2e32 2e30 .........job.2.0
05d0c190: 0410 0000 0000 0000 086a 6f62 2e31 2e30 .........job.1.0
0ed40440: 0000 0020 0000 0000 086a 6f62 2e30 2e30 ... .....job.0.0
0ed40640: 0210 0000 0000 0000 086a 6f62 2e33 2e30 .........job.3.0
0ed40840: 0410 0000 0000 0000 086a 6f62 2e31 2e30 .........job.1.0
0ed40870: 086a 6f62 2e32 2e30 0000 0000 0000 0000 .job.2.0........
この機能を有効にしている場合、ブロックデバイス経由でbcachefsにあるファイルの名前を確認することはできなかった。
pi@raspberrypi:~$ sudo xxd -a /dev/sda | grep -E "job\.[0-3]\.0"
pi@raspberrypi:~$
圧縮
Bcachefsでは、データをエクステント単位による圧縮 (gzip、lz4、zstd) をサポートしている。
圧縮レベルは、0 ~ 15 を指定することができる。
さらに、コマンド bcachefs setattrによって特定のファイル/ディレクトリに対しても有効となっている。
また、rebalanceスレッドによって別のアルゴリズムによるデータを圧縮/再圧縮することもできる。
lz4で圧縮、zstdでバックグラウンド圧縮するためには、bcachefs formatコマンドに --compressionと--background_compressionオプションを追加する。
pi@raspberrypi:~$ sudo bcachefs format --compression=lz4 --background_compression=zstd /dev/sda
Bcachefs を /mnt以下にマウントする。
pi@raspberrypi:~$ sudo mount -t bcachefs /dev/sda /mnt/
ここで、FIO による簡易な読み書きパフォーマンスのベンチマークを取ってみる。 I/O サイズを 1 MB で順次書き込みをするようなジョブファイル write1.fioを使って書き込み帯域幅を確認する。
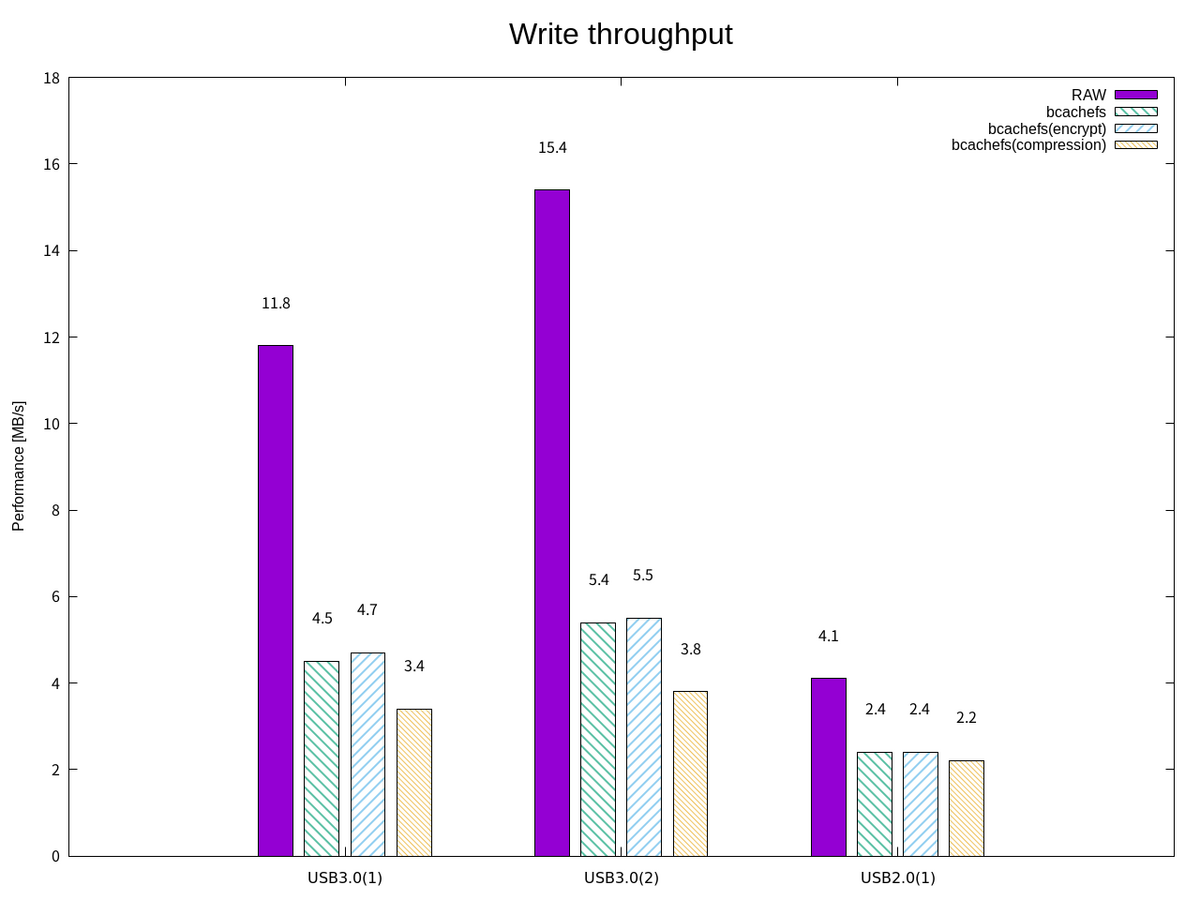
また、この機能による効果を確認するために、巨大なテキストファイル群 (linux-6.9-rc4.tar) をコピーしてみる。
pi@raspberrypi:~$ ls -l /mnt
total 1454330
-rw-r--r-- 1 root root 1489233920 Apr 18 05:44 linux-6.9-rc4.tar
drwx------ 2 root root 0 Apr 18 05:42 lost+found
pi@raspberrypi:~$ df /dev/sda
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda 27615550 662787 26538105 3% /mnt
pi@raspberrypi:~$ sync
pi@raspberrypi:~$ df /dev/sda
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda 27615550 397492 26799319 2% /mnt
対象のファイル群はファイルサイズ1.4GBであったが、bcachefsによる圧縮(lz4)の効果により 662KB の使用量まで抑えられている。 また、rebalanceスレッドによってzstdへと再圧縮されており、400KBまで減っていることが分かった。
マルチドライブでの実験
bcachefs はマルチデバイス2に対応しているファイルシステムである。
ここでは、Raspberry Pi OSがそれぞれのUSBフラッシュドライブを次のように認識している場合である。
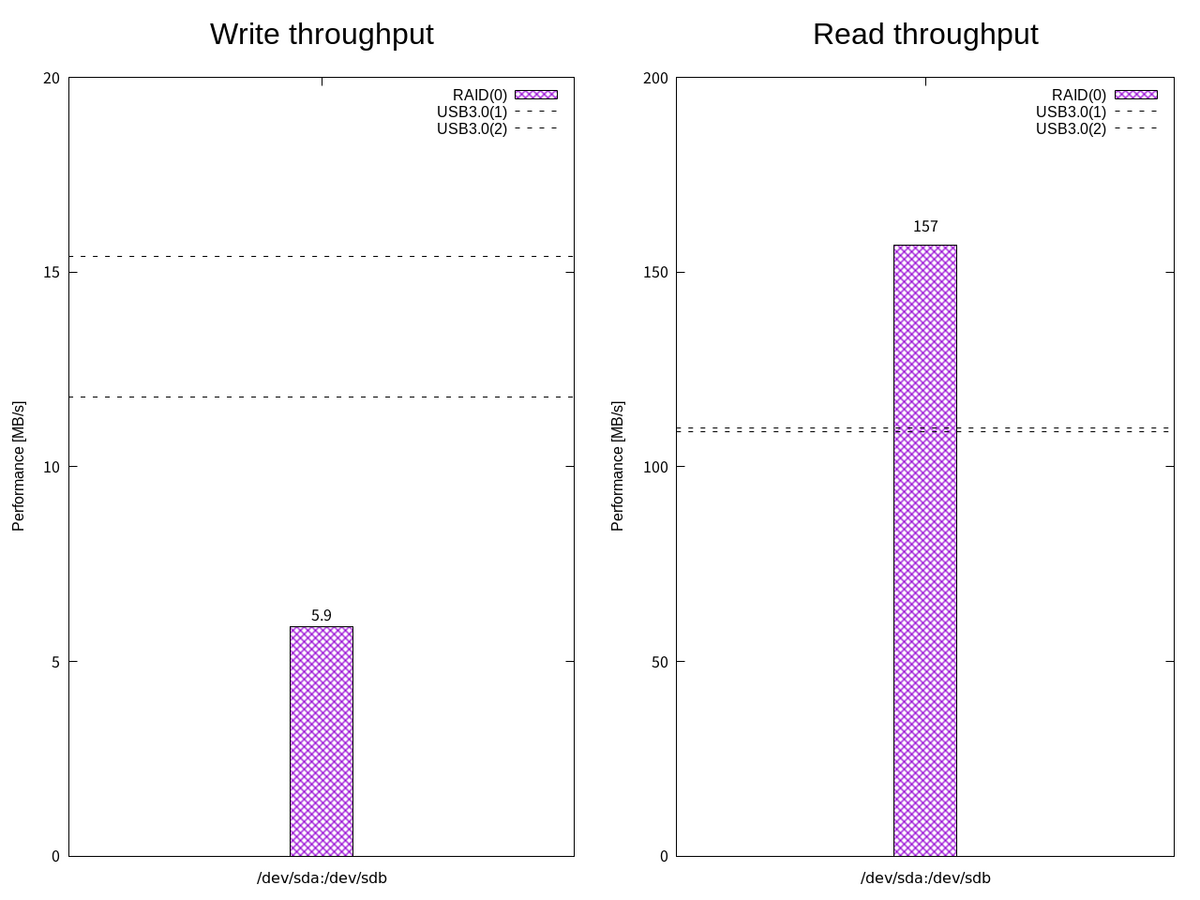
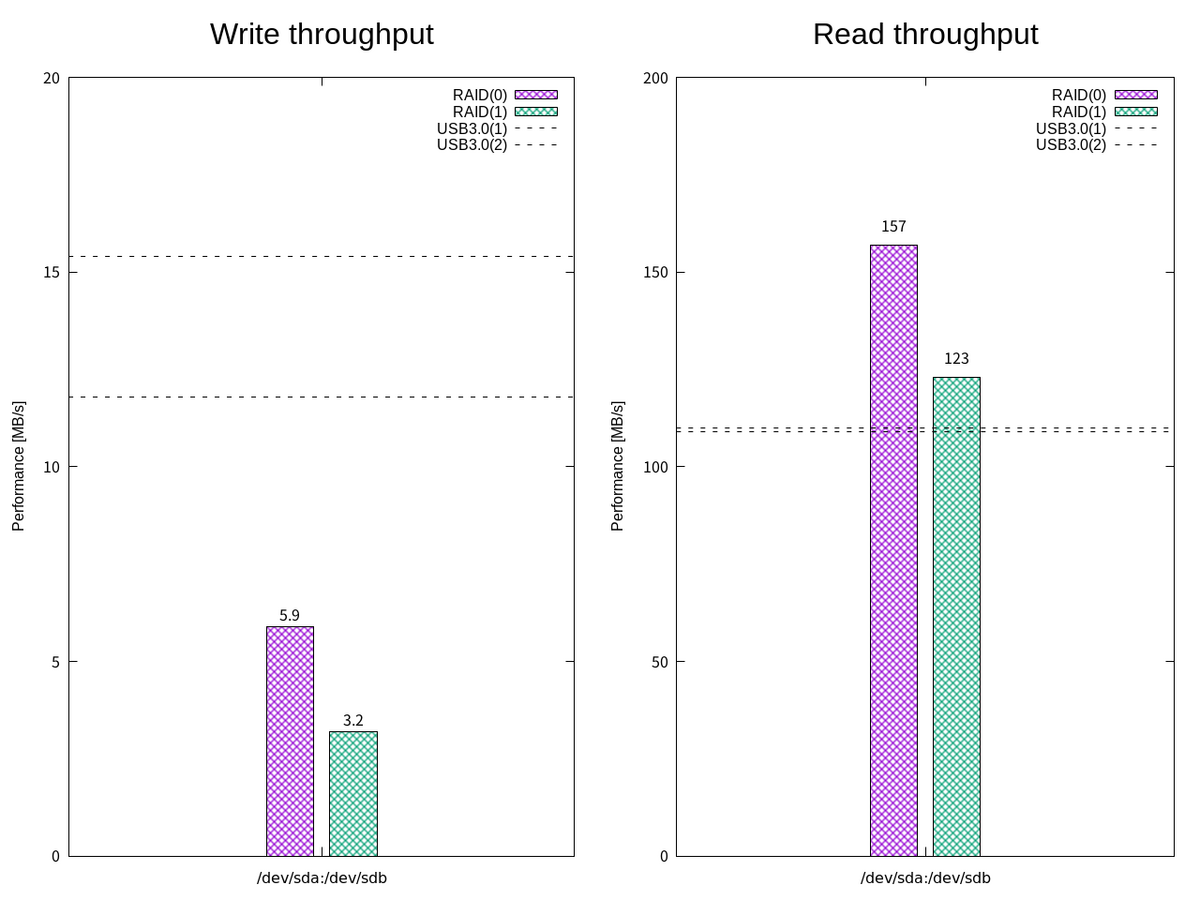
| デバイスファイル | USBフラッシュドライブ | 書き込み帯域幅(暫定) | 読み込み帯域幅(暫定) |
|---|---|---|---|
/dev/sda |
USB3.0(1) | 11.8MB/s | 109MB/s |
/dev/sdb |
USB3.0(2) | 15.4MB/s | 110MB/s |
/dev/sdc |
USB2.0(1) | 4.1MB/s | 26.6MB/s |
ストライピング
bcachefsでは、複数のドライブを指定したときはストライピング(RAID0)として扱う。
pi@raspberrypi:~$ sudo bcachefs format /dev/sda /dev/sdb
External UUID: 3e548aa6-9b4e-4465-988c-86f6c40c6348
Internal UUID: b95602d7-ce7c-47e0-b7bf-26b1300a9b5e
Device index: 1
Label:
Version: unwritten_extents
