Linuxカーネルのファイルアクセスの処理を追いかける (19) MMC: initialization
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、MMCサブシステムの初期化処理について確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
MMCサブシステム
マルチメディアカード (MMC) は 1997年に発表されたメモリーカードの規格の一つである。
SDメモリカード (SDC) は、MMC と互換性のある規格で、デジタルカメラや携帯電話など現在でも幅広く利用されている。
Linux では、e.MMC や SDカード といったストレージメディアをMMCサブシステムで扱う。

- MMC block: 上位の汎用ブロックデバイスからのI/O要求を受け取り、データを管理する
- MMC core: 対象となるストレージメディアが SDC や MMC かといった規格を判別し、規格固有の制御(スピードモードの設定など)する
- MMC host:: ホストコントローラのレジスタを操作、機種依存の差をここで実装する
Linuxデバイスモデル
Linuxでは、システムの接続状態を管理にできるように共通フレームワーク (Linuxデバイスモデル) が提供されている。
Linuxデバイスモデルは、バス、デバイス、ドライバの3つで構成される。

また、これらに加えて、クラスと呼ばれる概念も存在する。 クラスでは、デバイスを上位レベルでとらえたもので、下位レベルを抽象化する。
MMCコアの初期化
Linuxでは、カーネル起動時にあらかじめ登録されていたコールバック関数 initcall を呼ぶ機構がある。
initcallは、ブートプロセス中のいくつかの段階で多くの関数を呼び出すことができ、多くのアーキテクチャやドライバで使用される。
initcallのタイミング (レベル) とそのマクロ名の対応関係は次のようになっている。
| Macro | Level |
|---|---|
| pure_initcall | 0 |
| core_initcall | 1 |
| postcore_initcall | 2 |
| arch_initcall | 3 |
| subsys_initcall | 4 |
| fs_initcall | 5 |
| rootfs_initcall | rootfs |
| device_initcall | 6 |
| late_initcall | 7 |
MMCでは、 mmc_init関数や mmc_blk_init関数(device)によって最低限の初期化処理がされる。
まず、subsys_initcallの mmc_init関数から確認する。
// 2295: static int __init mmc_init(void) { int ret; ret = mmc_register_bus(); if (ret) return ret; ret = mmc_register_host_class(); if (ret) goto unregister_bus; ret = sdio_register_bus(); if (ret) goto unregister_host_class; return 0; unregister_host_class: mmc_unregister_host_class(); unregister_bus: mmc_unregister_bus(); return ret; }
mmc_init関数では、MMC共通の次のような初期化処理を実施する。
- mmcバス (
mmc) の追加 - mmcクラス (
mmc_host) の追加 - mmcバス (
sdio) の追加
mmcバスの追加
mmcバスは mmc_register_bus関数によって追加される。
mmc_register_bus関数と、その引数で必要となる mmc_bus_typeの定義は次の通りとなっている。
// 226: static struct bus_type mmc_bus_type = { .name = "mmc", .dev_groups = mmc_dev_groups, .match = mmc_bus_match, .uevent = mmc_bus_uevent, .probe = mmc_bus_probe, .remove = mmc_bus_remove, .shutdown = mmc_bus_shutdown, .pm = &mmc_bus_pm_ops, }; int mmc_register_bus(void) { return bus_register(&mmc_bus_type); }
Linuxでは、デバイスモデルの基本的なデータ構造として kobject(kset) 構造体で表現されている。
これらは オブジェクトの参照カウントやリンク参照による階層構造といった機能を持っている。

デバイスモデルの各オブジェクトは kobject を Wrap した形式で表現される。
bus_register関数は、busサブシステムに対して、引数で渡した bus_type構造体のオブジェクトを子オブジェクトとして追加する関数である。
詳細は省くが、mmc_register_bus関数を実行したことで、既存の busオブジェクトに mmcの subsys_private(kobjectを内包する)オブジェクトが追加される。

mmc_hostクラスの追加
mmc_register_host_class関数と、その引数で必要となる mmc_host_classの定義は次の通りとなっている。
// 83: static struct class mmc_host_class = { .name = "mmc_host", .dev_release = mmc_host_classdev_release, .pm = MMC_HOST_CLASS_DEV_PM_OPS, }; int mmc_register_host_class(void) { return class_register(&mmc_host_class); }
mmc_register_host_class関数は、classサブシステムに対して、引数で渡したclass構造体のオブジェクトを子オブジェクトとして追加する関数である。

sdioバスの追加
sdio_register_bus関数と、その引数で必要となる sdio_bus_typeの定義は次の通りとなっている。
// 246: static struct bus_type sdio_bus_type = { .name = "sdio", .dev_groups = sdio_dev_groups, .match = sdio_bus_match, .uevent = sdio_bus_uevent, .probe = sdio_bus_probe, .remove = sdio_bus_remove, .pm = &sdio_bus_pm_ops, }; int sdio_register_bus(void) { return bus_register(&sdio_bus_type); }
SDIOは、本記事の対象外であるため割愛する。
MMCブロックの初期化
次に、mmc_blk_init関数から確認する。
// 3019: static int __init mmc_blk_init(void) { int res; res = bus_register(&mmc_rpmb_bus_type); if (res < 0) { pr_err("mmcblk: could not register RPMB bus type\n"); return res; } res = alloc_chrdev_region(&mmc_rpmb_devt, 0, MAX_DEVICES, "rpmb"); if (res < 0) { pr_err("mmcblk: failed to allocate rpmb chrdev region\n"); goto out_bus_unreg; } if (perdev_minors != CONFIG_MMC_BLOCK_MINORS) pr_info("mmcblk: using %d minors per device\n", perdev_minors); max_devices = min(MAX_DEVICES, (1 << MINORBITS) / perdev_minors); res = register_blkdev(MMC_BLOCK_MAJOR, "mmc"); if (res) goto out_chrdev_unreg; res = mmc_register_driver(&mmc_driver); if (res) goto out_blkdev_unreg; return 0; out_blkdev_unreg: unregister_blkdev(MMC_BLOCK_MAJOR, "mmc"); out_chrdev_unreg: unregister_chrdev_region(mmc_rpmb_devt, MAX_DEVICES); out_bus_unreg: bus_unregister(&mmc_rpmb_bus_type); return res; }
mmc_init関数では、MMC共通の次のような初期化処理を実施する。
- mmcバス (
mmc_rpmb) とrpmb(Replay Protected Memory Block)の追加 - ブロックデバイス (
mmc) の追加 - mmcドライバ (
mmcblk) の追加
mmc_rpmbバスの追加
Replay Protected Memory Block (RPMB) は、共通鍵を利用して、HostとDeviceの間のデータを検証するセキュリティに関係するプロトコルである。
MMC v4.4 specification によって、MMC が RPMB のサポートが仕様化され、近年の e·MMCデバイスでは デフォルトで RPMBパーティションとして認識されるだろう。
ただし、ファイルアクセスの本質とは離れるため RPMB の関連の確認は割愛する。
mmcブロックデバイスの追加
register_blkdevマクロによってブロックデバイス mmc を登録する。
// 286: #define register_blkdev(major, name) \ __register_blkdev(major, name, NULL)
register_blkdevマクロは __register_blkdev関数 のWarpperとなっている。
__register_blkdev関数の定義は次の通りとなっている。
// 231: int __register_blkdev(unsigned int major, const char *name, void (*probe)(dev_t devt)) { struct blk_major_name **n, *p; int index, ret = 0; mutex_lock(&major_names_lock); /* temporary */ if (major == 0) { for (index = ARRAY_SIZE(major_names)-1; index > 0; index--) { if (major_names[index] == NULL) break; } if (index == 0) { printk("%s: failed to get major for %s\n", __func__, name); ret = -EBUSY; goto out; } major = index; ret = major; } if (major >= BLKDEV_MAJOR_MAX) { pr_err("%s: major requested (%u) is greater than the maximum (%u) for %s\n", __func__, major, BLKDEV_MAJOR_MAX-1, name); ret = -EINVAL; goto out; } p = kmalloc(sizeof(struct blk_major_name), GFP_KERNEL); if (p == NULL) { ret = -ENOMEM; goto out; } p->major = major; p->probe = probe; strlcpy(p->name, name, sizeof(p->name)); p->next = NULL; index = major_to_index(major); spin_lock(&major_names_spinlock); for (n = &major_names[index]; *n; n = &(*n)->next) { if ((*n)->major == major) break; } if (!*n) *n = p; else ret = -EBUSY; spin_unlock(&major_names_spinlock); if (ret < 0) { printk("register_blkdev: cannot get major %u for %s\n", major, name); kfree(p); } out: mutex_unlock(&major_names_lock); return ret; }
__register_blkdev関数では、グローバル変数の配列 major_names の major番目にnameを登録することができる。
mmcblkドライバの追加
mmc_register_driver関数と、その引数で必要となる mmc_driverの定義は次の通りとなっている。
// 3009: static struct mmc_driver mmc_driver = { .drv = { .name = "mmcblk", .pm = &mmc_blk_pm_ops, }, .probe = mmc_blk_probe, .remove = mmc_blk_remove, .shutdown = mmc_blk_shutdown, };
// 251: int mmc_register_driver(struct mmc_driver *drv) { drv->drv.bus = &mmc_bus_type; return driver_register(&drv->drv); }
mmc_register_driver関数は、driversサブシステムに対して、引数で渡した mmc_driver構造体のオブジェクトを子オブジェクトとして追加する関数である。

MMCホストの初期化
Arm Versatile Express boards (vexpress-a9) では、MMCホストのドライバとして mmci-pl18x を使うことになる。
mmci-pl18x ドライバでは、Advanced Microcontroller Bus Architecture (AMBA) と呼ばれる規格に則った実装となっている。
amba_driver構造体で定義されたデータ構造を module_amba_driverマクロを呼び出すことで、ambaバスにドライバを登録/解除することができる。
// 2445: static struct amba_driver mmci_driver = { .drv = { .name = DRIVER_NAME, .pm = &mmci_dev_pm_ops, }, .probe = mmci_probe, .remove = mmci_remove, .id_table = mmci_ids, }; module_amba_driver(mmci_driver);
// 217: #define module_amba_driver(__amba_drv) \ module_driver(__amba_drv, amba_driver_register, amba_driver_unregister)
module_amba_driverマクロは、module_driverマクロのwrapperとなっている。
module_driverマクロでは、amba_driver_register関数とamba_driver_unregister関数を追加する。
// 258: #define module_driver(__driver, __register, __unregister, ...) \ static int __init __driver##_init(void) \ { \ return __register(&(__driver) , ##__VA_ARGS__); \ } \ module_init(__driver##_init); \ static void __exit __driver##_exit(void) \ { \ __unregister(&(__driver) , ##__VA_ARGS__); \ } \ module_exit(__driver##_exit);
// 341: int amba_driver_register(struct amba_driver *drv) { if (!drv->probe) return -EINVAL; drv->drv.bus = &amba_bustype; return driver_register(&drv->drv); }
// 359: void amba_driver_unregister(struct amba_driver *drv) { driver_unregister(&drv->drv); }
amba_driver_register関数は、driversサブシステムに対して、引数で渡した amba_driver構造体のオブジェクトを子オブジェクトとして追加する関数である。

