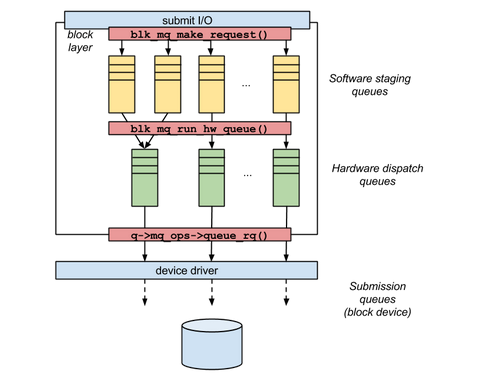
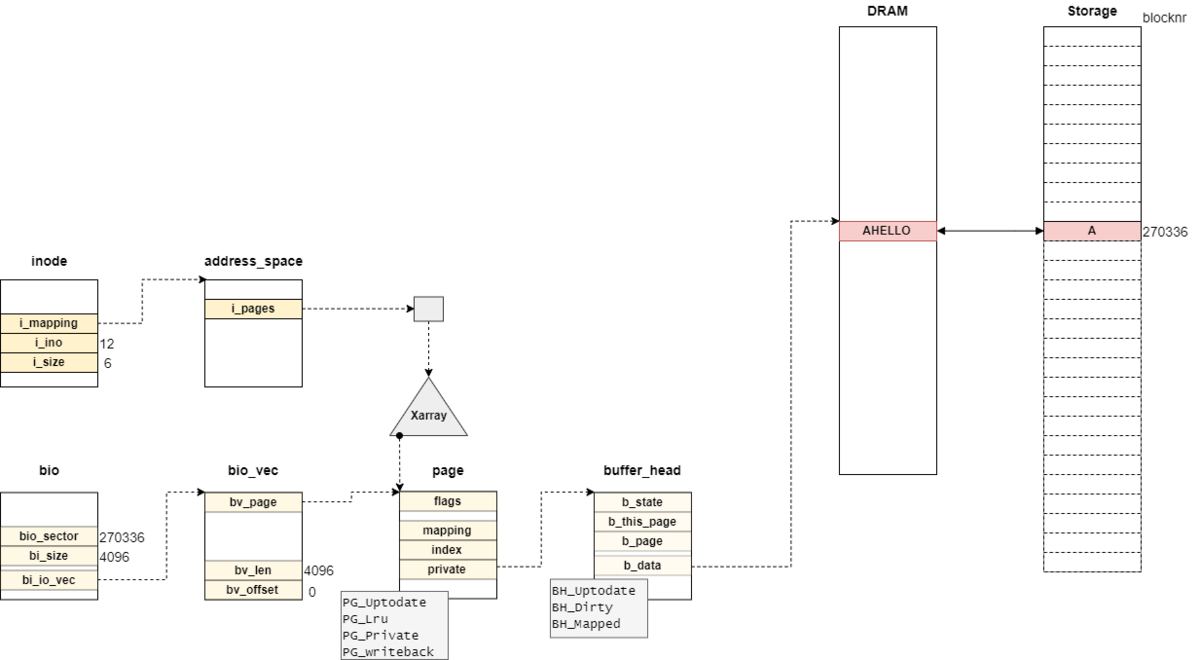
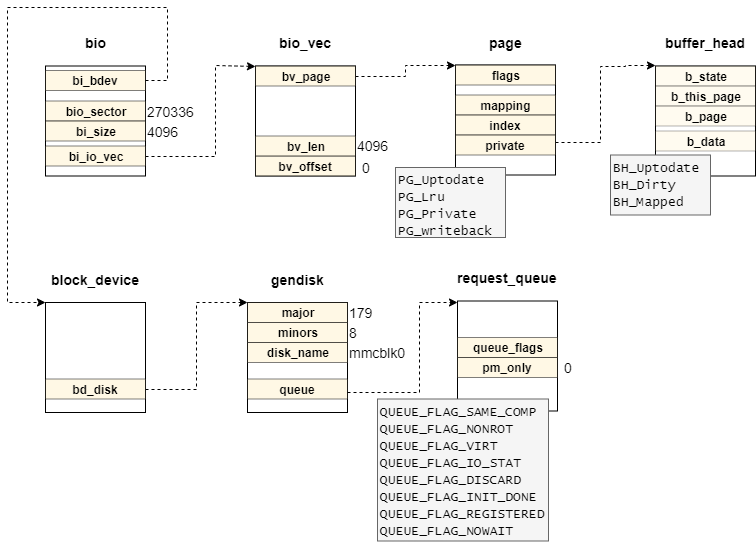
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、mq-deadline I/Oスケジューラのリクエスト挿入処理(insert_requests)とマージ処理解放処理(dd_bio_merge)を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。

mq-deadlineの関数群
dd_bio_merge
dd_bio_merge関数は、elevetor_typeにあるopsのbio_mergeに設定され、blk_mq_update_nr_requests関数から呼び出される関数となっている。
bio_mergeでは、発行される bio が Elevator (または、I/O スケジューラ) にあるrequestと可能であればマージする。
mq-deadline I/O スケジューラで登録されている dd_bio_merge関数の定義は次の通りとなっている。
// 639: static bool dd_bio_merge(struct request_queue *q, struct bio *bio, unsigned int nr_segs) { struct deadline_data *dd = q->elevator->elevator_data; struct request *free = NULL; bool ret; spin_lock(&dd->lock); ret = blk_mq_sched_try_merge(q, bio, nr_segs, &free); spin_unlock(&dd->lock); if (free) blk_mq_free_request(free); return ret; }
dd_bio_merge関数は、mq-deadline I/O スケジューラが保持するロックを確保し、ブロック層汎用のblk_mq_sched_try_merge関数を呼び出す。
このロックを保持している間が、次の処理と排他で動作することになる。
dd_dispatch_requestdd_bio_mergedd_insert_requestsdeadline_##name##_fifo_startdeadline_dispatch##prio##_start
blk_mq_sched_try_merge関数の定義は次の通りとなっている。
// 1106: bool blk_mq_sched_try_merge(struct request_queue *q, struct bio *bio, unsigned int nr_segs, struct request **merged_request) { struct request *rq; switch (elv_merge(q, &rq, bio)) { case ELEVATOR_BACK_MERGE: if (!blk_mq_sched_allow_merge(q, rq, bio)) return false; if (bio_attempt_back_merge(rq, bio, nr_segs) != BIO_MERGE_OK) return false; *merged_request = attempt_back_merge(q, rq); if (!*merged_request) elv_merged_request(q, rq, ELEVATOR_BACK_MERGE); return true; case ELEVATOR_FRONT_MERGE: if (!blk_mq_sched_allow_merge(q, rq, bio)) return false; if (bio_attempt_front_merge(rq, bio, nr_segs) != BIO_MERGE_OK) return false; *merged_request = attempt_front_merge(q, rq); if (!*merged_request) elv_merged_request(q, rq, ELEVATOR_FRONT_MERGE); return true; case ELEVATOR_DISCARD_MERGE: return bio_attempt_discard_merge(q, rq, bio) == BIO_MERGE_OK; default: return false; } }
blk_mq_sched_try_merge関数は、bioがqにあるリクエストとマージを試みる関数となっている。
既存のリクエストとマージすることができた場合には、merged_requestにポインタが設定され、 trueを返す。
blk_mq_sched_try_merge関数では、まず elv_merge関数によって bioが既存の q にあるリクエストにマージできるかチェックする。
bioのマージには、"front merge"(マージ先の先頭に追加) と"back merge"(マージ先の末尾に追加)が存在する。
例えば、ブロック番号4,5,6 に対する bio A,B,C のための request a とマージする場合を考える。

この時、bio X (ブロック番号3) は ”front merge”、bio Y(ブロック番号7)は"back merge"となる。
まずは、マージできるかどうかをelv_merge関数について確認する。
elv_merge関数の定義は次の通りとなっている。