Oldest version on disk: unwritten_extents
Created: Thu Apr 18 20:25:12 2024
Sequence number: 0
Superblock size: 872
Clean: 0
Devices: 2
Sections: members
Features: new_siphash,new_extent_overwrite,btree_ptr_v2,extents_above_btree_updates,btree _updates_journalled,new_varint,journal_no_flush,alloc_v2,extents_across_btree_nodes
Compat features:
Options:
block_size: 512 B
btree_node_size: 256 KiB
errors: continue [ro] panic
metadata_replicas: 1
data_replicas: 1
metadata_replicas_required: 1
data_replicas_required: 1
encoded_extent_max: 64.0 KiB
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
compression: [none] lz4 gzip zstd
background_compression: [none] lz4 gzip zstd
str_hash: crc32c crc64 [siphash]
metadata_target: none
foreground_target: none
background_target: none
promote_target: none
erasure_code: 0
inodes_32bit: 1
shard_inode_numbers: 1
inodes_use_key_cache: 1
gc_reserve_percent: 8
gc_reserve_bytes: 0 B
root_reserve_percent: 0
wide_macs: 0
acl: 1
usrquota: 0
grpquota: 0
prjquota: 0
journal_flush_delay: 1000
journal_flush_disabled: 0
journal_reclaim_delay: 100
nocow: 0
members (size 120):
Device: 0
UUID: 16aa5679-4832-4197-bb0c-ea8004dac946
Size: 28.9 GiB
Bucket size: 256 KiB
First bucket: 0
Buckets: 118272
Last mount: (never)
State: rw
Label: (none)
Data allowed: journal,btree,user
Has data: (none)
Discard: 0
Freespace initialized: 0
Device: 1
UUID: 175843da-3652-40a1-ab42-13aed32fdc7f
Size: 28.9 GiB
Bucket size: 256 KiB
First bucket: 0
Buckets: 118296
Last mount: (never)
State: rw
Label: (none)
Data allowed: journal,btree,user
Has data: (none)
Discard: 0
Freespace initialized: 0
initializing new filesystem
going read-write
initializing freespace
マルチドライブによる bcachefs のマウントには、 :によってブロックデバイス名を指定する必要がある。
pi@raspberrypi:~$ sudo mount -t bcachefs /dev/sda:/dev/sdb /mnt/
/mnt は /dev/sdaと/dev/sdbの2つのブロックデバイスから構成されているので、合計領域もそれらの総和となっている。
pi@raspberrypi:~$ df -h /mnt/
Filesystem Size Used Avail Use% Mounted on
/dev/sda:/dev/sdb 53G 1.5M 52G 1% /mnt
ここで、FIO による簡易な読み書きパフォーマンスのベンチマークを取ってみる。 I/O サイズを 1 MB で順次書き込みをするようなジョブファイル write1.fioを使って書き込み帯域幅を確認する。
レプリケーション
2台のドライブによるレプリケーション(RAID1)するには、bcachefs formatコマンドに --replicas オプションを追加する。
pi@raspberrypi:~$ sudo bcachefs format /dev/sda /dev/sdb --replicas=2
External UUID: de438111-fb04-402f-a8c9-a2a2033df85d
Internal UUID: 07de9a56-0613-40a9-a6e3-5361ea4165f7
Device index: 1
Label:
Version: unwritten_extents
Oldest version on disk: unwritten_extents