おわりに
本記事では、カーネル起動時に呼び出される mmc_init関数と mmc_blk_init関数について確認した。
これらの初期化によって、sysfs は次のようなエントリが追加される。(mmc_rpmbバスは省略)
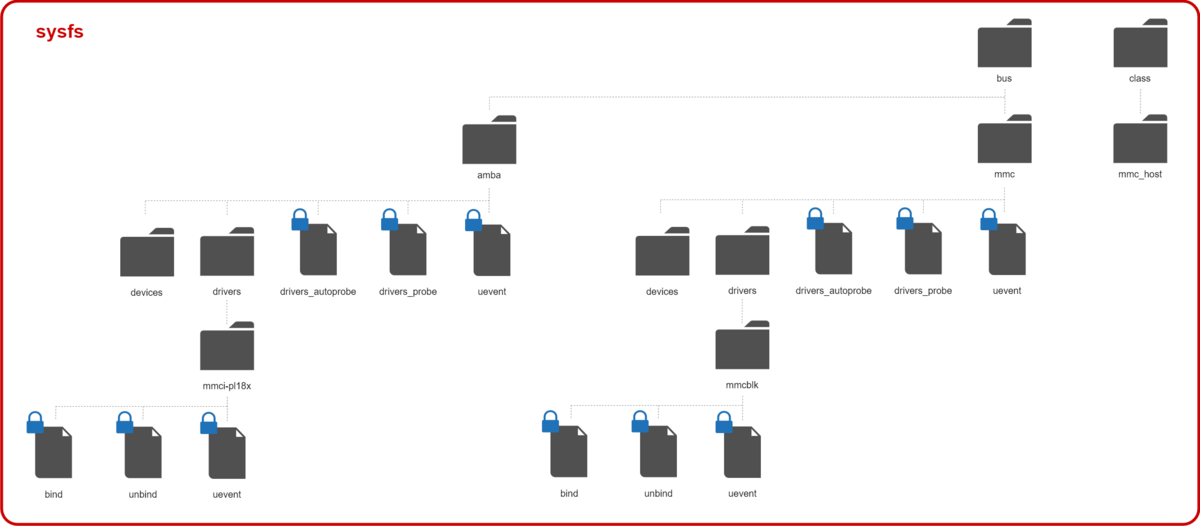
変更履歴
- 2023/12/10: 記事公開
- 2023/12/23: mmcホストの初期化を追加
参考
- Linuxのmmcドライバ概要 #kernel - Qiita
- Linux Kernel MMC Storage driver Overview | PPT
- MMC 概要
- Linux内核详解:MMC子系统架构与SD总线协议-CSDN博客
- mmc subsystem 概要
- Linux内核4.14版本——mmc core(2)——bus模块_linux的mmc的host、card和bus关系-CSDN博客
- Linux MMC framework(1)_软件架构
- mmc subsystem概要
- MMC/SDCの使いかた
- MMC/SDC概要
- https://elinux.org/images/9/91/Clement-sd-mmc-high-speed-support-in-linux-kernel_0.pdf
- 2017年における MMC/SDCの high speedサポートの紹介記事
- Linux 2.6 Device Model
- The Linux Kernel Device Model — The Linux Kernel documentation
- Linux Device Model — The Linux Kernel documentation
- Linuxのドライバの初期化が呼ばれる流れ #kernel - Qiita
- ドライバのが呼ばれる順番
- JVNVU#97690270 (RPMB脆弱性)を簡単に確認してみた #Linux - Qiita
- RPMB脆弱性の簡易解説
I/O スケジューラの違いによるストレージの読み込み性能を比較する
注意
本記事は、特定の環境下における特定の読み込みパターンを測定した結果であり、 I/O スケジューラの優劣を決めるものではない。
関連記事
概要
本記事では、I/Oスケジューラの違いによって、次のようなストレージへの読み込み特性について確認した。
- スループット
- BIO毎のレイテンシ
- CPU使用率
今回の環境(Raspberry Pi 4 と SSD/SDカード) と測定方法では、それぞれのI/Oスケジューラ (パラメータはデフォルト値) による大きな違いは見られなかった。
はじめに
汎用的なストレージデバイスは、その特性からまとまったデータ量のI/Oであるほうが効率が良いとされている。
しかし実際には、アプリケーションがそういったI/Oが発行されるとは限らない。
Linuxカーネルには、I/Oスケジューラと呼ばれるI/Oリクエストの処理順番を入れ替えたり、まとめたりすることで応答速度やスループットを向上を目的とした機能である。
I/Oスケジューラにはそれぞれ異なる特性があり、システム環境やストレージデバイスなどによって、I/O性能が変わってくる。
ここでは、OSの機能の一機能 "I/Oスケジューラ"に注目して、それぞれの読み込みの違いを確認する。
Linux Kernel v5.15 では、mq-deadline、bfq (Budget Fair Queuing)、kyber がサポートしている。
mq-deadline の概要
mq-deadlineは、デッドラインを設けることでリクエストの処理開始時間を保障する I/Oスケジューラの一つである。
Linux Kernel v5.15 のデフォルト値では、書き込みリクエストの有効期限は 5秒 、読み込みリクエストの有効期限は 500 ミリ秒 となる。
bfq の概要
bfq は、単一のアプリケーションがすべての帯域幅を使用しないようスケジュールする I/Oスケジューラの一つである。
Linux Kernel 5.15 のデフォルト値では、スループットの最大化よりもレイテンシの最小化を達成することを目的とする。
そのため、低速のCPUに対して高速なストレージデバイスに対しては、bfq I/Oスケジューラは不向きとなることがある。
kyber の概要
mq-deadlineは、ブロックレイヤに渡されたI/O要求のレイテンシを計算し、目標とするレイテンシを達成するような I/Oスケジューラの一つである。
Linux Kernel v5.15 のデフォルト値では、目標とする読み込みレイテンシは 2ミリ秒 、同期書き込みのレイテンシは 10 ミリ秒 となる。
目的
I/Oスケジューラの違いによって、次のような読み込み特性がどのように変化するかを調査する。
- スループットの計測
- BIO毎のレイテンシ計測
- CPU使用率の計測
実行環境
Raspberry Pi 4 Model B (Raspberry Pi 4) は microSDカード経由でRaspberry Pi OSを起動させる。 また、Raspbery Pi 4 の USB3.0ポートにポータブルSSDを接続する。

ここで使用する実験環境について下記に示す。
| 項目 | 概要 |
|---|---|
| Board | Raspberry Pi 4 |
| CPU | Cortex-A72 (ARM v8) 1.5GHz |
| メモリ | 4GB LPDDR4-3200 |
| OS | Raspberry Pi OS (64 bit) (Feb 21st 2023) |
| kernel | v5.15.92 |
| ファイルシステム | ext4 |
| BCC Utilities | bpfcc-tools version 0.18.0+ds-2 |
| ext4 Utilities | E2fsprogs version 1.46.2 |
| fio | fio-3.25-2 |
| OS格納先ストレージ | microSDHC 16GB Class10 UHS-1 |
| 計測用ストレージ(外付けSSD) | SL-MG5 |
| 計測用ストレージ(SDカード) | SF-E64 |
この実験では、 外付け SSD/SDカードに対する読み込みを計測する。
計測方法
ストレージへの読み込みをする負荷プログラムとして fio を実行し、次のような情報を取得することでI/Oスケジューラの比較する。
- スループットの計測
- BIO毎のレイテンシ計測
- CPU使用率の計測
毎計測時、デフォルトパラメータでmkfsコマンドの実行と、 echo 3 > /proc/sys/vm/drop_cachesによるキャッシュ解放を実施する。
biosnoopとmpstatによる計測は、ファイルシステムをマウント(mount)してからアンマウント(umount)までとする。
その区間に負荷プログラム(fio)を実行し、そのときのIO要求のデータを使用する。
計測の流れを図にすると下記のようになる。
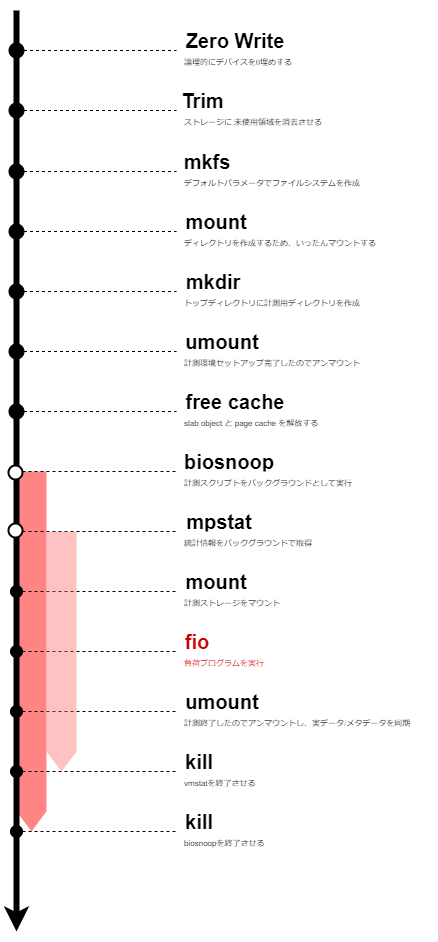
ここで、白色の丸は "非同期処理"であり、黒色の丸は "同期処理" を表している。
また、各実験は3回ずつ施行する。
スループットの計測
fioでは、合計 32GB となるような 次の4パターンを2つのアクセス手法 (sequential/random) のジョブとして実行する。
| write パターン1 |
write パターン2 |
write パターン3 |
write パターン4 |
|
|---|---|---|---|---|
| bs | 1M | 1M | 1M | 1M |
| size | 32G | 8G | 8G | 8G |
| numjobs | 1 | 4 | 1 | 4 |
| iodepth | 1 | 1 | 4 | 4 |
この実験では、異なる計測用ストレージとI/Oスケジューラに対して、これらを実行する。
BIO毎のレイテンシ計測
BPF Compiler Collection (BCC) を利用することで、ユーザプログラムから IO要求発行に任意の処理を追加し、IO要求の内容を確認する。
今回の計測では、BCCのサンプルスクリプトとして提供されている biosnoop を利用する。
biosnoop は、IO要求発行(blk_mq_start_request)と IO完了(blk_account_io_done) における BIO のステータスを確認することができる。
このスクリプトを実行することで下記のような結果を得ることができる。
TIME(s) COMM PID DISK T SECTOR BYTES QUE(ms) LAT(ms)
0.000000 mount 4349 sda R 2050 1024 0.06 0.46
0.000396 mount 4349 sda R 2048 4096 0.05 0.19
0.000713 mount 4349 sda R 2056 4096 0.05 0.18
0.000826 mount 4349 sda R 2064 4096 0.05 0.18
0.000968 mount 4349 sda R 2072 4096 0.05 0.16
0.001165 mount 4349 sda R 2080 4096 0.09 0.17
ここから読み込み先デバイス (DISK) と アクセス方向 (T) でフィルターをかける。
ここから、タイムスタンプ (TIME), オフセット (SECTOR)とサイズ (SIZE)を抽出する。
CPU使用率の計測
mpstatを利用することで、次のようなプロセッサ関連の統計情報を表示することができる。
Linux 5.15.92-v8 (raspberrypi) 09/09/2023 _aarch64_ (4 CPU)
10:59:25 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:59:26 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:59:27 PM all 0.00 0.00 0.25 0.00 0.00 0.00 0.00 0.00 0.00 99.75
10:59:28 PM all 0.25 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.75
10:59:29 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:59:30 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
今回は、CPU使用率を確認するために mpstat をバックグラウンドで実行する。
準備
Linuxカーネルの再構築
BCCは、特定のカーネルコンフィグに依存しているが、Raspberry pi OS のデフォルトで無効となっている。
そこで、公式手順に基に、独自にカーネルのビルド・インストールを実施する。
カーネルコンフィグは、デフォルトのカーネルコンフィグから次のように修正する。
user@hostname:~/linux$ ./scripts/diffconfig .config.old .config
IKHEADERS n -> y
また、Kyber と BFQ はデフォルトで無効となっているため、カーネルコンフィグを更新しておく。
user@hostname:~/linux$ ./scripts/diffconfig .config.old .config
MQ_IOSCHED_KYBER=y
IOSCHED_BFQ=y
必要なパッケージのインストール
今回の計測するにあたって、Raspberry Pi OS にプリインストールされているパッケージのみでは不足している。
そこで、計測用にdebianパッケージを追加でインストールする。
pi@raspberrypi:~$ sudo apt install bpfcc-tools
BPFスクリプトの修正
debian (bullseye) が提供する bpfcc-toolsパッケージは、upstreamより古いバージョンとなっている。
今回使用しているバージョンには、BYTESの値で不適切となる不具合があったため、次のコミットをcherry-pickした。
また、今回の計測では短時間に多くのBIO情報が出力されるため、リングバッファ (page_cnt) のサイズも拡張しておく。
実験結果
スループット
I/Oスケジューラの違いによるパフォーマンスを比較する。
パフォーマンス測定には fio の実行結果からbwを抽出した。
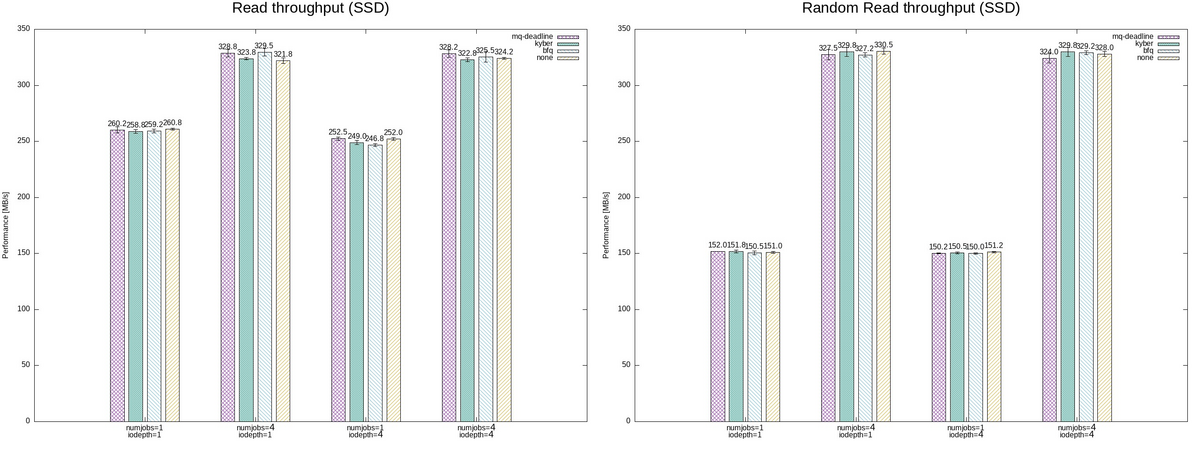
高速なSSDの場合には、numjobsに比例してパフォーマンスが向上しているように見える。
一方で、それぞれの I/Oスケジューラ で結果に大きな差がないように見える。
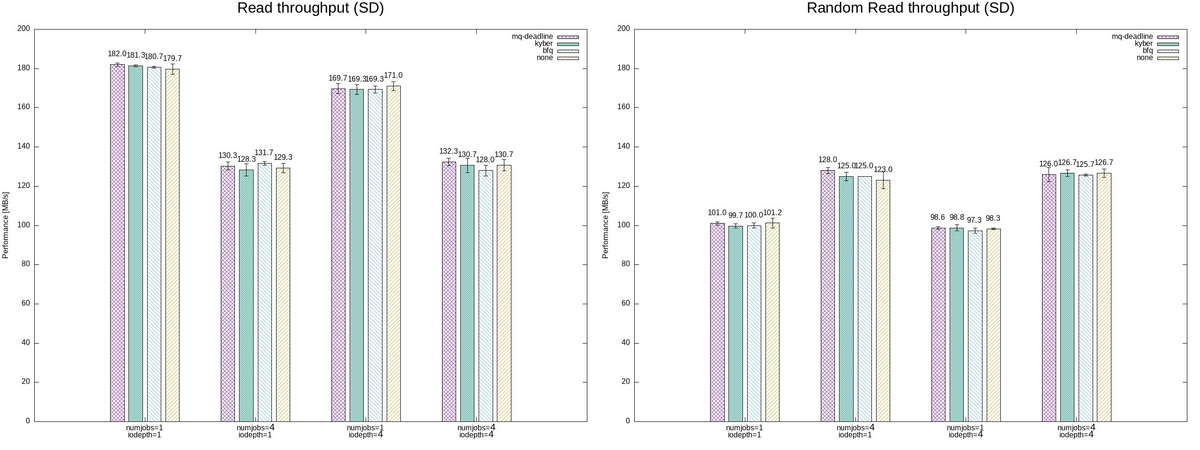
SDカードの場合には、シーケンシャルな読み込みの場合には、numjobsに比例してパフォーマンスが低下しているように見える。
一方で、ランダムな読み込みの場合には、numjobs=1 のパフォーマンスが大きく低下しているように見える。 また、
それぞれの I/Oスケジューラ で結果に大きな差がないように見える。
レイテンシ
I/Oスケジューラの違いによるレイテンシ(IO要求発行時から完了までの時間) を比較する。
ここでは、最も複雑なパターン4 (numjobs=4, iodepth=4) の結果のみ注目する。
各I/Oスケジューラにおいて、biosnoop で得られたレイテンシでヒストグラムでプロットした。 (左から I/Oスケジューラが"mq-deadlie", "kyber", "bfq", "none"の順で表示)
これらのグラフは、横軸がレイテンシで縦軸が発生頻度を表しているため、左上にプロットが集中しているほど平均レイテンシが小さいことを意味する。




