関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、ext2_write_end関数を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
処理シーケンス図としては、下記の赤枠部分が該当する。
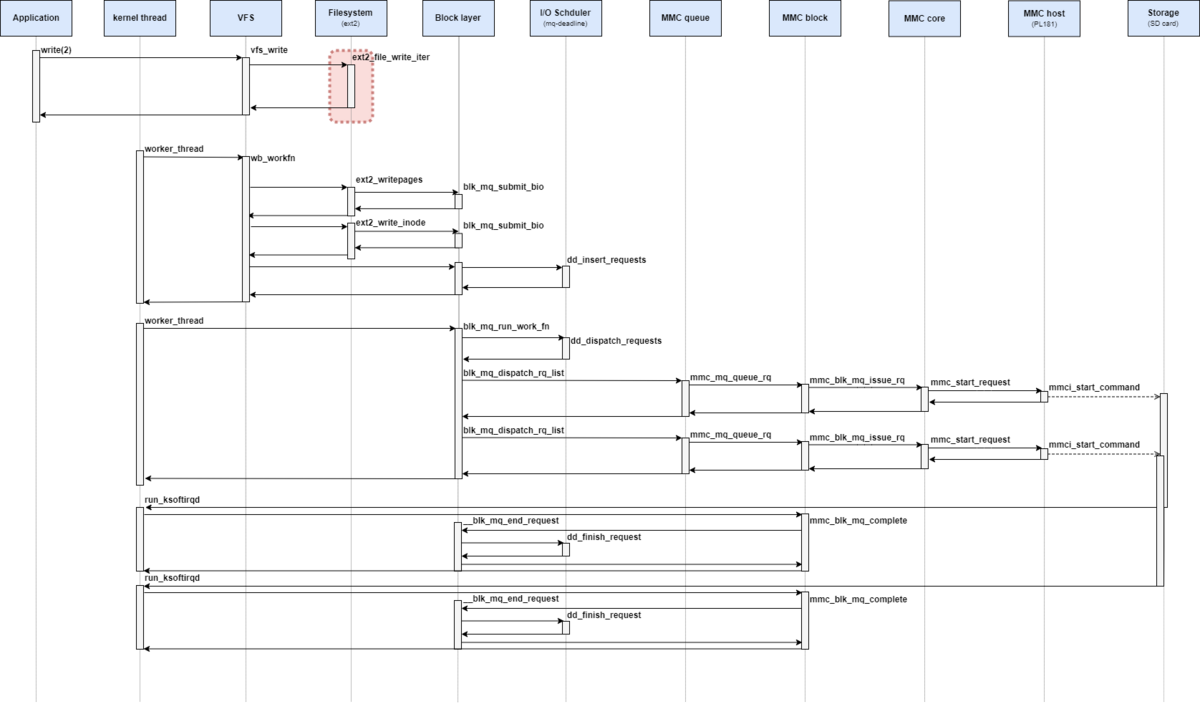
本記事では、ext2ファイルシステムのwrite_iter操作から呼び出されるwrite_end操作を解説する。
write_endの概略
以前解説したwrite_iter操作(generic_file_write_iter)は、write_begin操作とwrite_end操作を呼び出すことになっている。
このwrite_begin操作やwrite_end操作はページキャッシュに対する操作となっており、address_space_opearationsのメンバの一つとして定義される。
write_end操作は、write_iter操作(で呼び出されるgeneric_perform_write関数)から呼び出される。
// 3781: status = a_ops->write_end(file, mapping, pos, bytes, copied, page, fsdata);
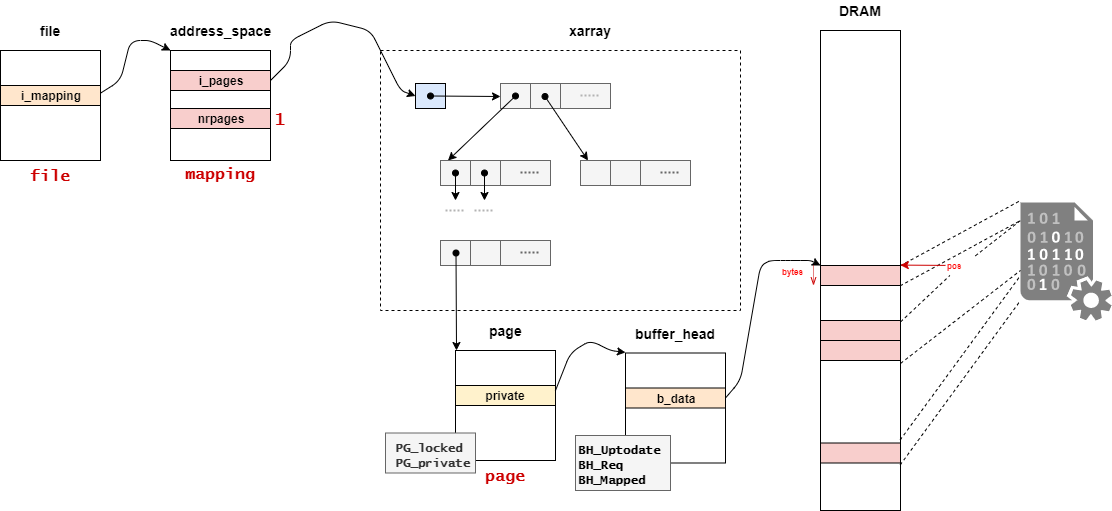
| 変数名 | 値 |
|---|---|
| file | オープンしたファイル |
| mapping | ファイルが持っているページキャッシュのXArray(radix-tree) |
| pos | 書き込み先の位置 |
| bytes | 書き込むバイト数 |
| copied | ページキャッシュにコピーされたバイト数 |
| page | 取得したページを格納する |
| fsdata | ext2ファイルシステムでは使用しない |
ext2ファイルシステムの場合には、write_end操作でext2_write_end関数を実行する。
// 897: static int ext2_write_end(struct file *file, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata) { int ret; ret = generic_write_end(file, mapping, pos, len, copied, page, fsdata); if (ret < len) ext2_write_failed(mapping, pos + len); return ret; }
ext2ファイルシステムでは、汎用APIのgeneric_write_end関数を呼び出す。
// 2168: int generic_write_end(struct file *file, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata) { struct inode *inode = mapping->host; loff_t old_size = inode->i_size; bool i_size_changed = false; copied = block_write_end(file, mapping, pos, len, copied, page, fsdata); /* * No need to use i_size_read() here, the i_size cannot change under us * because we hold i_rwsem. * * But it's important to update i_size while still holding page lock: * page writeout could otherwise come in and zero beyond i_size. */ if (pos + copied > inode->i_size) { i_size_write(inode, pos + copied); i_size_changed = true; } unlock_page(page); put_page(page); if (old_size < pos) pagecache_isize_extended(inode, old_size, pos); /* * Don't mark the inode dirty under page lock. First, it unnecessarily * makes the holding time of page lock longer. Second, it forces lock * ordering of page lock and transaction start for journaling * filesystems. */ if (i_size_changed) mark_inode_dirty(inode); return copied; }
generic_write_end関数の処理は下記の通りとなっている。
- ページキャッシュのフラグを更新する
- バッファキャッシュのフラグを更新する
- ファイルサイズを更新する
まず初めに、メインとなるblock_write_end関数から確認していく。
キャッシュのフラグの更新
block_write_end関数は下記のような定義となっている。
// 2132: int block_write_end(struct file *file, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata) { struct inode *inode = mapping->host; unsigned start; start = pos & (PAGE_SIZE - 1); if (unlikely(copied < len)) { /* * The buffers that were written will now be uptodate, so we * don't have to worry about a readpage reading them and * overwriting a partial write. However if we have encountered * a short write and only partially written into a buffer, it * will not be marked uptodate, so a readpage might come in and * destroy our partial write. * * Do the simplest thing, and just treat any short write to a * non uptodate page as a zero-length write, and force the * caller to redo the whole thing. */ if (!PageUptodate(page)) copied = 0; page_zero_new_buffers(page, start+copied, start+len); } flush_dcache_page(page); /* This could be a short (even 0-length) commit */ __block_commit_write(inode, page, start, start+copied); return copied; }
別スレッドでなどバッファに更新があった場合は、2141行で新規バッファキャッシュの確保など実施する。
今回のケースでは、flush_dcache_page関数でdcacheをフラッシュしたのちに、__block_commit_write関数を呼び出す。
flush_dcache_page関数については下記の記事にて解説済み。