Created: Thu Apr 18 07:10:24 2024
Sequence number: 0
Superblock size: 872
Clean: 0
Devices: 2
Sections: members
Features: new_siphash,new_extent_overwrite,btree_ptr_v2,extents_above_btree_updates,btree _updates_journalled,new_varint,journal_no_flush,alloc_v2,extentss
Compat features:
Options:
block_size: 512 B
btree_node_size: 256 KiB
errors: continue [ro] panic
metadata_replicas: 2
data_replicas: 2
metadata_replicas_required: 1
data_replicas_required: 1
encoded_extent_max: 64.0 KiB
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
compression: [none] lz4 gzip zstd
background_compression: [none] lz4 gzip zstd
str_hash: crc32c crc64 [siphash]
metadata_target: none
foreground_target: none
background_target: none
promote_target: none
erasure_code: 0
inodes_32bit: 1
shard_inode_numbers: 1
inodes_use_key_cache: 1
gc_reserve_percent: 8
gc_reserve_bytes: 0 B
root_reserve_percent: 0
wide_macs: 0
acl: 1
usrquota: 0
grpquota: 0
prjquota: 0
journal_flush_delay: 1000
journal_flush_disabled: 0
journal_reclaim_delay: 100
nocow: 0
members (size 120):
Device: 0
UUID: 28f83018-915d-4423-986c-32ad8f361fde
Size: 28.9 GiB
Bucket size: 256 KiB
First bucket: 0
Buckets: 118272
Last mount: (never)
State: rw
Label: (none)
Data allowed: journal,btree,user
Has data: (none)
Discard: 0
Freespace initialized: 0
Device: 1
UUID: 3b4b848a-89f2-48d2-96de-556b69f15cb4
Size: 28.9 GiB
Bucket size: 256 KiB
First bucket: 0
Buckets: 118296
Last mount: (never)
State: rw
Label: (none)
Data allowed: journal,btree,user
Has data: (none)
Discard: 0
Freespace initialized: 0
initializing new filesystem
going read-write
initializing freespace
mounted version=unwritten_extents opts=metadata_replicas=2,data_replicas=2,noinodes_use_key_cache
Bcachefs を /mnt以下にマウントする場合には複数のブロックデバイスを指定する。
pi@raspberrypi:~$ sudo mount /dev/sda:/dev/sdb /mnt/
ここで、FIO による簡易な読み書きパフォーマンスのベンチマークを取ってみる。 I/O サイズを 1 MB で順次書き込みをするようなジョブファイル write1.fioを使って書き込み帯域幅を確認する。
キャッシュ
bcachefs ではデバイスにラベルを付与することができる。 このラベルによってグループ化された特定のデバイスに特定にアクションを優先させたりすることで、ストレージデバイスの特性を活かすことができる。
bcachefs では、読み書きのターゲットとして、フォアグラウンドでの書き込み先 --forground_target、バックグラウンドで書き戻す先 --background_target、読み込み時にキャッシュとして使う --promote_target と設定することができる。
例えば、アクセス速度が速いUSB3.0(1) /dev/sda とUSB3.0(2) /dev/sdb に ssdラベル、遅いUSB2.0(/dev/sdc)には hddラべルを付与することで、上記のターゲットのルールは次のように設定することができる。[^3]
pi@raspberrypi:~$ sudo bcachefs format \
--label=ssd.ssd1 /dev/sda \
--label=hdd.hdd1 /dev/sdb \