// 303: enum elv_merge elv_merge(struct request_queue *q, struct request **req, struct bio *bio) { struct elevator_queue *e = q->elevator; struct request *__rq; /* * Levels of merges: * nomerges: No merges at all attempted * noxmerges: Only simple one-hit cache try * merges: All merge tries attempted */ if (blk_queue_nomerges(q) || !bio_mergeable(bio)) return ELEVATOR_NO_MERGE; /* * First try one-hit cache. */ if (q->last_merge && elv_bio_merge_ok(q->last_merge, bio)) { enum elv_merge ret = blk_try_merge(q->last_merge, bio); if (ret != ELEVATOR_NO_MERGE) { *req = q->last_merge; return ret; } } if (blk_queue_noxmerges(q)) return ELEVATOR_NO_MERGE; /* * See if our hash lookup can find a potential backmerge. */ __rq = elv_rqhash_find(q, bio->bi_iter.bi_sector); if (__rq && elv_bio_merge_ok(__rq, bio)) { *req = __rq; if (blk_discard_mergable(__rq)) return ELEVATOR_DISCARD_MERGE; return ELEVATOR_BACK_MERGE; } if (e->type->ops.request_merge) return e->type->ops.request_merge(q, req, bio); return ELEVATOR_NO_MERGE; }
elv_merge関数では、ElevetorにキャッシュされているリクエストとI/Oスケジューラに登録されているリクエストからマージできるかどうか検索する。
Elevetorは、最後に扱ったリクエストをlast_mergeとしてキャッシュし、扱ったリクエストを hashで管理している。
ここでキャッシュされたリクエストとマージできない場合には、I/Oスケジューラで管理しているリクエストを検索する。
mq-deadline I/Oスケジューラの場合には、dd_request_merge関数によって赤黒木を検索することになる。

ただし、bioとリクエストキューのフラグによってはマージができないこともある。
そのため、blk_queue_nomerges関数, bio_mergeable関数, blk_queue_noxmerges関数でマージ可能かどうかをチェックする。
確認する項目は次の通りとなっている。
test_bit(QUEUE_FLAG_NOMERGES, &(q)->queue_flags)bio->bi_opf & REQ_NOMERGE_FLAGS)test_bit(QUEUE_FLAG_NOXMERGES, &(q)->queue_flags)
さらに、リクエストの内容によってはマージできないこともあるため、elv_bio_merge_ok関数によるチェックも必要となる。
elv_bio_merge_ok関数の定義は次の通りとなっている。
// 74: bool elv_bio_merge_ok(struct request *rq, struct bio *bio) { if (!blk_rq_merge_ok(rq, bio)) return false; if (!elv_iosched_allow_bio_merge(rq, bio)) return false; return true; }
mq-deadline I/Oスケジューラにが、特別なrequestのマージ条件がない (allow_mergeが未定義)であるため、blk_rq_merge_ok関数によってマージ可能か判定できる。
blk_rq_merge_ok関数の定義は次の通りとなっている。
// 850: bool blk_rq_merge_ok(struct request *rq, struct bio *bio) { if (!rq_mergeable(rq) || !bio_mergeable(bio)) return false; if (req_op(rq) != bio_op(bio)) return false; /* different data direction or already started, don't merge */ if (bio_data_dir(bio) != rq_data_dir(rq)) return false; /* must be same device */ if (rq->rq_disk != bio->bi_bdev->bd_disk) return false; /* only merge integrity protected bio into ditto rq */ if (blk_integrity_merge_bio(rq->q, rq, bio) == false) return false; /* Only merge if the crypt contexts are compatible */ if (!bio_crypt_rq_ctx_compatible(rq, bio)) return false; /* must be using the same buffer */ if (req_op(rq) == REQ_OP_WRITE_SAME && !blk_write_same_mergeable(rq->bio, bio)) return false; /* * Don't allow merge of different write hints, or for a hint with * non-hint IO. */ if (rq->write_hint != bio->bi_write_hint) return false; if (rq->ioprio != bio_prio(bio)) return false; return true; }