外付けSSD/SDカードに対する読み込みによるレイテンシについては、それぞれの I/Oスケジューラでのレイテンシの違いに大きな差分はなかった。
CPU使用率
I/Oスケジューラの違いによるCPU使用率(すべてのコアの合算値)を比較する。
レイテンシと同様に、最も複雑なパターン4 (numjobs=4, iodepth=4) の結果のみ注目する。
各I/Oスケジューラにおいて、mpstat で得られたCPU利用状況を内訳によって積み上げグラフとしてプロットした。 (左から I/Oスケジューラが"mq-deadlie", "kyber", "bfq", "none"の順で表示)
これらのグラフは、赤色がカーネルで実行されたCPU利用の割合を表しているため、赤色の割合が大きいほどI/Oスケジューラによるオーバーヘッドが大きいことを意味する。


SSDの場合には、開始140sあたりまでの iowaitの割合が、mq-deadline のみ大きくなっているように見える。


SDカードの場合には、それぞれの I/Oスケジューラでのレイテンシの違いに大きな差分はなかった。
おわりに
本記事では、ファイルシステムの違いによるストレージへの読み込みについて以下の3点に着目して計測した。
- スループット
- BIO毎のレイテンシ
- CPU使用率
今回はI/Oスケジューラのパラメータをチューニングしていないため、参考値ではあるが I/Oスケジューラによる大きな違いは見られなかった。
また、この実験は利用的な環境 (ユーザからこのプロセスしか動かしておらず、負荷が大きいプロセスもこのプロセスのみである) であるため、実際には結果が大きく異なることが予想される。
そのため、それぞれのユースケースに沿って環境を選定することが必要となってくる。
変更履歴
- 2023/11/19: 記事公開
参考
- IOスケジューラごとにスループットを計測
- 2023年における I/O スケジューラのまとめ
- I/Oスケジューラの概要
Linuxカーネルのファイルアクセスの処理を追いかける (18) block: blk_mq_do_dispatch_sched
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、I/Oスケジューラからリクエストをディスパッチしてから、ブロックデバイスドライバにリクエストを発行する (queue_rq )までを確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
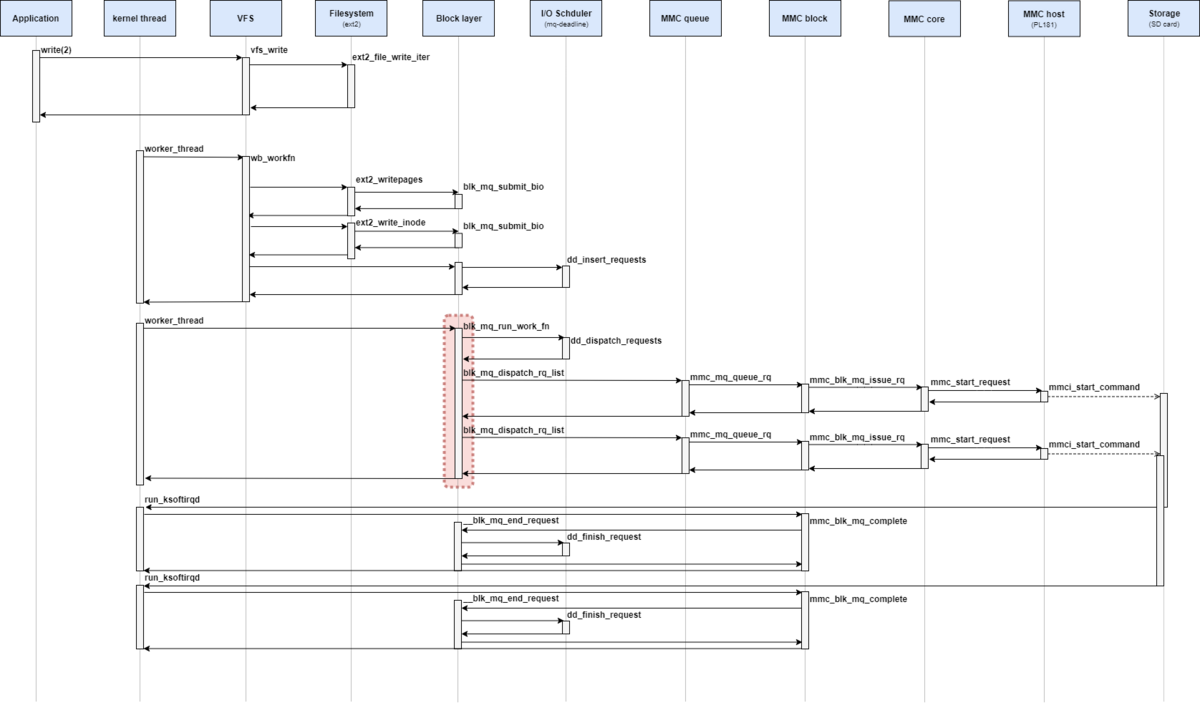
I/Oスケジューラからリクエストをディスパッチする
blk_mq_do_dispatch_sched関数は、I/Oスケジューラからリクエストをディスパッチするための関数である。
I/Oスケジューラが設定されている場合に、__blk_mq_sched_dispatch_requests関数から呼び出される。
Hardware Dispatch Queue を引数として受け取り、リクエストがディスパッチ完了したときに true を返す。
blk_mq_do_dispatch_sched関数の定義は次の通りとなっている。
// 209: static int blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx) { int ret; do { ret = __blk_mq_do_dispatch_sched(hctx); } while (ret == 1); return ret; }
blk_mq_do_dispatch_sched関数は、__blk_mq_do_dispatch_sched関数を呼び出すためのラッパ関数となっている。
__blk_mq_do_dispatch_sched関数では、さらにディスパッチが必要な場合に 1を返し(ディスパッチがまだ必要な場合には、 whileループで繰り返す)、そうではない場合に 0または -EAGAINを返す 。
__blk_mq_do_dispatch_sched関数の定義は次の通りとなっている。
// 118: static int __blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx) { struct request_queue *q = hctx->queue; struct elevator_queue *e = q->elevator; bool multi_hctxs = false, run_queue = false; bool dispatched = false, busy = false; unsigned int max_dispatch; LIST_HEAD(rq_list); int count = 0; if (hctx->dispatch_busy) max_dispatch = 1; else max_dispatch = hctx->queue->nr_requests; do { struct request *rq; int budget_token; if (e->type->ops.has_work && !e->type->ops.has_work(hctx)) break; if (!list_empty_careful(&hctx->dispatch)) { busy = true; break; } budget_token = blk_mq_get_dispatch_budget(q); if (budget_token < 0) break; rq = e->type->ops.dispatch_request(hctx); if (!rq) { blk_mq_put_dispatch_budget(q, budget_token); /* * We're releasing without dispatching. Holding the * budget could have blocked any "hctx"s with the * same queue and if we didn't dispatch then there's * no guarantee anyone will kick the queue. Kick it * ourselves. */ run_queue = true; break; } blk_mq_set_rq_budget_token(rq, budget_token); /* * Now this rq owns the budget which has to be released * if this rq won't be queued to driver via .queue_rq() * in blk_mq_dispatch_rq_list(). */ list_add_tail(&rq->queuelist, &rq_list); count++; if (rq->mq_hctx != hctx) multi_hctxs = true; /* * If we cannot get tag for the request, stop dequeueing * requests from the IO scheduler. We are unlikely to be able * to submit them anyway and it creates false impression for * scheduling heuristics that the device can take more IO. */ if (!blk_mq_get_driver_tag(rq)) break; } while (count < max_dispatch); if (!count) { if (run_queue) blk_mq_delay_run_hw_queues(q, BLK_MQ_BUDGET_DELAY); } else if (multi_hctxs) { /* * Requests from different hctx may be dequeued from some * schedulers, such as bfq and deadline. * * Sort the requests in the list according to their hctx, * dispatch batching requests from same hctx at a time. */ list_sort(NULL, &rq_list, sched_rq_cmp); do { dispatched |= blk_mq_dispatch_hctx_list(&rq_list); } while (!list_empty(&rq_list)); } else { dispatched = blk_mq_dispatch_rq_list(hctx, &rq_list, count); } if (busy) return -EAGAIN; return !!dispatched; }
__blk_mq_do_dispatch_sched関数では、二つの処理に分けることができる。
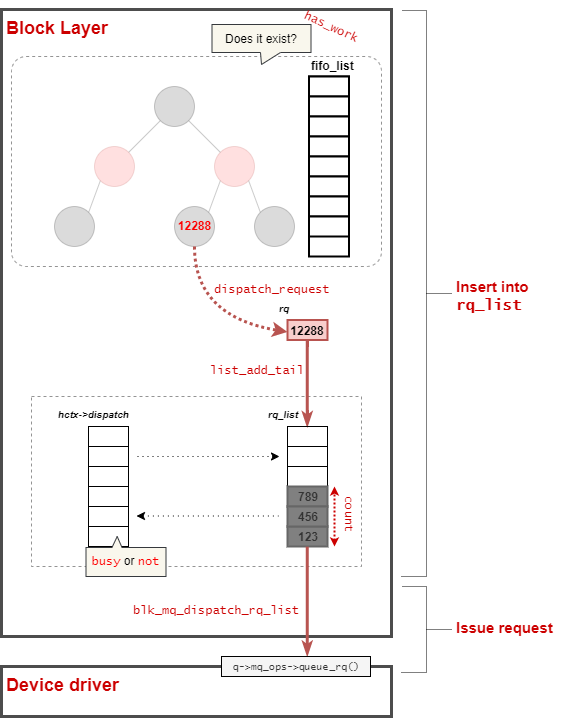
ディスパッチ候補のリクエストをキューに追加する
__blk_mq_do_dispatch_sched関数から該当部分を抜粋する。
// 133: do { struct request *rq; int budget_token; if (e->type->ops.has_work && !e->type->ops.has_work(hctx)) break; if (!list_empty_careful(&hctx->dispatch)) { busy = true; break; } budget_token = blk_mq_get_dispatch_budget(q); if (budget_token < 0) break; rq = e->type->ops.dispatch_request(hctx); if (!rq) { blk_mq_put_dispatch_budget(q, budget_token); /* * We're releasing without dispatching. Holding the * budget could have blocked any "hctx"s with the * same queue and if we didn't dispatch then there's * no guarantee anyone will kick the queue. Kick it * ourselves. */ run_queue = true; break; } blk_mq_set_rq_budget_token(rq, budget_token); /* * Now this rq owns the budget which has to be released * if this rq won't be queued to driver via .queue_rq() * in blk_mq_dispatch_rq_list(). */ list_add_tail(&rq->queuelist, &rq_list); count++; if (rq->mq_hctx != hctx) multi_hctxs = true; /* * If we cannot get tag for the request, stop dequeueing * requests from the IO scheduler. We are unlikely to be able * to submit them anyway and it creates false impression for * scheduling heuristics that the device can take more IO. */ if (!blk_mq_get_driver_tag(rq)) break; } while (count < max_dispatch);
ここでは、特定回数max_dispatchだけ次のような処理を実施する。
- I/Oスケジューラに対して、リクエストが存在しているか確認する
- dispatch候補リストにリクエストが存在していれば、そちらを優先する
- I/Oスケジューラに対して、ディスパッチするリクエストを取得する
- リクエストを
rq_listに追加する
max_dispatchは、基本的には キューの深さになるが、 dispatch_busy状態の場合には 1 となる。
dispatch_busyは、blk_mq_update_dispatch_busy関数によって更新される。
// 1210: static void blk_mq_update_dispatch_busy(struct blk_mq_hw_ctx *hctx, bool busy) { unsigned int ewma; ewma = hctx->dispatch_busy; if (!ewma && !busy) return; ewma *= BLK_MQ_DISPATCH_BUSY_EWMA_WEIGHT - 1; if (busy) ewma += 1 << BLK_MQ_DISPATCH_BUSY_EWMA_FACTOR; ewma /= BLK_MQ_DISPATCH_BUSY_EWMA_WEIGHT; hctx->dispatch_busy = ewma; }
blk_mq_update_dispatch_busy関数は、blk_mq_dispatch_rq_list関数(この後に呼ばれる)と__blk_mq_issue_directly関数から呼び出される。
いずれの場合もデバイスドライバにリクエストを発行し、何かしらの理由(再実行が必要など)で拒否された場合に busy状態となり、処理が完了した場合にbusy状態が解除する。
ただし、dispatchキューにリクエストがすでに入っている場合に、I/Oスケジューラからのリクエスト抽出を中止する。
また、ブロックデバイスがSCSIを介している場合には、budgetを確認する必要がある。
リクエストキュー毎にの深さが存在しているため、I/Oスケジューラからリクエストをディスパッチする前後でget_budgetとset_budgetを呼ぶ必要がある。
ただし、mmcドライバでは上記に対応していないため、詳細は割愛する。
その後、dispatch_requestで選択したリクエストrqをrq_listに追加していく。
キューにあるリクエストをブロックレイヤーに発行する
I/Oスケジューラからディスパッチされたリクエストをrq_listに追加した後、条件によってこれらのリクエストの取り扱いが異なる。
// 185: if (!count) { if (run_queue) blk_mq_delay_run_hw_queues(q, BLK_MQ_BUDGET_DELAY); } else if (multi_hctxs) { /* * Requests from different hctx may be dequeued from some * schedulers, such as bfq and deadline. * * Sort the requests in the list according to their hctx, * dispatch batching requests from same hctx at a time. */ list_sort(NULL, &rq_list, sched_rq_cmp); do { dispatched |= blk_mq_dispatch_hctx_list(&rq_list); } while (!list_empty(&rq_list)); } else { dispatched = blk_mq_dispatch_rq_list(hctx, &rq_list, count); } if (busy) return -EAGAIN; return !!dispatched; }
I/Oスケジューラからリクエストをディスパッチできなかった場合、Dispatch用のWorkをWork Queueに追加 (BLK_MQ_BUDGET_DELAY (3ms) 後に遅延実行) される。
複数のHardware Dispatch Queueを持つ場合には同じQueueで処理する必要がある。
その場合、該当のQueueに対応するリクエストを rq_listから取り出し、blk_mq_dispatch_rq_listを呼び出す。
デバイスドライバにリクエストを発行する
blk_mq_dispatch_rq_list関数は、ブロックデバイスにリクエストを発行する関数である。
I/Oスケジューラが設定されている場合に、__blk_mq_sched_dispatch_requests関数から呼び出される。
Hardware Dispatch Queue (hctx) と 発行するリクエストのリスト(list)、budget完了数(nr_budgets) を引数として受け取り、リクエストがディスパッチ完了したときに true を返す。
blk_mq_dispatch_rq_list関数の定義は次の通りとなっている。