--label=hdd.hdd2 /dev/sdc \
--foreground_target=ssd \
--promote_target=ssd \
--background_target=hdd
Bcachefs を /mnt以下にマウントする場合には複数のブロックデバイスを指定する。
pi@raspberrypi:~$ sudo mount /dev/sda:/dev/sdb /mnt/
そこで、いくつかのパターンで FIO による簡易な読み書きパフォーマンスのベンチマークを取ってみる。 I/O サイズを 1 MB で順次書き込みをするようなジョブファイル write1.fioを使って書き込み帯域幅を確認する。
| パターン | foreground_target |
promote_target |
background_target |
|---|---|---|---|
| 2 SSDs | USB3.0(1) + USB3.0(2) | USB3.0(1) + USB3.0(2) | USB2.0(1) |
| 1 SSD | USB3.0(1) | USB3.0(1) | USB3.0(1) + USB2.0(1) |
| Slow 1 SSD | USB2.0(1) | USB2.0(1) | USB3.0(1) + USB3.0(2) |
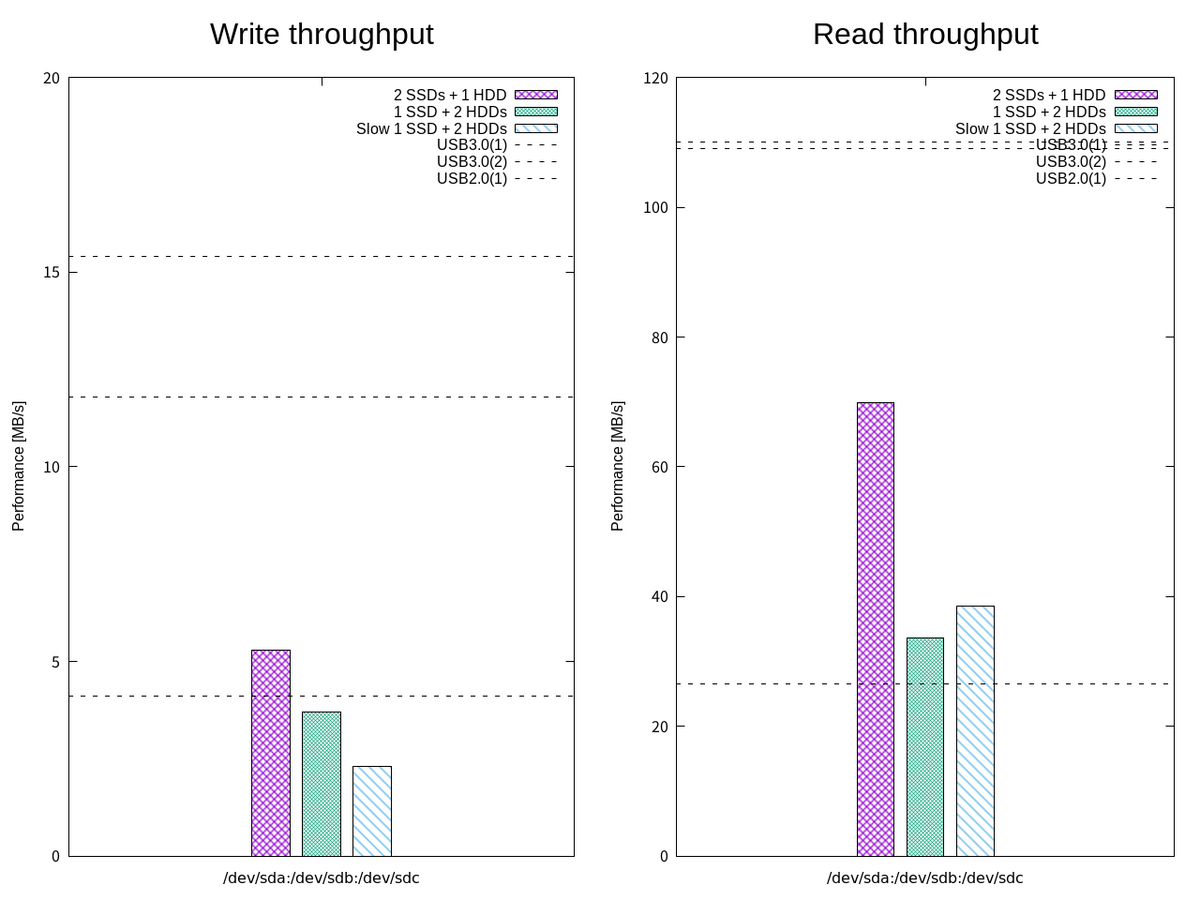
この測定でも、フォアグラウンドでの読み書きを高速なデバイスに割り当て、そうでないデバイスをバックグラウンドに割り当てたほうがパフォーマンスが良い傾向が見られた。
変更履歴
- 2024/04/23: 記事公開
参考文献
- Bcachefs ドキュメント
- Arch Linux による Bcachefs ドキュメント
- Gentoo Linux による Bcachefs ドキュメント
Linuxカーネルのファイルアクセスの処理を追いかける (22) MMC: mmc_rescan
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、カードの識別処理の概要を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
注意
一部の仕様書は非公開となっているため、公開情報からの推測が含まれています。そのため、内容に誤りが含まれている恐れがります。
MMC の rescan
mmc_add_host関数でWorkQueueに追加された detect によって、カード検出処理 mmc_rescan関数を呼び出す。
mmc_rescan関数の定義は次のようになっている。
// 2188: void mmc_rescan(struct work_struct *work) { struct mmc_host *host = container_of(work, struct mmc_host, detect.work); int i; if (host->rescan_disable) return; /* If there is a non-removable card registered, only scan once */ if (!mmc_card_is_removable(host) && host->rescan_entered) return; host->rescan_entered = 1; if (host->trigger_card_event && host->ops->card_event) { mmc_claim_host(host); host->ops->card_event(host); mmc_release_host(host); host->trigger_card_event = false; } /* Verify a registered card to be functional, else remove it. */ if (host->bus_ops) host->bus_ops->detect(host); host->detect_change = 0; /* if there still is a card present, stop here */ if (host->bus_ops != NULL) goto out; mmc_claim_host(host); if (mmc_card_is_removable(host) && host->ops->get_cd && host->ops->get_cd(host) == 0) { mmc_power_off(host); mmc_release_host(host); goto out; } /* If an SD express card is present, then leave it as is. */ if (mmc_card_sd_express(host)) { mmc_release_host(host); goto out; } for (i = 0; i < ARRAY_SIZE(freqs); i++) { unsigned int freq = freqs[i]; if (freq > host->f_max) { if (i + 1 < ARRAY_SIZE(freqs)) continue; freq = host->f_max; } if (!mmc_rescan_try_freq(host, max(freq, host->f_min))) break; if (freqs[i] <= host->f_min) break; } mmc_release_host(host); out: if (host->caps & MMC_CAP_NEEDS_POLL) mmc_schedule_delayed_work(&host->detect, HZ); }