blk_rq_merge_ok関数で確認する内容は次の通りとなっている。
- 対象の
requestがマージ可能な操作であるREQ_OP_READREQ_OP_WRITEREQ_OP_DISCARD(blk_discarrd_mergable関数参照)REQ_OP_SECURE_ERASEREQ_OP_WRITE_SAMEREQ_OP_ZONE_OPENREQ_OP_ZONE_CLOSEREQ_OP_ZONE_FINISHREQ_OP_ZONE_RESETREQ_OP_ZONE_RESET_ALL
- 対象の
requestがマージ可能なステータスであるcmd_flagsにREQ_NOMERGE_FLAGSが立っていないrq_flagsにRQF_NOMERGE_FLAGSが立っていない
- マージ対象の
bioがマージ可能なステータスであるbi_opfにREQ_NOMERGE_FLAGSが立っていない
- 対象の
requestとbioが同じ操作であること - 対象の
requestとbioがデータ方向 (Read か Write)が同じであること - 対象の
requestとbioの書き込み先デバイスが同じであること - 対象の
requestとbioのBlock layer data integrity機能でマージ可能であること - 対象の
requestとbioのBlock layer inline encryption機能でマージ可能であること REQ_OP_WRITE_SAMEの場合には、書き込み先のページとオフセットが同じであること- 対象の
requestとbioのwrite hintが同じであること - 対象の
requestとbioのI/O優先度が同じであること
ここで、requestへのマージが可能であれば、そのリクエストをreqに代入し、 ELEVATOR_FRONT_MERGE (または、ELEVATOR_BACK_MERGE)を返す。
もし、elv_merge関数が マージ不可能(ELEVATOR_NO_MERGE)と判断されれば、ここで処理が終了する。
マージできる可能性がある場合には、blk_mq_sched_allow_merge関数によって I/Oスケジューラ独自のチェック関数を呼び出す。 (mq-deadline I/Oスケジューラは未定義)
このチェックも通った場合には、bio_attemp_XXX_merge(XXX = back or front or discard)関数によるマージを試みる。
// 919: static enum bio_merge_status bio_attempt_back_merge(struct request *req, struct bio *bio, unsigned int nr_segs) { const int ff = bio->bi_opf & REQ_FAILFAST_MASK; if (!ll_back_merge_fn(req, bio, nr_segs)) return BIO_MERGE_FAILED; trace_block_bio_backmerge(bio); rq_qos_merge(req->q, req, bio); if ((req->cmd_flags & REQ_FAILFAST_MASK) != ff) blk_rq_set_mixed_merge(req); req->biotail->bi_next = bio; req->biotail = bio; req->__data_len += bio->bi_iter.bi_size; bio_crypt_free_ctx(bio); blk_account_io_merge_bio(req); return BIO_MERGE_OK; } static enum bio_merge_status bio_attempt_front_merge(struct request *req, struct bio *bio, unsigned int nr_segs) { const int ff = bio->bi_opf & REQ_FAILFAST_MASK; if (!ll_front_merge_fn(req, bio, nr_segs)) return BIO_MERGE_FAILED; trace_block_bio_frontmerge(bio); rq_qos_merge(req->q, req, bio); if ((req->cmd_flags & REQ_FAILFAST_MASK) != ff) blk_rq_set_mixed_merge(req); bio->bi_next = req->bio; req->bio = bio; req->__sector = bio->bi_iter.bi_sector; req->__data_len += bio->bi_iter.bi_size; bio_crypt_do_front_merge(req, bio); blk_account_io_merge_bio(req); return BIO_MERGE_OK; } static enum bio_merge_status bio_attempt_discard_merge(struct request_queue *q, struct request *req, struct bio *bio) { unsigned short segments = blk_rq_nr_discard_segments(req); if (segments >= queue_max_discard_segments(q)) goto no_merge; if (blk_rq_sectors(req) + bio_sectors(bio) > blk_rq_get_max_sectors(req, blk_rq_pos(req))) goto no_merge; rq_qos_merge(q, req, bio); req->biotail->bi_next = bio; req->biotail = bio; req->__data_len += bio->bi_iter.bi_size; req->nr_phys_segments = segments + 1; blk_account_io_merge_bio(req); return BIO_MERGE_OK; no_merge: req_set_nomerge(q, req); return BIO_MERGE_FAILED; }