// 1319: bool blk_mq_dispatch_rq_list(struct blk_mq_hw_ctx *hctx, struct list_head *list, unsigned int nr_budgets) { enum prep_dispatch prep; struct request_queue *q = hctx->queue; struct request *rq, *nxt; int errors, queued; blk_status_t ret = BLK_STS_OK; LIST_HEAD(zone_list); bool needs_resource = false; if (list_empty(list)) return false; /* * Now process all the entries, sending them to the driver. */ errors = queued = 0; do { struct blk_mq_queue_data bd; rq = list_first_entry(list, struct request, queuelist); WARN_ON_ONCE(hctx != rq->mq_hctx); prep = blk_mq_prep_dispatch_rq(rq, !nr_budgets); if (prep != PREP_DISPATCH_OK) break; list_del_init(&rq->queuelist); bd.rq = rq; /* * Flag last if we have no more requests, or if we have more * but can't assign a driver tag to it. */ if (list_empty(list)) bd.last = true; else { nxt = list_first_entry(list, struct request, queuelist); bd.last = !blk_mq_get_driver_tag(nxt); } /* * once the request is queued to lld, no need to cover the * budget any more */ if (nr_budgets) nr_budgets--; ret = q->mq_ops->queue_rq(hctx, &bd); switch (ret) { case BLK_STS_OK: queued++; break; case BLK_STS_RESOURCE: needs_resource = true; fallthrough; case BLK_STS_DEV_RESOURCE: blk_mq_handle_dev_resource(rq, list); goto out; case BLK_STS_ZONE_RESOURCE: /* * Move the request to zone_list and keep going through * the dispatch list to find more requests the drive can * accept. */ blk_mq_handle_zone_resource(rq, &zone_list); needs_resource = true; break; default: errors++; blk_mq_end_request(rq, ret); } } while (!list_empty(list)); out: if (!list_empty(&zone_list)) list_splice_tail_init(&zone_list, list); hctx->dispatched[queued_to_index(queued)]++; /* If we didn't flush the entire list, we could have told the driver * there was more coming, but that turned out to be a lie. */ if ((!list_empty(list) || errors) && q->mq_ops->commit_rqs && queued) q->mq_ops->commit_rqs(hctx); /* * Any items that need requeuing? Stuff them into hctx->dispatch, * that is where we will continue on next queue run. */ if (!list_empty(list)) { bool needs_restart; /* For non-shared tags, the RESTART check will suffice */ bool no_tag = prep == PREP_DISPATCH_NO_TAG && (hctx->flags & BLK_MQ_F_TAG_QUEUE_SHARED); if (nr_budgets) blk_mq_release_budgets(q, list); spin_lock(&hctx->lock); list_splice_tail_init(list, &hctx->dispatch); spin_unlock(&hctx->lock); /* * Order adding requests to hctx->dispatch and checking * SCHED_RESTART flag. The pair of this smp_mb() is the one * in blk_mq_sched_restart(). Avoid restart code path to * miss the new added requests to hctx->dispatch, meantime * SCHED_RESTART is observed here. */ smp_mb(); /* * If SCHED_RESTART was set by the caller of this function and * it is no longer set that means that it was cleared by another * thread and hence that a queue rerun is needed. * * If 'no_tag' is set, that means that we failed getting * a driver tag with an I/O scheduler attached. If our dispatch * waitqueue is no longer active, ensure that we run the queue * AFTER adding our entries back to the list. * * If no I/O scheduler has been configured it is possible that * the hardware queue got stopped and restarted before requests * were pushed back onto the dispatch list. Rerun the queue to * avoid starvation. Notes: * - blk_mq_run_hw_queue() checks whether or not a queue has * been stopped before rerunning a queue. * - Some but not all block drivers stop a queue before * returning BLK_STS_RESOURCE. Two exceptions are scsi-mq * and dm-rq. * * If driver returns BLK_STS_RESOURCE and SCHED_RESTART * bit is set, run queue after a delay to avoid IO stalls * that could otherwise occur if the queue is idle. We'll do * similar if we couldn't get budget or couldn't lock a zone * and SCHED_RESTART is set. */ needs_restart = blk_mq_sched_needs_restart(hctx); if (prep == PREP_DISPATCH_NO_BUDGET) needs_resource = true; if (!needs_restart || (no_tag && list_empty_careful(&hctx->dispatch_wait.entry))) blk_mq_run_hw_queue(hctx, true); else if (needs_restart && needs_resource) blk_mq_delay_run_hw_queue(hctx, BLK_MQ_RESOURCE_DELAY); blk_mq_update_dispatch_busy(hctx, true); return false; } else blk_mq_update_dispatch_busy(hctx, false); return (queued + errors) != 0; }
blk_mq_dispatch_rq_list関数を次の三つの処理に分割して確認する。
リクエスト発行の前処理
// 1330: if (list_empty(list)) return false; /* * Now process all the entries, sending them to the driver. */ errors = queued = 0; do { struct blk_mq_queue_data bd; rq = list_first_entry(list, struct request, queuelist); WARN_ON_ONCE(hctx != rq->mq_hctx); prep = blk_mq_prep_dispatch_rq(rq, !nr_budgets); if (prep != PREP_DISPATCH_OK) break; list_del_init(&rq->queuelist); bd.rq = rq; /* * Flag last if we have no more requests, or if we have more * but can't assign a driver tag to it. */ if (list_empty(list)) bd.last = true; else { nxt = list_first_entry(list, struct request, queuelist); bd.last = !blk_mq_get_driver_tag(nxt); } /* * once the request is queued to lld, no need to cover the * budget any more */ if (nr_budgets) nr_budgets--;
ブロックデバイスにリクエストを発行する前処理として、次のようなセットアップを実施する。
発行するリクエストのリスト(list) からリクエストを取り出していき、blk_mq_prep_dispatch_rq関数によって検証していく。
blk_mq_prep_dispatch_rq関数の定義は次の通りとなっている。
// 1265: static enum prep_dispatch blk_mq_prep_dispatch_rq(struct request *rq, bool need_budget) { struct blk_mq_hw_ctx *hctx = rq->mq_hctx; int budget_token = -1; if (need_budget) { budget_token = blk_mq_get_dispatch_budget(rq->q); if (budget_token < 0) { blk_mq_put_driver_tag(rq); return PREP_DISPATCH_NO_BUDGET; } blk_mq_set_rq_budget_token(rq, budget_token); } if (!blk_mq_get_driver_tag(rq)) { /* * The initial allocation attempt failed, so we need to * rerun the hardware queue when a tag is freed. The * waitqueue takes care of that. If the queue is run * before we add this entry back on the dispatch list, * we'll re-run it below. */ if (!blk_mq_mark_tag_wait(hctx, rq)) { /* * All budgets not got from this function will be put * together during handling partial dispatch */ if (need_budget) blk_mq_put_dispatch_budget(rq->q, budget_token); return PREP_DISPATCH_NO_TAG; } } return PREP_DISPATCH_OK; }
blk_mq_prep_dispatch_rq関数は、「(必要であれば) debgetの取得」と「tagの割り当て」を実施する。
budgetの取得について、blk_mq_do_dispatch_sched関数経由から呼び出す場合には、blk_mq_set_rq_budget_token関数を実行しているため不要である。
ただし、特定のフローでは blk_mq_set_rq_budget_token関数が呼ばれていないため、blk_mq_prep_dispatch_rq関数で呼び出す。
ここで、budgetの確保に失敗した場合には PREP_DISPATCH_NO_BUDGETとして、以降のリクエストのdispatch処理を終了させる。
その後、blk_mq_get_driver_tag関数で tag の割り当てを実施する。
blk_mq_get_driver_tag関数では、tag の割り当てできた (すでにできている) 場合に trueを返す。
blk_mq_get_driver_tag関数の定義は次の通りとなっている。
// 1094: bool blk_mq_get_driver_tag(struct request *rq) { struct blk_mq_hw_ctx *hctx = rq->mq_hctx; if (rq->tag == BLK_MQ_NO_TAG && !__blk_mq_get_driver_tag(rq)) return false; if ((hctx->flags & BLK_MQ_F_TAG_QUEUE_SHARED) && !(rq->rq_flags & RQF_MQ_INFLIGHT)) { rq->rq_flags |= RQF_MQ_INFLIGHT; __blk_mq_inc_active_requests(hctx); } hctx->tags->rqs[rq->tag] = rq; return true; }
tag の割り当てができたリクエストは blk_mq_queue_data型でデータをラッピングして、ブロックデバイスへのリクエストに取り掛かる。
blk_mq_queue_data型は末尾かどうかを表すフラグ last を持ったリスト型となっている。
リクエスト発行の本処理
// 1368: ret = q->mq_ops->queue_rq(hctx, &bd); switch (ret) { case BLK_STS_OK: queued++; break; case BLK_STS_RESOURCE: needs_resource = true; fallthrough; case BLK_STS_DEV_RESOURCE: blk_mq_handle_dev_resource(rq, list); goto out; case BLK_STS_ZONE_RESOURCE: /* * Move the request to zone_list and keep going through * the dispatch list to find more requests the drive can * accept. */ blk_mq_handle_zone_resource(rq, &zone_list); needs_resource = true; break; default: errors++; blk_mq_end_request(rq, ret); } } while (!list_empty(list));
ブロックデバイスは専用のインターフェースが用意されており、そこで固有の操作を登録する。
ブロックデバイスへのリクエストは queue_rqによってリクエストを発行することができる。
デバイスの状態に応じて、リクエストの発行から帰ってくるステータスは大きく分けて3種類ある。
BLK_STS_OK: リクエストは正常に発行でき、デバイスドライバのキューにリクエストを追加されたBLK_STS*_RESOURCE: リソースがビジー状態となっており、デバイスドライバのキューにリクエストを追加できなかった- その他
リソースがビジー状態となっていた場合には、現在のリクエストをhctx->dispatchに追加し、 needs_resourceフラグにより 3ms後に再実行することになる。
リクエスト発行の後処理
// 1393: out: if (!list_empty(&zone_list)) list_splice_tail_init(&zone_list, list); hctx->dispatched[queued_to_index(queued)]++; /* If we didn't flush the entire list, we could have told the driver * there was more coming, but that turned out to be a lie. */ if ((!list_empty(list) || errors) && q->mq_ops->commit_rqs && queued) q->mq_ops->commit_rqs(hctx); /* * Any items that need requeuing? Stuff them into hctx->dispatch, * that is where we will continue on next queue run. */ if (!list_empty(list)) { bool needs_restart; /* For non-shared tags, the RESTART check will suffice */ bool no_tag = prep == PREP_DISPATCH_NO_TAG && (hctx->flags & BLK_MQ_F_TAG_QUEUE_SHARED); if (nr_budgets) blk_mq_release_budgets(q, list); spin_lock(&hctx->lock); list_splice_tail_init(list, &hctx->dispatch); spin_unlock(&hctx->lock); /* * Order adding requests to hctx->dispatch and checking * SCHED_RESTART flag. The pair of this smp_mb() is the one * in blk_mq_sched_restart(). Avoid restart code path to * miss the new added requests to hctx->dispatch, meantime * SCHED_RESTART is observed here. */ smp_mb(); /* * If SCHED_RESTART was set by the caller of this function and * it is no longer set that means that it was cleared by another * thread and hence that a queue rerun is needed. * * If 'no_tag' is set, that means that we failed getting * a driver tag with an I/O scheduler attached. If our dispatch * waitqueue is no longer active, ensure that we run the queue * AFTER adding our entries back to the list. * * If no I/O scheduler has been configured it is possible that * the hardware queue got stopped and restarted before requests * were pushed back onto the dispatch list. Rerun the queue to * avoid starvation. Notes: * - blk_mq_run_hw_queue() checks whether or not a queue has * been stopped before rerunning a queue. * - Some but not all block drivers stop a queue before * returning BLK_STS_RESOURCE. Two exceptions are scsi-mq * and dm-rq. * * If driver returns BLK_STS_RESOURCE and SCHED_RESTART * bit is set, run queue after a delay to avoid IO stalls * that could otherwise occur if the queue is idle. We'll do * similar if we couldn't get budget or couldn't lock a zone * and SCHED_RESTART is set. */ needs_restart = blk_mq_sched_needs_restart(hctx); if (prep == PREP_DISPATCH_NO_BUDGET) needs_resource = true; if (!needs_restart || (no_tag && list_empty_careful(&hctx->dispatch_wait.entry))) blk_mq_run_hw_queue(hctx, true); else if (needs_restart && needs_resource) blk_mq_delay_run_hw_queue(hctx, BLK_MQ_RESOURCE_DELAY); blk_mq_update_dispatch_busy(hctx, true); return false; } else blk_mq_update_dispatch_busy(hctx, false); return (queued + errors) != 0;