__block_commit_write関数には、書き込み先のinodeと、書き込み対象のページキャッシュpage, 書き込み対象が記載されているオフセット (ページキャッシュの先頭から)start, 書き込み対象が記載されている末尾 start+copiedを渡す。
__block_commit_write関数の定義は下記の定義となっている。
// 2064: static int __block_commit_write(struct inode *inode, struct page *page, unsigned from, unsigned to) { unsigned block_start, block_end; int partial = 0; unsigned blocksize; struct buffer_head *bh, *head; bh = head = page_buffers(page); blocksize = bh->b_size; block_start = 0; do { block_end = block_start + blocksize; if (block_end <= from || block_start >= to) { if (!buffer_uptodate(bh)) partial = 1; } else { set_buffer_uptodate(bh); mark_buffer_dirty(bh); } if (buffer_new(bh)) clear_buffer_new(bh); block_start = block_end; bh = bh->b_this_page; } while (bh != head); /* * If this is a partial write which happened to make all buffers * uptodate then we can optimize away a bogus readpage() for * the next read(). Here we 'discover' whether the page went * uptodate as a result of this (potentially partial) write. */ if (!partial) SetPageUptodate(page); return 0; }
__block_commit_write関数では、各バッファキャッシュのフラグを更新していく。
また、ページキャッシュstruct page構造体からバッファキャッシュstruct buffer_headの取得には、page_buffersマクロを使用する。
// 141: /* If we *know* page->private refers to buffer_heads */ #define page_buffers(page) \ ({ \ BUG_ON(!PagePrivate(page)); \ ((struct buffer_head *)page_private(page)); \ })
PagePrivateマクロにより、struct page構造体にprivateが設定されているかどうか確認する。
struct buffer_head構造体はprivateに関連付けれらているため、これがFalseとなる場合はバグであるのでカーネルパニックさせる。
// 260: #define page_private(page) ((page)->private)
struct page構造体に紐づけられている各struct buffer_head構造体に対して、フラグの更新をする。
更新されたデータにBH_DirtyとBH_Uptodateのフラグを付与する。
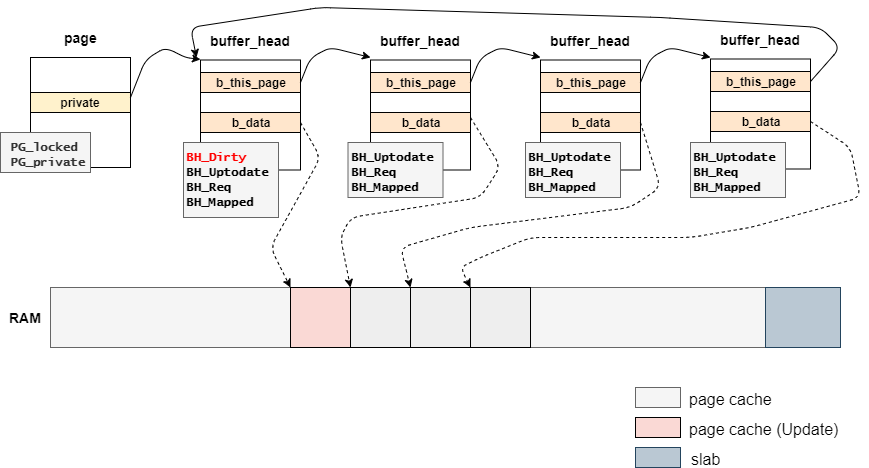
BH_Dirtyのフラグを更新する際には、mark_buffer_dirty関数で実施する。
mark_buffer_dirty関数の定義は下記の通りとなっている。
// 1082: void mark_buffer_dirty(struct buffer_head *bh) { WARN_ON_ONCE(!buffer_uptodate(bh)); trace_block_dirty_buffer(bh); /* * Very *carefully* optimize the it-is-already-dirty case. * * Don't let the final "is it dirty" escape to before we * perhaps modified the buffer. */ if (buffer_dirty(bh)) { smp_mb(); if (buffer_dirty(bh)) return; } if (!test_set_buffer_dirty(bh)) { struct