ここでは、bio_attempt_discard_merge関数については取り扱わないものとする。
bio_attempt_back_merge関数とbio_attempt_back_merge関数では、ll_back_merge_fn, ll_front_merge_fn関数によるセグメントを含めたチェックが必要となる。
セグメントは、Scatter-Gather DMAにおけるデータ転送の単位であり、隣接するメモリページ (の一部) となっている。

デバイス(NVMe, SCSIなど)では、一度に扱うことができる書き込み単位や個数が定義されていたりする。 (q->limits.seg_boundary_maskやq->limits.max_segments)。
ll_back_merge_fn, ll_front_merge_fn関数では、req_gap_front_merge,req_gap_front_merge関数によってメモリページのアドレスを確認したり、ll_new_hw_segment関数によるセグメント情報の更新をする。
セグメント観点でもマージができそうであれば、リクエスト req のデータを更新することでbioをマージする。

また、リクエストreqにbioを追加したことによって、既存のリクエスト間でマージできることがある。
例えば、リクエストrqにブロック番号"7,8,9,10,11"のbioに"12"を追加した場合を考える。
この時、リクエストrqの次のノード nextとブロック番号が連続することになる。
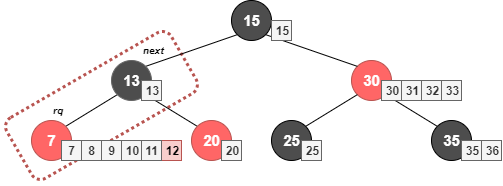
そこで、attempt_back_merge, attempt_front_merge関数によってリクエストとのマージを試みる。
- back_mergeした場合には、次のリクエスト
nextをelv_latter_request関数で取得する。 - front_mergeした場合には前のリクエスト
prevをelv_former_request関数で取得する。
// 817: static struct request *attempt_back_merge(struct request_queue *q, struct request *rq) { struct request *next = elv_latter_request(q, rq); if (next) return attempt_merge(q, rq, next); return NULL; } static struct request *attempt_front_merge(struct request_queue *q, struct request *rq) { struct request *prev = elv_former_request(q, rq); if (prev) return attempt_merge(q, prev, rq); return NULL; }
隣接するリクエストが取得できたら、attemp_merge関数によってリクエストのマージを試みる。
// 725: static struct request *attempt_merge(struct request_queue *q, struct request *req, struct request *next) { if (!rq_mergeable(req) || !rq_mergeable(next)) return NULL; if (req_op(req) != req_op(next)) return NULL; if (rq_data_dir(req) != rq_data_dir(next) || req->rq_disk != next->rq_disk) return NULL; if (req_op(req) == REQ_OP_WRITE_SAME && !blk_write_same_mergeable(req->bio, next->bio)) return NULL; /* * Don't allow merge of different write hints, or for a hint with * non-hint IO. */ if (req->write_hint != next->write_hint) return NULL; if (req->ioprio != next->ioprio) return NULL; /* * If we are allowed to merge, then append bio list * from next to rq and release next. merge_requests_fn * will have updated segment counts, update sector * counts here. Handle DISCARDs separately, as they * have separate settings. */ switch (blk_try_req_merge(req, next)) { case ELEVATOR_DISCARD_MERGE: if (!req_attempt_discard_merge(q, req, next)) return NULL; break; case ELEVATOR_BACK_MERGE: if (!ll_merge_requests_fn(q, req, next)) return