dispatchされたリクエストの個数は debugfsインターフェースで確認することができる。
リクエスト発行の後処理では、まず初めにこれを更新する。
# cat /sys/kernel/debug/block/mmcblk0/hctx0/dispatched
0 0
1 8
2 1
4 0
8 0
16 0
32+ 0
SCSI や NMVe といったデバイスドライバで、リクエストの最後尾を判断する必要がある。
そのようなデバイスに対して、 commit_rqsを呼び出すことでリクエストの末尾を通知する。(ただし、今回の環境でもあるSDカードに対して不要)
その後、デバイスドライバのキューにリクエストの追加に失敗した場合などに、dispatch処理の再実行を試みる。
ただし、Hardware dispatch Queueのステータス管理が複雑となっているため、気を付けるポイントが存在する。
blk-mqでは、ディスパッチの再実行が必要な場合のフラグとして BLK_MQ_S_SCHED_RESTARTが存在する。
このフラグは、PREFLUSH/FUAリクエストの完了時 (blk_mq_sched_restart関数)にフラグがセットされている場合にクリアされる。
これらは別のプロセッサで動作する可能性があるため、メモリバリアが必要になる。
memory barriers have to be used for ordering the following two pair of OPs:
1) adding requests to hctx->dispatch and checking SCHED_RESTART inblk_mq_dispatch_rq_list()
2) clearing SCHED_RESTART and checking if there is request in hctx->dispatch in blk_mq_sched_restart().Without the added memory barrier, either:
1) blk_mq_sched_restart() may miss requests added to hctx->dispatch meantime blk_mq_dispatch_rq_list() observes SCHED_RESTART, and not run queue in dispatch side
or
2) blk_mq_dispatch_rq_list still sees SCHED_RESTART, and not run queue in dispatch side, meantime checking if there is request in hctx->dispatch from blk_mq_sched_restart() is missed.
この場合、Hardware Dispatch Queueをdispatch_busy状態として、いくつかの処理に制限がかかった状態となる。
おわりに
本記事では、リクエストをディスパッチがカーネルスレッドとして起動するところから、I/Oスケジューラからディスパッチする処理の直前となっている次の関数について確認した。
blk_mq_do_dispatch_sched__blk_mq_do_dispatch_schedblk_mq_dispatch_rq_listblk_mq_prep_dispatch_rq
変更履歴
- 2023/11/13: 記事公開
参考
- Block layer introduction part 2: the request layer [LWN.net]
- ブロックレイヤーにおけるリクエストの取り扱い
- blk-mq: introduce BLK_STS_DEV_RESOURCE - Patchwork
- BLK_STS_DEV_RESOURCE 導入パッチ
- [05/11] block: introduce BLK_STS_ZONE_RESOURCE - Patchwork
- BLK_STS_ZONE_RESOURCE 導入パッチ
I/O スケジューラの違いによるストレージの書き込み性能を比較する
注意
本記事は、特定の環境下における特定の書き込みパターンを測定した結果であり、 I/O スケジューラの優劣を決めるものではない。
関連記事
概要
本記事では、I/Oスケジューラの違いによって、次のようなストレージへの書き込み特性について確認した。
- スループット
- BIO毎のレイテンシ
- CPU使用率
今回の環境(Raspberry Pi 4 と SSD/SDカード) と測定方法では、それぞれのI/Oスケジューラ (パラメータはデフォルト値) による大きな違いは見られなかった。
はじめに
汎用的なストレージデバイスは、その特性からまとまったデータ量のI/Oであるほうが効率が良いとされている。
しかし実際には、アプリケーションがそういったI/Oが発行されるとは限らない。
Linuxカーネルには、I/Oスケジューラと呼ばれるI/Oリクエストの処理順番を入れ替えたり、まとめたりすることで応答速度やスループットを向上を目的とした機能である。
I/Oスケジューラにはそれぞれ異なる特性があり、システム環境やストレージデバイスなどによって、I/O性能が変わってくる。
ここでは、OSの機能の一機能 "I/Oスケジューラ"に注目して、それぞれの書き込みの違いを確認する。
Linux Kernel v5.15 では、mq-deadline、bfq (Budget Fair Queuing)、kyber がサポートしている。
mq-deadline の概要
mq-deadlineは、デッドラインを設けることでリクエストの処理開始時間を保障する I/Oスケジューラの一つである。
Linux Kernel v5.15 のデフォルト値では、書き込みリクエストの有効期限は 5秒 、読み込みリクエストの有効期限は 500 ミリ秒 となる。
bfq の概要
bfq は、単一のアプリケーションがすべての帯域幅を使用しないようスケジュールする I/Oスケジューラの一つである。
Linux Kernel 5.15 のデフォルト値では、スループットの最大化よりもレイテンシの最小化を達成することを目的とする。
そのため、低速のCPUに対して高速なストレージデバイスに対しては、bfq I/Oスケジューラは不向きとなることがある。
kyber の概要
mq-deadlineは、ブロックレイヤに渡されたI/O要求のレイテンシを計算し、目標とするレイテンシを達成するような I/Oスケジューラの一つである。
Linux Kernel v5.15 のデフォルト値では、目標とする読み込みレイテンシは 2ミリ秒 、同期書き込みのレイテンシは 10 ミリ秒 となる。
目的
I/Oスケジューラの違いによって、次のような書き込み特性がどのように変化するかを調査する。
- スループットの計測
- BIO毎のレイテンシ計測
- CPU使用率の計測
実行環境
Raspberry Pi 4 Model B (Raspberry Pi 4) は microSDカード経由でRaspberry Pi OSを起動させる。 また、Raspbery Pi 4 の USB3.0ポートにポータブルSSDを接続する。
ここで使用する実験環境について下記に示す。
| 項目 | 概要 |
|---|---|
| Board | Raspberry Pi 4 |
| CPU | Cortex-A72 (ARM v8) 1.5GHz |
| メモリ | 4GB LPDDR4-3200 |
| OS | Raspberry Pi OS (64 bit) (Feb 21st 2023) |
| kernel | v5.15.92 |
| ファイルシステム | ext4 |
| BCC Utilities | bpfcc-tools version 0.18.0+ds-2 |
| ext4 Utilities | E2fsprogs version 1.46.2 |
| fio | fio-3.25-2 |
| OS格納先ストレージ | microSDHC 16GB Class10 UHS-1 |
| 計測用ストレージ(外付けSSD) | SL-MG5 |
| 計測用ストレージ(SDカード) | SF-E64 |
この実験では、 外付け SSD/SDカードに対する書き込みを計測する。
計測方法
ストレージへの書き込みをする負荷プログラムとして fio を実行し、次のような情報を取得することでI/Oスケジューラの比較する。
- スループットの計測
- BIO毎のレイテンシ計測
- CPU使用率の計測
毎計測時、デフォルトパラメータでmkfsコマンドの実行と、 echo 3 > /proc/sys/vm/drop_cachesによるキャッシュ解放を実施する。
biosnoopとmpstatによる計測は、ファイルシステムをマウント(mount)してからアンマウント(umount)までとする。
その区間に負荷プログラム(fio)を実行し、そのときのIO要求のデータを使用する。
計測の流れを図にすると下記のようになる。
ここで、白色の丸は "非同期処理"であり、黒色の丸は "同期処理" を表している。
また、各実験は3回ずつ施行する。
スループットの計測
fioでは、合計 32GB となるような 次の4パターンを2つのアクセス手法 (sequential/random) のジョブとして実行する。
| write パターン1 |
write パターン2 |
write パターン3 |
write パターン4 |
|
|---|---|---|---|---|
| bs | 1M | 1M | 1M | 1M |
| size | 32G | 8G | 8G | 8G |
| numjobs | 1 | 4 | 1 | 4 |
| iodepth | 1 | 1 | 4 | 4 |
この実験では、異なる計測用ストレージとI/Oスケジューラに対して、これらを実行する。
BIO毎のレイテンシ計測
BPF Compiler Collection (BCC) を利用することで、ユーザプログラムから IO要求発行に任意の処理を追加し、IO要求の内容を確認する。
今回の計測では、BCCのサンプルスクリプトとして提供されている biosnoop を利用する。
biosnoop は、IO要求発行(blk_mq_start_request)と IO完了(blk_account_io_done) における BIO のステータスを確認することができる。
このスクリプトを実行することで下記のような結果を得ることができる。
TIME(s) COMM PID DISK T SECTOR BYTES QUE(ms) LAT(ms)
0.000000 mount 4349 sda R 2050 1024 0.06 0.46
0.000396 mount 4349 sda R 2048 4096 0.05 0.19
0.000713 mount 4349 sda R 2056 4096 0.05 0.18
0.000826 mount 4349 sda R 2064 4096 0.05 0.18
0.000968 mount 4349 sda R 2072 4096 0.05 0.16
0.001165 mount 4349 sda R 2080 4096 0.09 0.17
ここから書き込み先デバイス (DISK) と アクセス方向 (T) でフィルターをかける。
ここから、タイムスタンプ (TIME), オフセット (SECTOR)とサイズ (SIZE)を抽出する。
CPU使用率の計測
mpstatを利用することで、次のようなプロセッサ関連の統計情報を表示することができる。
Linux 5.15.92-v8 (raspberrypi) 09/09/2023 _aarch64_ (4 CPU)
10:59:25 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
10:59:26 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:59:27 PM all 0.00 0.00 0.25 0.00 0.00 0.00 0.00 0.00 0.00 99.75
10:59:28 PM all 0.25 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 99.75
10:59:29 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
10:59:30 PM all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
今回は、CPU使用率を確認するために mpstat をバックグラウンドで実行する。
準備
Linuxカーネルの再構築
BCCは、特定のカーネルコンフィグに依存しているが、Raspberry pi OS のデフォルトで無効となっている。
そこで、公式手順に基に、独自にカーネルのビルド・インストールを実施する。
カーネルコンフィグは、デフォルトのカーネルコンフィグから次のように修正する。
user@hostname:~/linux$ ./scripts/diffconfig .config.old .config
IKHEADERS n -> y
また、Kyber と BFQ はデフォルトで無効となっているため、カーネルコンフィグを更新しておく。
user@hostname:~/linux$ ./scripts/diffconfig .config.old .config
MQ_IOSCHED_KYBER=y
IOSCHED_BFQ=y
必要なパッケージのインストール
今回の計測するにあたって、Raspberry Pi OS にプリインストールされているパッケージのみでは不足している。
そこで、計測用にdebianパッケージを追加でインストールする。
pi@raspberrypi:~$ sudo apt install bpfcc-tools
BPFスクリプトの修正
debian (bullseye) が提供する bpfcc-toolsパッケージは、upstreamより古いバージョンとなっている。
今回使用しているバージョンには、BYTESの値で不適切となる不具合があったため、次のコミットをcherry-pickした。
また、今回の計測では短時間に多くのBIO情報が出力されるため、リングバッファ (page_cnt) のサイズも拡張しておく。
実験結果
スループット
I/Oスケジューラの違いによるパフォーマンスを比較する。
パフォーマンス測定には fio の実行結果からbwを抽出した。
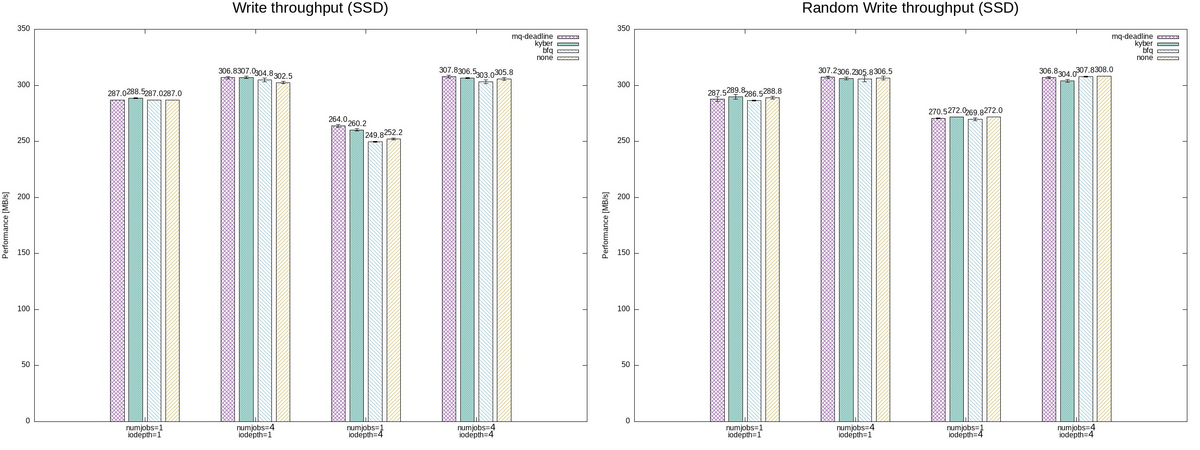
(Raspberry Pi 4と比較して) 高速なSSDの場合には、bfq I/Oスケジューラが他と比較してスループットが低めとなっているように見える。
特に、numjobs=1, iodepth=4 のシーケンシャルな書き込みでは、mq-deadline I/Oスケジューラと比較しても 5%程の低下がみられた。
これは、bfq I/Oスケジューラのデフォルト値における特性では、"低速のCPUに対して高速なストレージデバイスに対しては、bfq I/Oスケジューラは不向きとなることがある" ことが関係しているのかもしれない。
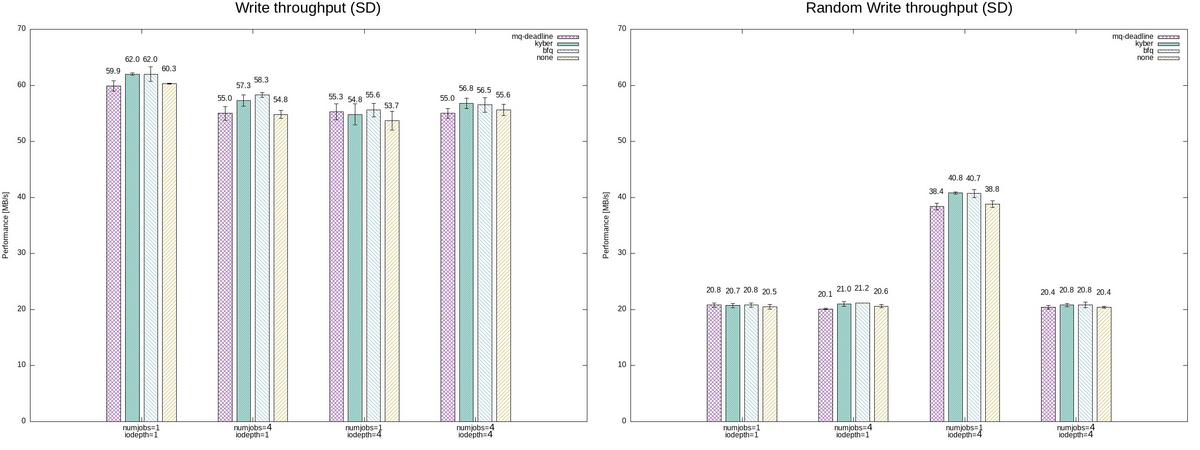
一方で、SDカードの場合には、mq-deadline I/Oスケジューラが他と比較してスループットが低めとなっているように見える。
mq-deadline I/Oスケジューラのスループットが none と同様であることを考えると、mq-deadlineによるスケジューリングが有効に動作していないと見える。
そのため、書き込みの有効期限などスケジューラのパラメータをチューニングすることで、パフォーマンスは変わるかもしれない。
レイテンシ
I/Oスケジューラの違いによるレイテンシ(IO要求発行時から完了までの時間) を比較する。
ここでは、最も複雑なパターン4 (numjobs=4, iodepth=4) の結果のみ注目する。
各I/Oスケジューラにおいて、biosnoop で得られたレイテンシでヒストグラムでプロットした。 (左から I/Oスケジューラが"mq-deadlie", "kyber", "bfq", "none"の順で表示)
これらのグラフは、横軸がレイテンシで縦軸が発生頻度を表しているため、左上にプロットが集中しているほど平均レイテンシが小さいことを意味する。