MMCバスや関連するコンポーネントが利用不可能の状態であるとき、 rescan_disable によってカード検出ロジックを無効にすることができる。
導入パッチによると、sus/res中のMMC/SDメモリカード抜去による対応となっている。
v5.15時点では、この変数は mmc_start_host関数によって初期化、mmc_stop_host関数によって設定される。
また、リムーバブルメディアでない(mmc_card_is_removable)場合、 カード検出ロジックを何度も実施する必要がないため、host->rescan_entered に一度実施したかどうかを設定する。
今回のSDメモリカードはリムーバルメディア(non-removable)であるため、以降の処理を呼び出すことになる。
ホストコントローラによっては、カード挿入/抜去時に追加のアクションが必要になる。
そのようなホストコントローラは、trigger_card_eventをセットしておくことで card_eventを呼ぶことができる。
MMCIではそのような制御が不要であるため、trigger_card_eventは設定されていない。
以降のmmc_rescan_try_freq関数の処理が正常に終了している場合、 host->bus_opsに SD/SDIO/MMCカード毎の初期化処理が登録される。
その場合には、抜去や再挿入といったカードの変更を検出するために、bus->bus_ops->detectを呼び出す。
この時に設定される detect_change は、カードの抜去を検知できたことを示す。
ここで、SD specification v7.0 から規格化された SD Express Memory Cards の条件分岐が入る。 SD Express Memory Cards では、後方互換性のために従来のシーケンスでの初期化をするが、ここで分岐することになる。
その後、mmc_rescan_try_freq関数によって周波数の設定を試みる。
ただし、カードによっては初期周波数 400KHz が対応できないことがあるため、400KHz、300KHz、200KHz、100KHz の順にリトライする。
周波数の設定
mmc_rescan_try_freq関数の定義は次のようになっている。
// 2035: static int mmc_rescan_try_freq(struct mmc_host *host, unsigned freq) { host->f_init = freq; pr_debug("%s: %s: trying to init card at %u Hz\n", mmc_hostname(host), __func__, host->f_init); mmc_power_up(host, host->ocr_avail); /* * Some eMMCs (with VCCQ always on) may not be reset after power up, so * do a hardware reset if possible. */ mmc_hw_reset_for_init(host); /* * sdio_reset sends CMD52 to reset card. Since we do not know * if the card is being re-initialized, just send it. CMD52 * should be ignored by SD/eMMC cards. * Skip it if we already know that we do not support SDIO commands */ if (!(host->caps2 & MMC_CAP2_NO_SDIO)) sdio_reset(host); mmc_go_idle(host); if (!(host->caps2 & MMC_CAP2_NO_SD)) { if (mmc_send_if_cond_pcie(host, host->ocr_avail)) goto out; if (mmc_card_sd_express(host)) return 0; } /* Order's important: probe SDIO, then SD, then MMC */ if (!(host->caps2 & MMC_CAP2_NO_SDIO)) if (!mmc_attach_sdio(host)) return 0; if (!(host->caps2 & MMC_CAP2_NO_SD)) if (!mmc_attach_sd(host)) return 0; if (!(host->caps2 & MMC_CAP2_NO_MMC)) if (!mmc_attach_mmc(host)) return 0; out: mmc_power_off(host); return -EIO; }
mmc_rescan_try_freq関数の引数で渡された freq を 初期周波数として host->f_initに設定する。
その後、mmc_power_up関数によって POEWER ON 状態に繊維される。