NULL; break; default: return NULL; } /* * If failfast settings disagree or any of the two is already * a mixed merge, mark both as mixed before proceeding. This * makes sure that all involved bios have mixable attributes * set properly. */ if (((req->rq_flags | next->rq_flags) & RQF_MIXED_MERGE) || (req->cmd_flags & REQ_FAILFAST_MASK) != (next->cmd_flags & REQ_FAILFAST_MASK)) { blk_rq_set_mixed_merge(req); blk_rq_set_mixed_merge(next); } /* * At this point we have either done a back merge or front merge. We * need the smaller start_time_ns of the merged requests to be the * current request for accounting purposes. */ if (next->start_time_ns < req->start_time_ns) req->start_time_ns = next->start_time_ns; req->biotail->bi_next = next->bio; req->biotail = next->biotail; req->__data_len += blk_rq_bytes(next); if (!blk_discard_mergable(req)) elv_merge_requests(q, req, next); /* * 'next' is going away, so update stats accordingly */ blk_account_io_merge_request(next); trace_block_rq_merge(next); /* * ownership of bio passed from next to req, return 'next' for * the caller to free */ next->bio = NULL; return next; }
dd_request_merge
dd_request_merge関数は、elevetor_typeにあるopsのrequest_mergeに設定され、__blk_mq_sched_bio_merge関数から呼び出される関数となっている。
request_mergeでは、発行される bio が deadline I/O スケジューラ の赤黒木にあるrequestと可能であればマージする。

dd_request_merge関数の定義は次の通りとなっている。
// 607: static int dd_request_merge(struct request_queue *q, struct request **rq, struct bio *bio) { struct deadline_data *dd = q->elevator->elevator_data; const u8 ioprio_class = IOPRIO_PRIO_CLASS(bio->bi_ioprio); const enum dd_prio prio = ioprio_class_to_prio[ioprio_class]; struct dd_per_prio *per_prio = &dd->per_prio[prio]; sector_t sector = bio_end_sector(bio); struct request *__rq; if (!dd->front_merges) return ELEVATOR_NO_MERGE; __rq = elv_rb_find(&per_prio->sort_list[bio_data_dir(bio)], sector); if (__rq) { BUG_ON(sector != blk_rq_pos(__rq)); if (elv_bio_merge_ok(__rq, bio)) { *rq = __rq; if (blk_discard_mergable(__rq)) return ELEVATOR_DISCARD_MERGE; return ELEVATOR_FRONT_MERGE; } } return ELEVATOR_NO_MERGE; }
front_mergeが無効になっている場合は、dd_request_merge関数での処理は何も実施しない。
それ以外の場合には、elv_rb_find関数で対象のbioの書き込みセクタと同じrequestを探索する。
elv_rb_find関数の定義は次の通りとなっている。
// 283: struct request *elv_rb_find(struct rb_root *root, sector_t sector) { struct rb_node *n = root->rb_node; struct request *rq; while (n) { rq = rb_entry(n, struct request, rb_node); if (sector < blk_rq_pos(rq)) n = n->rb_left; else if (sector > blk_rq_pos(rq)) n = n->rb_right; else return rq; } return NULL; }
rb_entry関数により対象の赤黒木root->rb_nodeからrequest取得し、木をたどっていく。
bioと同じ_sectorを持っているrequestが見つかればそれを返し、そうでなければNULLを返す。
requestが見つかった場合には、elv_bio_merge_ok関数によってマージ可能かどうかを判定する。