page *page = bh->b_page; struct address_space *mapping = NULL; lock_page_memcg(page); if (!TestSetPageDirty(page)) { mapping = page_mapping(page); if (mapping) __set_page_dirty(page, mapping, 0); } unlock_page_memcg(page); if (mapping) __mark_inode_dirty(mapping->host, I_DIRTY_PAGES); } }
buffer_dirtyマクロ:struct buffer_headのb_stateにBH_Dirtyが設定されていた場合にTrueを返す。test_set_buffer_dirrtyマクロ:struct buffer_headのb_stateにBH_Dirtyをセットする。- マクロ実施前に
BH_Dirtyが設定されていない場合はFalseを返す。 - マクロ実施後に
BH_Dirtyが設定されていない場合はTrueを返す。
- マクロ実施前に
mark_buffer_dirty関数では、初めに別のスレッドで同一のstruct buffer_headがdirtyになっていた場合は、何もせずに処理を終了させる。
cgroup系の処理(lock_page_memcgとunlock_page_memcg)については、省略する。
test_set_buffer_dirtyとTestSetPageDirtyによって、バッファキャッシュとページキャッシュにDirtyフラグを付与する。
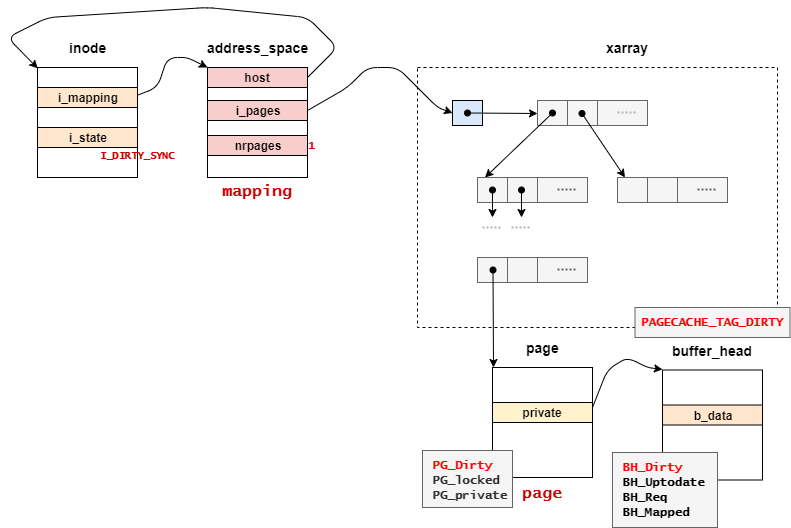
__mark_inode_dirty関数は、writeback用のリストに対象のinodeを追加する。
ただし、下記の記事にてリストに追加されているので、ここでは何も実施しない。
下記のコードで、was_dirtyにI_DIRTY_SYNC (0x1)が代入される。
// 2426: if ((inode->i_state & flags) != flags) { const int was_dirty = inode->i_state & I_DIRTY;
その後の処理は、!was_dirtyで判定されるため、このタイミングでは処理をせず戻る。
// 2460: /* * If the inode was already on b_dirty/b_io/b_more_io, don't * reposition it (that would break b_dirty time-ordering). */ if (!was_dirty) { ...
ファイルサイズの更新
ファイルのもともとのサイズinode->i_sizeがcopiedだけ増えるので、ファイルサイズの更新処理が入る。
// 2178: /* * No need to use i_size_read() here, the i_size cannot change under us * because we hold i_rwsem. * * But it's important to update i_size while still holding page lock: * page writeout could otherwise come in and zero beyond i_size. */ if (pos + copied > inode->i_size) { i_size_write(inode, pos + copied); i_size_changed = true; }
i_size_write関数は、割り込みなどを考慮してinode->i_sizeを更新する。
i_size_read関数と内容が似ているため、ここでは省略する。
おわりに
本記事では、ext2ファイルシステムのwrite_end操作(ext2_write_end)を解説した。
write_end操作は、write_iter操作で書き込んだキャッシュにDirtyフラグを立てて、ファイルのサイズの更新するための操作である。
変更履歴
- 2021/10/09: 記事公開
- 2022/09/19: カーネルバージョンを5.15に変更