ただし、ここではmmc_start_host関数によって状態となっているため、処理はスキップする。
ここで、eMMC によっては 電源投入後にハードウェアリセットされないものもある。
そういったデバイスのために、mmc_hw_reset_for_init関数によってホストコントローラからハードウェアリセットさせる仕組み (host->ops->hw_reset) が提供されている。
例えば、Raspberry Pi などで使用されている bcm2835 では hw_reset に独自の処理が設定されていたりする。
しかし、今回の環境では該当しないため、mmc_hw_reset_for_init関数では何も処理をせず、すぐに return される。
SDIOの初期化
sdio_reset関数は、SDIOベースのI/Oカードを初期化するための関数である。
// 202: int sdio_reset(struct mmc_host *host) { int ret; u8 abort; /* SDIO Simplified Specification V2.0, 4.4 Reset for SDIO */ ret = mmc_io_rw_direct_host(host, 0, 0, SDIO_CCCR_ABORT, 0, &abort); if (ret) abort = 0x08; else abort |= 0x08; return mmc_io_rw_direct_host(host, 1, 0, SDIO_CCCR_ABORT, abort, NULL); }
初期化には power reset または CMD52 の二通りのやり方が存在する。
sdio_reset関数では、CMD52を発行することで、これを実現する。
ただし、この処理はCMD0より前に発行しなければならない。
実処理は mmc_io_rw_direct_host関数が担っている。
この関数の詳細は省くが、mmc_wait_for_cmd関数によって指定されたコマンドを発行するものである。
sd_reset関数の一つ目のmmc_io_rw_direct_host関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.205283][ T48] mmc0: starting CMD52 arg 00000c00 flags 00000195
これは、CMD52 によって レジスタ Card Common Control Registers(CCCR) の SDIO_CCCR_ABORTの値を読み込みをしている。
しかし今回は、SDメモリカードであるため ETIMEDOUT となり失敗する。
その後、二つ目のmmc_io_rw_direct_host関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.207221][ T48] mmc0: starting CMD52 arg 80000c08 flags 00000195
これは、CMD52 によって レジスタ Card Common Control Registers(CCCR) の SDIO_CCCR_ABORTの値に0x08を書き込みしている。
しかし今回は、SDメモリカードであるため ETIMEDOUT となり失敗する。
カードを初期状態に戻す
SD規格ファミリーのカードでは特定の初期化シーケンスが必要となる。
mmc_go_idle関数は、初期化シーケンスに移る前に、カードを初期状態する。
mmc_go_idle関数の定義は次のようになっている。
// 139: int mmc_go_idle(struct mmc_host *host) { int err; struct mmc_command cmd = {}; /* * Non-SPI hosts need to prevent chipselect going active during * GO_IDLE; that would put chips into SPI mode. Remind them of * that in case of hardware that won't pull up DAT3/nCS otherwise. * * SPI hosts ignore ios.chip_select; it's managed according to * rules that must accommodate non-MMC slaves which this layer * won't even know about. */ if (!mmc_host_is_spi(host)) { mmc_set_chip_select(host, MMC_CS_HIGH); mmc_delay(1); } cmd.opcode = MMC_GO_IDLE_STATE; cmd.arg = 0; cmd.flags = MMC_RSP_SPI_R1 | MMC_RSP_NONE | MMC_CMD_BC; err = mmc_wait_for_cmd(host, &cmd, 0); mmc_delay(1); if (!mmc_host_is_spi(host)) { mmc_set_chip_select(host, MMC_CS_DONTCARE); mmc_delay(1); } host->use_spi_crc = 0; return err; }