外付けSSDに対するシーケンシャルな書き込みによるレイテンシには、次のような傾向が見られた。
- mq-deadline と kyberの I/Oスケジューラは、bfq I/Oスケジューラと比較して、低レイテンシの頻度は少ないが、高レイテンシの頻度も少ない
- mq-deadline と kyberの I/Oスケジューラは、bfq I/Oスケジューラと比較して、高レイテンシの頻度も少ない
一方で、ランダムな書き込みによるレイテンシには、次のような傾向が見られた。
- mq-deadline I/Oスケジューラは、kyber と bfq I/Oスケジューラと比較して、結果のばらつきが小さい
- ただし、それぞれの I/Oスケジューラでのレイテンシの違いに大きな差分はない


SDカードに対する書き込みによるレイテンシについては、それぞれの I/Oスケジューラでのレイテンシの違いに大きな差分はなかった。
CPU使用率
I/Oスケジューラの違いによるCPU使用率(すべてのコアの合算値)を比較する。
レイテンシと同様に、最も複雑なパターン4 (numjobs=4, iodepth=4) の結果のみ注目する。
各I/Oスケジューラにおいて、mpstat で得られたCPU利用状況を内訳によって積み上げグラフとしてプロットした。 (左から I/Oスケジューラが"mq-deadlie", "kyber", "bfq", "none"の順で表示)
これらのグラフは、赤色がカーネルで実行されたCPU利用の割合を表しているため、赤色の割合が大きいほどI/Oスケジューラによるオーバーヘッドが大きいことを意味する。




CPU使用率の観点では、それぞれのケースにおいてI/Oスケジューラによるオーバーヘッド (赤色がグラフを占める割合) に大きな差分はなかった。
ただし、mq-deadline I/Oスケジューラでは、 カーネルで実行されたCPU利用にばらつきが大きい。
おわりに
本記事では、ファイルシステムの違いによるストレージへの書き込みについて以下の3点に着目して計測した。
- スループット
- BIO毎のレイテンシ
- CPU使用率
今回はI/Oスケジューラのパラメータをチューニングしていないため、参考値ではあるが I/Oスケジューラによる大きな違いは見られなかった。
また、この実験は利用的な環境 (ユーザからこのプロセスしか動かしておらず、負荷が大きいプロセスもこのプロセスのみである) であるため、実際には結果が大きく異なることが予想される。
そのため、それぞれのユースケースに沿って環境を選定することが必要となってくる。
変更履歴
- 2023/10/01: 記事公開
- 2023/11/19: 関連記事を追加
参考
- IOスケジューラごとにスループットを計測
- 2023年における I/O スケジューラのまとめ
- I/Oスケジューラの概要
Linuxカーネルのファイルアクセスの処理を追いかける (17) block: blk_mq_run_work_fn
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
- 概要
- はじめに
- kblockd の概要
- block用のワーカスレッドの作成
- dispatch用のworkを初期化する
- dispatch用のworkを遅延実行する
- リクエストを Hardware Queue に送信する
- おわりに
- 変更履歴
- 参考
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、リクエストをディスパッチがカーネルスレッドとして起動するところから、I/Oスケジューラからディスパッチする処理の直前 (__blk_mq_sched_dispatch_requests )までを確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。

kblockd の概要
Linux v5.15 の blk-mqでは、Hardware dispatch queues へのディスパッチを実現するためにもWork Queueと呼ばれる機構を用いている。
dispatch用のワーカスレッドはblock共通kblockdを利用する。