blk_rq_merge_ok関数については前述した通りとなっている。
dd_limit_depth
dd_limit_depth関数は、elevetor_typeにあるopsのlimit_depthに設定され、__blk_mq_alloc_request関数から呼び出される関数となっている。
limit_depthでは、blk_mq_alloc_data の shallow_depth をI/Oスケジューラ毎に値を設定する。
dd_limit_depth関数の定義は次の通りとなっている。
// 498: static void dd_limit_depth(unsigned int op, struct blk_mq_alloc_data *data) { struct deadline_data *dd = data->q->elevator->elevator_data; /* Do not throttle synchronous reads. */ if (op_is_sync(op) && !op_is_write(op)) return; /* * Throttle asynchronous requests and writes such that these requests * do not block the allocation of synchronous requests. */ data->shallow_depth = dd->async_depth; }
dd_limit_depth関数では、非同期要求が施入できるキューの深さ async_depthに設定する。
dd_prepare_request
dd_prepare_request関数は、elevetor_typeにあるopsのprepare_requestに設定され、blk_mq_rq_ctx_init関数から呼び出される関数となっている。
prepare_requestでは、blk_mq_rq_ctx_init をI/Oスケジューラ毎に必要に応じて初期化する。
prepare_request関数の定義は次の通りとなっている。
// 731: /* Callback from inside blk_mq_rq_ctx_init(). */ static void dd_prepare_request(struct request *rq) { rq->elv.priv[0] = NULL; }
dd_insert_requests
dd_insert_requests関数は、elevetor_typeにあるopsのinsert_requestsに設定され、blk_mq_sched_insert_request関数などから呼び出される関数となっている。
insert_requestsでは、Software Staging queues に request を追加する。

dd_insert_requests関数の定義は次の通りとなっている。
// 713: static void dd_insert_requests(struct blk_mq_hw_ctx *hctx, struct list_head *list, bool at_head) { struct request_queue *q = hctx->queue; struct deadline_data *dd = q->elevator->elevator_data; spin_lock(&dd->lock); while (!list_empty(list)) { struct request *rq; rq = list_first_entry(list, struct request, queuelist); list_del_init(&rq->queuelist); dd_insert_request(hctx, rq, at_head); } spin_unlock(&dd->lock); }
dd_insert_requests関数は、リクエスト毎にdd_insert_request関数を呼び出す。
// 672: static void dd_insert_request(struct blk_mq_hw_ctx *hctx, struct request *rq, bool at_head) { struct request_queue *q = hctx->queue; struct deadline_data *dd = q->elevator->elevator_data; const enum dd_data_dir data_dir = rq_data_dir(rq); u16 ioprio = req_get_ioprio(rq); u8 ioprio_class = IOPRIO_PRIO_CLASS(ioprio); struct dd_per_prio *per_prio; enum dd_prio prio; LIST_HEAD(free); lockdep_assert_held(&dd->lock); /* * This may be a requeue of a write request that has locked its * target zone. If it is the case, this releases the zone lock. */ blk_req_zone_write_unlock(rq); prio = ioprio_class_to_prio[ioprio_class]; dd_count(dd, inserted, prio); rq->elv.priv[0] = (void *)(uintptr_t)1; if (blk_mq_sched_try_insert_merge(q, rq, &free)) { blk_mq_free_requests(&free); return; } trace_block_rq_insert(rq); per_prio = &dd->per_prio[prio]; if (at_head) { list_add(&rq->queuelist, &per_prio->dispatch); } else { deadline_add_rq_rb(per_prio, rq); if (rq_mergeable(rq)) { elv_rqhash_add(q, rq); if (!q->last_merge) q->last_merge = rq; } /* * set expire time and add to fifo list */ rq->fifo_time = jiffies + dd->fifo_expire[data_dir]; list_add_tail(&rq->queuelist, &per_prio->fifo_list[data_dir]); } }