ここで、SPIモードではない場合には Chip Select(CS)がアクティブになることを防ぐ必要がある。
mmc_go_idle関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.212842][ T48] mmc0: starting CMD0 arg 00000000 flags 000000c0
これは、CMD0によってソフトウェアリセットをかけている。
カードの識別
ここから、SD規格ファミリーのデバイスを識別する。
デバイスツリーのProperty(no-sdio,no-sd, no-mmc)を設定していない場合には、SD express/SDIO/SD/MMCの順番に確認していく。
SD express
// 2059: if (!(host->caps2 & MMC_CAP2_NO_SD)) { if (mmc_send_if_cond_pcie(host, host->ocr_avail)) goto out; if (mmc_card_sd_express(host)) return 0; }
mmc_send_if_pcie関数は、動作電圧を確認する__mmc_send_if_cond関数のラッパーとなっている。
ここでは、mmc_send_if_pcie関数の詳細は割愛するが、この関数を実行したとき、次のようなデバッグメッセージが確認することができる。
[ 1.232039][ T48] mmc0: starting CMD8 arg 000001aa flags 000002f5
これは、CMD8によって ocr レジスタに 動作電圧 (PCIe) のサポート状況を確認する。
今回使用しているカードは SD express ではないため、mmc_card_sd_express関数で弾かれる。
SDIO
// 2069: if (!(host->caps2 & MMC_CAP2_NO_SDIO)) if (!mmc_attach_sdio(host)) return 0;
SDIOカードの識別はmmc_attach_sdio関数内のmmc_send_io_op_cond関数で実施される。
// 18: int mmc_send_io_op_cond(struct mmc_host *host, u32 ocr, u32 *rocr) { struct mmc_command cmd = {}; int i, err = 0; cmd.opcode = SD_IO_SEND_OP_COND; cmd.arg = ocr; cmd.flags = MMC_RSP_SPI_R4 | MMC_RSP_R4 | MMC_CMD_BCR; for (i = 100; i; i--) { err = mmc_wait_for_cmd(host, &cmd, MMC_CMD_RETRIES); if (err) break; /* if we're just probing, do a single pass */ if (ocr == 0) break; /* otherwise wait until reset completes */ if (mmc_host_is_spi(host)) { /* * Both R1_SPI_IDLE and MMC_CARD_BUSY indicate * an initialized card under SPI, but some cards * (Marvell's) only behave when looking at this * one. */ if (cmd.resp[1] & MMC_CARD_BUSY) break; } else { if (cmd.resp[0] & MMC_CARD_BUSY) break; } err = -ETIMEDOUT; mmc_delay(10); } if (rocr) *rocr = cmd.resp[mmc_host_is_spi(host) ? 1 : 0]; return err; }
mmc_send_io_ops_cond関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.232680][ T48] mmc0: starting CMD5 arg 00000000 flags 000002e1
SDIOの判定は、CMD5 を発行したときの結果を確認することで確認できる。
今回は、SDメモリカードであるため ETIMEDOUT となり失敗する。
SD
// 2073: if (!(host->caps2 & MMC_CAP2_NO_SD)) if (!mmc_attach_sd(host)) return 0;
SDの識別はmmc_attach_sd関数内のmmc_send_app_op_cond関数で実施される。