このWork Queueでは、専用API kblockd_schedule_work または kblockd_mod_delayed_work_on 関数を通して、タスクを追加することができる。
// 1619: int kblockd_schedule_work(struct work_struct *work) { return queue_work(kblockd_workqueue, work); } EXPORT_SYMBOL(kblockd_schedule_work); int kblockd_mod_delayed_work_on(int cpu, struct delayed_work *dwork, unsigned long delay) { return mod_delayed_work_on(cpu, kblockd_workqueue, dwork, delay); } EXPORT_SYMBOL(kblockd_mod_delayed_work_on);
kblockd_schedule_work: 引数で設定されたworkを、kblockdに追加するkblockd_mod_delayed_work_on: 引数で指定されたworkを、指定されたCPUで遅延実行する。
block用のワーカスレッドの作成
kblockd は、blk-mqの初期化時に下記の関数によって生成される。
// 1761: int __init blk_dev_init(void) { BUILD_BUG_ON(REQ_OP_LAST >= (1 << REQ_OP_BITS)); BUILD_BUG_ON(REQ_OP_BITS + REQ_FLAG_BITS > 8 * sizeof_field(struct request, cmd_flags)); BUILD_BUG_ON(REQ_OP_BITS + REQ_FLAG_BITS > 8 * sizeof_field(struct bio, bi_opf)); /* used for unplugging and affects IO latency/throughput - HIGHPRI */ kblockd_workqueue = alloc_workqueue("kblockd", WQ_MEM_RECLAIM | WQ_HIGHPRI, 0); if (!kblockd_workqueue) panic("Failed to create kblockd\n"); blk_requestq_cachep = kmem_cache_create("request_queue", sizeof(struct request_queue), 0, SLAB_PANIC, NULL); blk_debugfs_root = debugfs_create_dir("block", NULL); return 0; }
ここで、block用のWork Queue(kblockd_workqueue)はグローバル変数である。
Work Queueの作成については、過去の記事を参照。
dispatch用のworkを初期化する
Dispatch用のWorkは、Hardware dispatch queues の初期化フェーズにおいて、blk_mq_run_work_fn関数を定義する。
blk_mq_alloc_hctx関数の定義は次のようになっている。
// 2759: static struct blk_mq_hw_ctx * blk_mq_alloc_hctx(struct request_queue *q, struct blk_mq_tag_set *set, int node) { struct blk_mq_hw_ctx *hctx; gfp_t gfp = GFP_NOIO | __GFP_NOWARN | __GFP_NORETRY; hctx = kzalloc_node(blk_mq_hw_ctx_size(set), gfp, node); if (!hctx) goto fail_alloc_hctx; if (!zalloc_cpumask_var_node(&hctx->cpumask, gfp, node)) goto free_hctx; atomic_set(&hctx->nr_active, 0); if (node == NUMA_NO_NODE) node = set->numa_node; hctx->numa_node = node; INIT_DELAYED_WORK(&hctx->run_work, blk_mq_run_work_fn); spin_lock_init(&hctx->lock); INIT_LIST_HEAD(&hctx->dispatch); hctx->queue = q; hctx->flags = set->flags & ~BLK_MQ_F_TAG_QUEUE_SHARED; INIT_LIST_HEAD(&hctx->hctx_list); /* * Allocate space for all possible cpus to avoid allocation at * runtime */ hctx->ctxs = kmalloc_array_node(nr_cpu_ids, sizeof(void *), gfp, node); if (!hctx->ctxs) goto free_cpumask; if (sbitmap_init_node(&hctx->ctx_map, nr_cpu_ids, ilog2(8), gfp, node, false, false)) goto free_ctxs; hctx->nr_ctx = 0; spin_lock_init(&hctx->dispatch_wait_lock); init_waitqueue_func_entry(&hctx->dispatch_wait, blk_mq_dispatch_wake); INIT_LIST_HEAD(&hctx->dispatch_wait.entry); hctx->fq = blk_alloc_flush_queue(hctx->numa_node, set->cmd_size, gfp); if (!hctx->fq) goto free_bitmap; if (hctx->flags & BLK_MQ_F_BLOCKING) init_srcu_struct(hctx->srcu); blk_mq_hctx_kobj_init(hctx); return hctx; free_bitmap: sbitmap_free(&hctx->ctx_map); free_ctxs: kfree(hctx->ctxs); free_cpumask: free_cpumask_var(hctx->cpumask); free_hctx: kfree(hctx); fail_alloc_hctx: return NULL; }
dispatch用のworkは、INIT_DELAYED_WORKによって、Hardware dispatch queue (struct blk_mq_hw_ctx) のrun_workに設定される。
dispatch用のworkを遅延実行する
Dispatch用のWorkは、__blk_mq_delay_run_hw_queue関数によってWork Queueに追加 (遅延実行) される。
// 1560: static void __blk_mq_delay_run_hw_queue(struct blk_mq_hw_ctx *hctx, bool async, unsigned long msecs) { if (unlikely(blk_mq_hctx_stopped(hctx))) return; if (!async && !(hctx->flags & BLK_MQ_F_BLOCKING)) { int cpu = get_cpu(); if (cpumask_test_cpu(cpu, hctx->cpumask)) { __blk_mq_run_hw_queue(hctx); put_cpu(); return; } put_cpu(); } kblockd_mod_delayed_work_on(blk_mq_hctx_next_cpu(hctx), &hctx->run_work, msecs_to_jiffies(msecs)); }
__blk_mq_delay_run_hw_queue関数では、引数asyncによって非同期で実行させることができる。
async == FALSE: Dispatch を試みる (ドライバがBLK_MQ_F_BLOCKINGでない場合のみ)async == TRUE:mcescミリ秒後に Dispatch を実行する
ただし、mmcドライバはBLK_MQ_F_BLOCKINGとなるため、ここでは kblockd_mod_delayed_work_on関数による処理のみを確認する。
kblockd_mod_delayed_work_on関数では、blk_mq_alloc_hctx関数で初期化したblk_mq_run_work_fn関数を実行することになる。
blk_mq_run_work_fnの定義は次のようになっている。
// 1812: static void blk_mq_run_work_fn(struct work_struct *work) { struct blk_mq_hw_ctx *hctx; hctx = container_of(work, struct blk_mq_hw_ctx, run_work.work); /* * If we are stopped, don't run the queue. */ if (blk_mq_hctx_stopped(hctx)) return; __blk_mq_run_hw_queue(hctx); }
blk_mq_run_work_fn関数は、Hardware dispatch queueが停止状態でないことを確認する。
停止状態でなければ、__blk_mq_run_hw_queue関数を呼び出す。
リクエストを Hardware Queue に送信する
__blk_mq_run_hw_queue関数は次のような定義となっている。
// 1479: static void __blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx) { int srcu_idx; /* * We can't run the queue inline with ints disabled. Ensure that * we catch bad users of this early. */ WARN_ON_ONCE(in_interrupt()); might_sleep_if(hctx->flags & BLK_MQ_F_BLOCKING); hctx_lock(hctx, &srcu_idx); blk_mq_sched_dispatch_requests(hctx); hctx_unlock(hctx, srcu_idx); }
Dispatchでは、リクエストをキューに入れる際にブロッキングする恐れがある。
そのため、__blk_mq_delay_run_hw_queue関数と同様に、排他制御を意識する必要がある。
blk-mqでは、hctx_unlock関数とhctx_lock関数によって排他制御を担う。
ただし、RCUを取得している間は、blockingやsleeping が禁じられているため、BLK_MQ_F_BLOCKINGの場合には、Sleepable RCU (SRCU) の使用が必要となる。
// 691: static void hctx_unlock(struct blk_mq_hw_ctx *hctx, int srcu_idx) __releases(hctx->srcu) { if (!(hctx->flags & BLK_MQ_F_BLOCKING)) rcu_read_unlock(); else srcu_read_unlock(hctx->srcu, srcu_idx); } static void hctx_lock(struct blk_mq_hw_ctx *hctx, int *srcu_idx) __acquires(hctx->srcu) { if (!(hctx->flags & BLK_MQ_F_BLOCKING)) { /* shut up gcc false positive */ *srcu_idx = 0; rcu_read_lock(); } else *srcu_idx = srcu_read_lock(hctx->srcu); }
RCU (または、SRCU) によりロックが確保できた場合、Dispatchの本処理に移る。
その後、blk_mq_sched_dispatch_requests関数を実行する。
blk_mq_sched_dispatch_requests関数の定義は次の通りとなっている。
// 346: void blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx) { struct request_queue *q = hctx->queue; /* RCU or SRCU read lock is needed before checking quiesced flag */ if (unlikely(blk_mq_hctx_stopped(hctx) || blk_queue_quiesced(q))) return; hctx->run++; /* * A return of -EAGAIN is an indication that hctx->dispatch is not * empty and we must run again in order to avoid starving flushes. */ if (__blk_mq_sched_dispatch_requests(hctx) == -EAGAIN) { if (__blk_mq_sched_dispatch_requests(hctx) == -EAGAIN) blk_mq_run_hw_queue(hctx, true); } }
blk_mq_sched_dispatch_requests関数では、Hardware Dispatch Queueが停止状態・静止状態(quiesced)でない場合、__blk_mq_sched_dispatch_requests関数によってリクエストをディスパッチする。
この時、Hardware Dispatch Queueがビジー状態 (-EAGAIN) となる可能性がある。
blk_mq_sched_dispatch_requests関数では、Dispatchを2回まで実行する。
それでもリソースがビジー状態であった場合、blk_mq_run_hw_queue関数によって __blk_mq_delay_run_hw_queue関数を実行する。
また、リクエストのDispatch処理が呼び出された回数は debugfs上のインターフェースから確認することができる。
# cat /sys/kernel/debug/block/mmcblk0/hctx0/run
6
また、__blk_mq_sched_dispatch_requests関数の定義は次の通りとなっている。
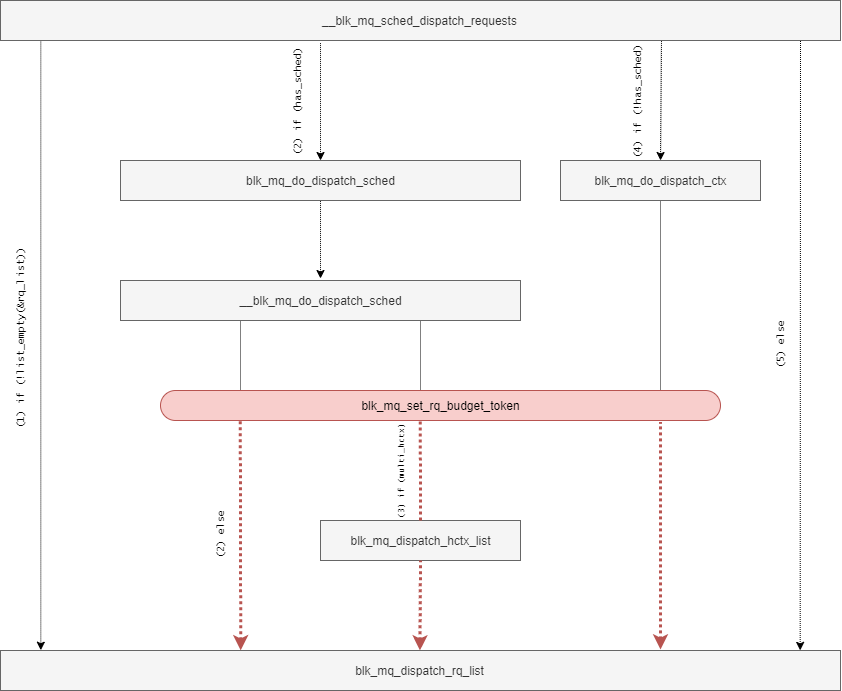
// 294: static int __blk_mq_sched_dispatch_requests(struct blk_mq_hw_ctx *hctx) { struct request_queue *q = hctx->queue; const bool has_sched = q->elevator; int ret = 0; LIST_HEAD(rq_list); /* * If we have previous entries on our dispatch list, grab them first for * more fair dispatch. */ if (!list_empty_careful(&hctx->dispatch)) { spin_lock(&hctx->lock); if (!list_empty(&hctx->dispatch)) list_splice_init(&hctx->dispatch, &rq_list); spin_unlock(&hctx->lock); } /* * Only ask the scheduler for requests, if we didn't have residual * requests from the dispatch list. This is to avoid the case where * we only ever dispatch a fraction of the requests available because * of low device queue depth. Once we pull requests out of the IO * scheduler, we can no longer merge or sort them. So it's best to * leave them there for as long as we can. Mark the hw queue as * needing a restart in that case. * * We want to dispatch from the scheduler if there was nothing * on the dispatch list or we were able to dispatch from the * dispatch list. */ if (!list_empty(&rq_list)) { blk_mq_sched_mark_restart_hctx(hctx); if (blk_mq_dispatch_rq_list(hctx, &rq_list, 0)) { if (has_sched) ret = blk_mq_do_dispatch_sched(hctx); else ret = blk_mq_do_dispatch_ctx(hctx); } } else if (has_sched) { ret = blk_mq_do_dispatch_sched(hctx); } else if (hctx->dispatch_busy) { /* dequeue request one by one from sw queue if queue is busy */ ret = blk_mq_do_dispatch_ctx(hctx); } else { blk_mq_flush_busy_ctxs(hctx, &rq_list); blk_mq_dispatch_rq_list(hctx, &rq_list, 0); } return ret; }
__blk_mq_sched_dispatch_requests関数では、大きく分けて二つの処理を担う。
- Software Staging Queue / I/Oスケジューラにあるリクエストを Hardware Dispatch Queue に追加する
- Hardware Dispatch Queue のリクエスト を デバイスドライバに追加する