‘dd_insert_request‘関数は、次のような処理を実施する。
- sysfsからリクエストの統計を取得できるように
dd_countマクロでinsertedをインクリメントする。 - 簡単に既存のリクエストにマージできるのであれば、マージを試みる
- リクエストをmq-deadline I/Oスケジューラの赤黒木とFIFO (または、dispatchキュー)に挿入する
mq-deadline I/Oスケジューラでは、リクエストの統計をユーザランドから確認できるように sysfs インターフェースに統計情報を記録している。
dd_countマクロの定義は次のようになっている。
// 107: #define dd_count(dd, event_type, prio) do { \ struct io_stats *io_stats = get_cpu_ptr((dd)->stats); \ \ BUILD_BUG_ON(!__same_type((dd), struct deadline_data *)); \ BUILD_BUG_ON(!__same_type((prio), enum dd_prio)); \ local_inc(&io_stats->stats[(prio)].event_type); \ put_cpu_ptr(io_stats); \ } while (0)
この結果により、queued
# cat /sys/kernel/debug/block/mmcblk0/sched/queued
/sys/kernel/debug/block/mmcblk0/sched/queued
0 1 0
ここでは、リクエストキューがマージに対応しているかどうか確認する rq_mergeableマクロとマージを試みる elv_attempt_insert_merge関数の結果の論理積となる。
elv_attempt_insert_merge関数では、back mergeが可能であればマージする関数となっている。
既存リクエストへのマージをトライアルはblk_mq_sched_try_insert_merge関数によって実施される。
blk_mq_sched_try_insert_merge関数の定義は次のようになっている。
// 402: bool blk_mq_sched_try_insert_merge(struct request_queue *q, struct request *rq, struct list_head *free) { return rq_mergeable(rq) && elv_attempt_insert_merge(q, rq, free); }
マージする場合と同様にrq_mergeable関数がリクエストの状態を確認し、blk_attempt_req_merge関数がマージする処理となる。
blk_attempt_req_merge関数の定義は次のようになっている。
// 359: bool elv_attempt_insert_merge(struct request_queue *q, struct request *rq, struct list_head *free) { struct request *__rq; bool ret; if (blk_queue_nomerges(q)) return false; /* * First try one-hit cache. */ if (q->last_merge && blk_attempt_req_merge(q, q->last_merge, rq)) { list_add(&rq->queuelist, free); return true; } if (blk_queue_noxmerges(q)) return false; ret = false; /* * See if our hash lookup can find a potential backmerge. */ while (1) { __rq = elv_rqhash_find(q, blk_rq_pos(rq)); if (!__rq || !blk_attempt_req_merge(q, __rq, rq)) break; list_add(&rq->queuelist, free); /* The merged request could be merged with others, try again */ ret = true; rq = __rq; } return ret; }
おわりに
本記事では、mq-deadline I/Oスケジューラのdd_bio_merge関数とdd_insert_requests関数を確認した。
変更履歴
- 2023/04/30: 記事公開
参考
- Deadline IO scheduler tunables — The Linux Kernel documentation
- Deadline IO scheduler 公式ドキュメント
- https://blog.51cto.com/u_15061941/3859244
- 中国の記事だが、v4.20のmq-deadlineについてソースコード分析する
- LinuxのI/OスケジューラのDeadlineを調べてチューニングしてみた - YOMON8.NET
- Deadline I/Oスケジューラのパラメータチューニング