// 118: int mmc_send_app_op_cond(struct mmc_host *host, u32 ocr, u32 *rocr) { struct mmc_command cmd = {}; int i, err = 0; cmd.opcode = SD_APP_OP_COND; if (mmc_host_is_spi(host)) cmd.arg = ocr & (1 << 30); /* SPI only defines one bit */ else cmd.arg = ocr; cmd.flags = MMC_RSP_SPI_R1 | MMC_RSP_R3 | MMC_CMD_BCR; for (i = 100; i; i--) { err = mmc_wait_for_app_cmd(host, NULL, &cmd); if (err) break; /* if we're just probing, do a single pass */ if (ocr == 0) break; /* otherwise wait until reset completes */ if (mmc_host_is_spi(host)) { if (!(cmd.resp[0] & R1_SPI_IDLE)) break; } else { if (cmd.resp[0] & MMC_CARD_BUSY) break; } err = -ETIMEDOUT; mmc_delay(10); } if (!i) pr_err("%s: card never left busy state\n", mmc_hostname(host)); if (rocr && !mmc_host_is_spi(host)) *rocr = cmd.resp[0]; return err; }
mmc_send_app_ops_cond関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.233542][ T48] mmc0: starting CMD55 arg 00000000 flags 000000f5 [ 1.233807][ T48] mmc0: starting CMD41 arg 00000000 flags 000000e1
SDIOの判定は、ACMD41 を発行したときの結果を確認することで確認できる。 ちなみに、CMD55は次のコマンドがアプリケーションコマンドであることを表している。
MMC
// 2077: if (!(host->caps2 & MMC_CAP2_NO_MMC)) if (!mmc_attach_mmc(host)) return 0;
MMCの識別はmmc_attach_mmc関数内のmmc_send_op_cond関数で実施される。
// 176: int mmc_send_op_cond(struct mmc_host *host, u32 ocr, u32 *rocr) { struct mmc_command cmd = {}; int i, err = 0; cmd.opcode = MMC_SEND_OP_COND; cmd.arg = mmc_host_is_spi(host) ? 0 : ocr; cmd.flags = MMC_RSP_SPI_R1 | MMC_RSP_R3 | MMC_CMD_BCR; for (i = 100; i; i--) { err = mmc_wait_for_cmd(host, &cmd, 0); if (err) break; /* wait until reset completes */ if (mmc_host_is_spi(host)) { if (!(cmd.resp[0] & R1_SPI_IDLE)) break; } else { if (cmd.resp[0] & MMC_CARD_BUSY) break; } err = -ETIMEDOUT; mmc_delay(10); /* * According to eMMC specification v5.1 section 6.4.3, we * should issue CMD1 repeatedly in the idle state until * the eMMC is ready. Otherwise some eMMC devices seem to enter * the inactive mode after mmc_init_card() issued CMD0 when * the eMMC device is busy. */ if (!ocr && !mmc_host_is_spi(host)) cmd.arg = cmd.resp[0] | BIT(30); } if (rocr && !mmc_host_is_spi(host)) *rocr = cmd.resp[0]; return err; }
mmc_send_op_cond関数が呼ばれたとき、次のようなデバッグメッセージが確認することができる。
[ 1.372548][ T34] mmc0: starting CMD1 arg 00000000 flags 000000e1
MMCの判定は、CMD1 を発行したときの結果を確認することで確認できる。
おわりに
本記事では、カーネル起動時に呼び出される mmc_rescan_try_freq関数について確認した。
この関数では、カード検出ロジックが組み込まれており、カード検出には対応するCMDのレスポンスで判断できる。

変更履歴
- 2024/03/10: 記事公開
参考
- SD規格の概要 | SD Association
- SD規格の概要
- MMC/SDCの使いかた
- MMC/SDC の仕組みの解説
- http://kosakai.world.coocan.jp/sdc.html
- SDカードのコマンドの解説
- LINUX MMC 子系统分析之六 MMC card添加流程分析_mmc rescan流程分析-CSDN博客
- 車載外部ストレージ バックナンバー | シミュレーションの世界に引きこもる部屋
- SDカードの仕様の解説
- SDIOについて #sdio - Qiita
- SDIOの仕様の解説