ここで、デバイスドライバのHardware Queueのサイズには限りがあるため、必要以上のリクエストをディスパッチすることは避けたい。
また、Hardware QueueにDispatchされたリクエストは、I/Oスケジューラによる最適化の恩恵を受けることができない。
そのため、blk-mqでは、デバイスドライバにディスパッチする予定のリクエストをリスト(hctx->dispatch)として管理し、このリストが空の場合にI/Oスケジューラからリクエストをディスパッチする。
このリストは、次のような条件によって要素が追加される。
blk_mq_request_bypass_insert関数: PREFLUSH/FUAなどを即座にDispatch Queueに追加するためblk_mq_dispatch_rq_list関数: 自身が処理しきれなかったリクエストを積んて置くため
__blk_mq_sched_dispatch_requests関数はblk-mq内のデータの状態に応じて異なる処理を実行する。
hctx->dispatchが空でない場合:hctx->dispatchの要素をrq_listに追加し、blk_mq_dispatch_rq_list関数を実行する。- I/Oスケジューラが登録されている場合: I/Oスケジューラからリクエストをディスパッチするために
blk_mq_do_dispatch_sched関数を実行する。 - Hardware Dispatch Queueがビジー状態の場合: Software Staging Queue から リクエストをディスパッチする。
- それ以外: Software Staging Queue内の全要素を
rq_listに追加し、blk_mq_dispatch_rq_list関数を実行する。
おわりに
本記事では、リクエストをディスパッチがカーネルスレッドとして起動するところから、I/Oスケジューラからディスパッチする処理の直前となっている次の関数について確認した。
__blk_mq_delay_run_hw_queueblk_mq_run_work_fn__blk_mq_run_hw_queueblk_mq_sched_dispatch_requests__blk_mq_sched_dispatch_requests
変更履歴
- 2023/07/16: 記事公開
参考
VFATファイルシステムにおけるファイル名のコード変換
概要
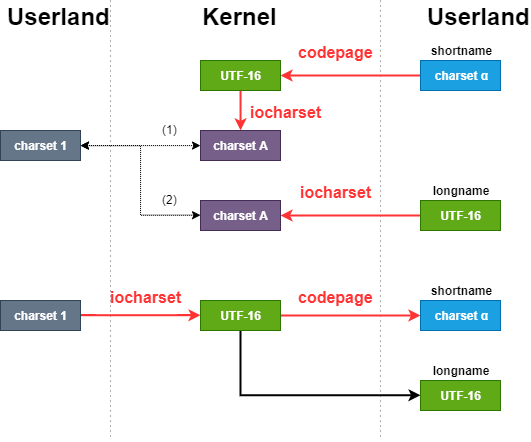
VFATファイルシステムでは、ユーザプログラムの文字コードを iocharsetで、short name をWindows側の codepageによって文字コードを取り扱う。
はじめに
複数の環境で動作させなければならないシステムにおいて、文字コードは考えなければならない要素の一つである。
文字コードは、規格が多数存在していることや暗黙的な変換が多数実施されていることといったこともあり理解することは困難である。
様々な環境で利用されることが考えられる外部記憶装置のSDカードでは、FATボリュームレイアウトでフォーマットされることが多い。 Linuxでは、FATボリュームレイアウトにあるファイルを閲覧/編集できるようにVFATファイルシステムが実装されている。
VFATファイルシステムでは、複数の文字コードに対応できるように複数のマウントオプションが用意されている。
マウントオプション iocharsetとcodepageは、ファイル名を指定した文字コードで変換する。
そのため、これらのマウントオプションを適切に指定していない場合には、ファイルを正しく検索することができなくなる。
memo
ここでは、フォントやローカル環境変数を考慮しない。
FATボリュームレイアウト
FATボリュームレイアウトでは、ファイル(またはディレクトリ)に対して short name と long name を設定することができる。
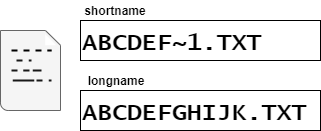
short nameは、MS-DOSとの互換性の観点から 8.3形式 XXXXXXXX.YYY(XとYは文字/数字)で保存する。
そのため、8.3形式ではないファイル名は8.3形式になるように切り詰められる。
long nameは、8.3形式ではないファイル名を8.3形式に切り詰められたときに完全なファイル名を保存する。
このとき、ファイル名は Unicodeコードポイントでストレージ上には保存される。
動作例
ここでは、次のような環境で実験している。
| 環境 | 概要 |
|---|---|
| CPU | AMD Ryzen 3 3300X |
| RAM | DDR4-2666 16GB ×2 |
| Host OS | Ubuntu Desktop 22.04.2 |
| kernel | 5.19.0-41-generic |
| System locale | LANG=ja_JP.UTF-8 |
Codepageが対応している文字列でファイルを作成する
UTF-8である場合には、iocharsetマウントオプションの代わりにutf8マウントオプションを利用することが推奨されている。
また、Codepage 932は MicrosoftがShift-JISを拡張したコードページとなっている。
leava@ubuntu:/work/$ sudo mount -t vfat -o utf8,codepage=932 /dev/sda1 /mnt/
Long nameが作成され、Shift-JISに変換できる文字列 SJIS で作成を作成する。
leava@ubuntu:/work/$ sudo touch /mnt/SJIS
ここで、これらの文字列は次のように表現される。
| 文字 | UTF-8 | Unicode | Shift-JIS | OEM-US |
|---|---|---|---|---|
S |
EFBCB3 | U+FF33 | 8272 | n/a |
J |
EFBCAA | U+FF2A | 8269 | n/a |
I |
EFBCA9 | U+FF29 | 8268 | n/a |
S |
EFBCB3 | U+FF33 | 8272 | n/a |
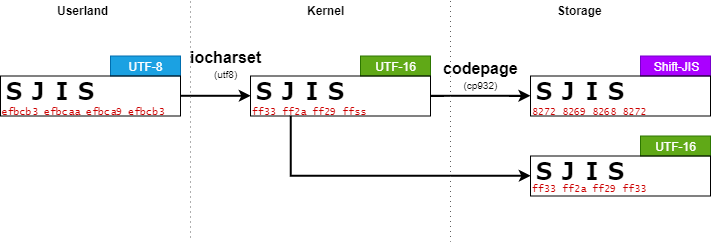
short nameとlong nameの両方で期待する結果となっている。
Codepageが対応していない文字列でファイルを作成する
Codepage 437は OEM-USとも呼ばれており、ギリシャ文字や特殊文字が含まれている。
ただし、このCodepageには大文字英数字が含まれていない。
leava@ubuntu:/work/$ sudo mount -t vfat -o utf8,codepage=437 /dev/sda1 /mnt/; leava@ubuntu:/work/$ sudo touch /mnt/SJIS
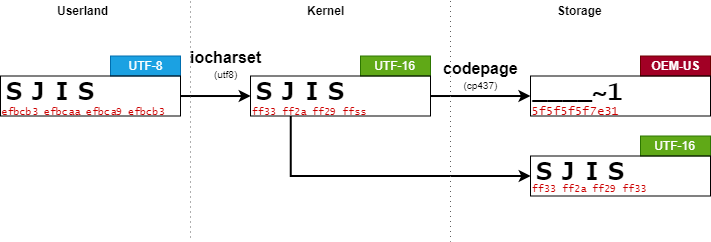
OEM-USでは、SJISを変換することができないため、short nameは_に置き換えられる。
システムとは異なるiocharsetでファイルを作成する
ISO8859-1、通称Latin-1は西ヨーロッパ諸言語向けの符号化集合である。
ただし、システムで使用している UTF-8とは互換性がなく大文字英数字が含まれていない。
leava@ubuntu:/work/$ sudo mount -t vfat -o iocharset=iso8859-1,codepage=932 /dev/sda1 /mnt/ leava@ubuntu:/work/$ sudo touch /mnt/SJIS
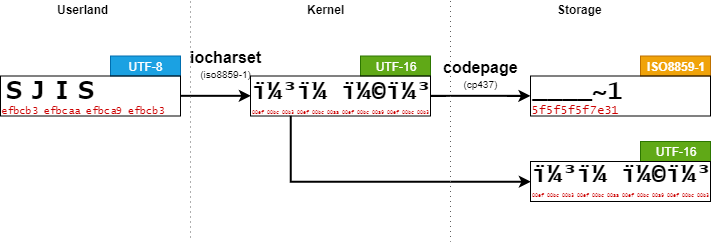
ISO8859-1は、1バイト文字コードであり UTF-8で入力された文字列は1バイトずつUTF-16に変換されてしまう。
その結果、short nameもlong nameも意図しないデータとして書き込まれてしまう。
Codepageが対応している文字列でファイルを検索する
ユーザプログラムからファイル名を検索するとき、作成するときと同様に文字コードの変換がされる。
そこで、Shift-JIS形式で保存された"SJIS"というファイルがトップディレクトリに存在する場合を考える。
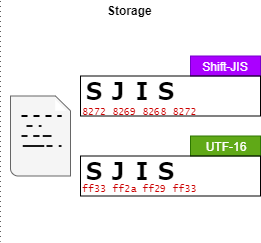
Shift-JISと互換のあるcp932でマウントする。
leava@ubuntu:/work/$ sudo mount -t vfat -o utf8,codepage=932 /dev/sda1 /mnt/ leava@ubuntu:/work/$ cat /mnt/SJIS; echo $? 0
この場合、short nameの変換した結果とユーザプログラムから入力された文字列"SJIS"と一致するため、ファイル検索に成功する。
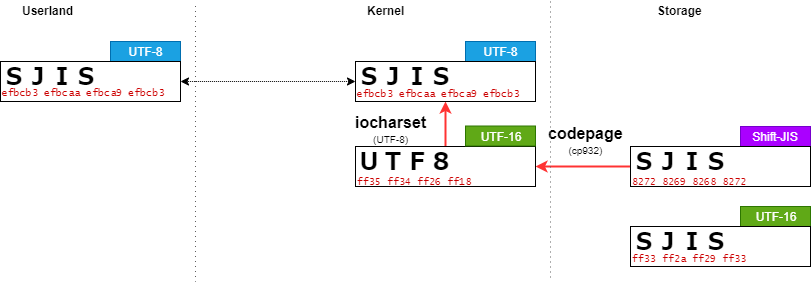
Codepageが対応していない文字列でファイルを検索する
Shift-JISとは互換がない cp437でマウントする。
leava@ubuntu:/work/$ sudo mount -t vfat -o utf8,codepage=437 /dev/sda1 /mnt/ leava@ubuntu:/work/$ cat /mnt/SJIS; echo $? 0
この場合、short nameは適切に変換することができない。
ただし、long nameはUTF-8に変換することができ、ユーザプログラムから入力された文字列"SJIS"と一致するため、ファイル検索に成功する。
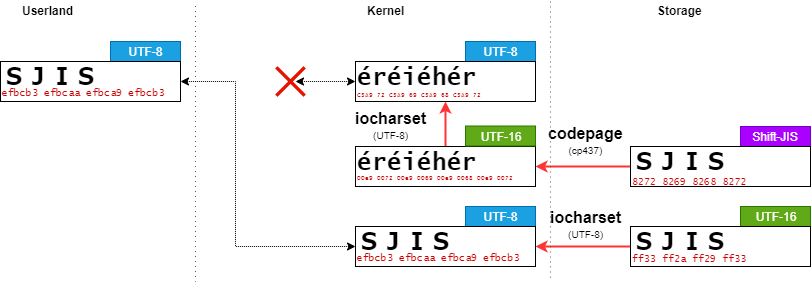
システムとは異なるiocharsetでファイルを検索する
UTF-8と互換性がないISO8859-1でマウントする。
leava@ubuntu:/work/$ sudo mount -t vfat -o iocharset=iso8859-1,codepage=437 /dev/sda1 /mnt/ leava@ubuntu:/work/$ cat /mnt/SJIS; echo $? 2
この場合、short nameは適切に変換することができない。
また、long nameもISO8859-1で変換することができないため、ファイル検索に失敗する。
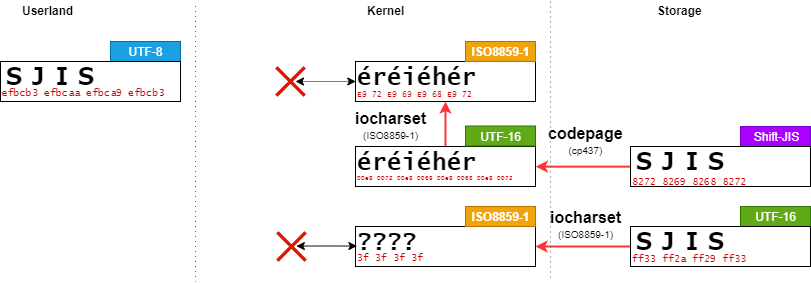
おわりに
FATボリュームレイアウトでは、short nameとlong nameで二つのファイル名を持ち、変換規則がそれぞれ異なる。
そのため、システムとは異なるiocharsetを設定してしまうと文字化けしてしまう恐れがある。
codepageは対向のWindowsと揃えておくことで互換性を保持することができる。
ただし、今回は ローカル環境変数とユーザプログラムで扱う文字列は同じUTF-8であることを想定している。
実際においては、これに加えて"フォントがその文字コードをサポートしている"かどうかなど複雑になるため注意。
変更履歴
- 2023/5/9: 記事公開
参考
Linuxカーネルのファイルアクセスの処理を追いかける (16) mq-deadline: dispatch_request
関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- Part 23: MMC (4) mmc_attach_sd
- Part 24: MMC (5) mmc_blk_probe
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、mq-deadline I/Oスケジューラのリクエストをディスパッチ(dd_dispatch_request)を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
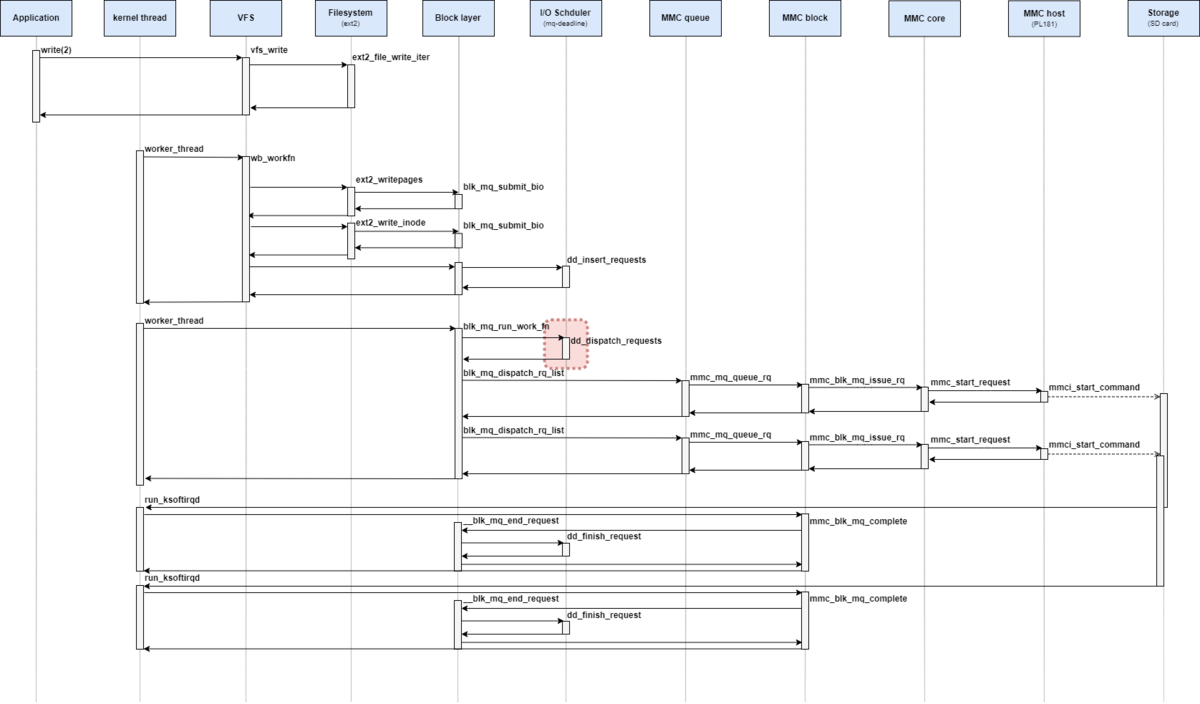
mq-deadlineの関数群
dd_has_work
dd_has_work関数は、elevetor_typeにあるopsのhas_workに設定され、__blk_mq_do_dispatch_sched関数から呼び出される関数となっている。
has_workでは、fifo_listやdispatchにリクエストが追加されているかどうかを確認する。

mq-deadline I/O スケジューラで登録されている dd_has_work関数の定義は次の通りとなっている。
// 787: static bool dd_has_work(struct blk_mq_hw_ctx *hctx) { struct deadline_data *dd = hctx->queue->elevator->elevator_data; enum dd_prio prio; for (prio = 0; prio <= DD_PRIO_MAX; prio++) if (dd_has_work_for_prio(&dd->per_prio[prio])) return true; return false; }
dd_has_work関数では、すべての優先度に対して dd_has_work_for_prio関数を呼び出す。
// 780: static bool dd_has_work_for_prio(struct dd_per_prio *per_prio) { return !list_empty_careful(&per_prio->dispatch) || !list_empty_careful(&per_prio->fifo_list[DD_READ]) || !list_empty_careful(&per_prio->fifo_list[DD_WRITE]); }
dd_dispatch_request
dd_has_work関数は、elevetor_typeにあるopsのhas_workに設定され、__blk_mq_do_dispatch_sched関数から呼び出される関数となっている。
dispatch_requestでは、fifo_listやdispatchからdispatchできるリクエストを返す。
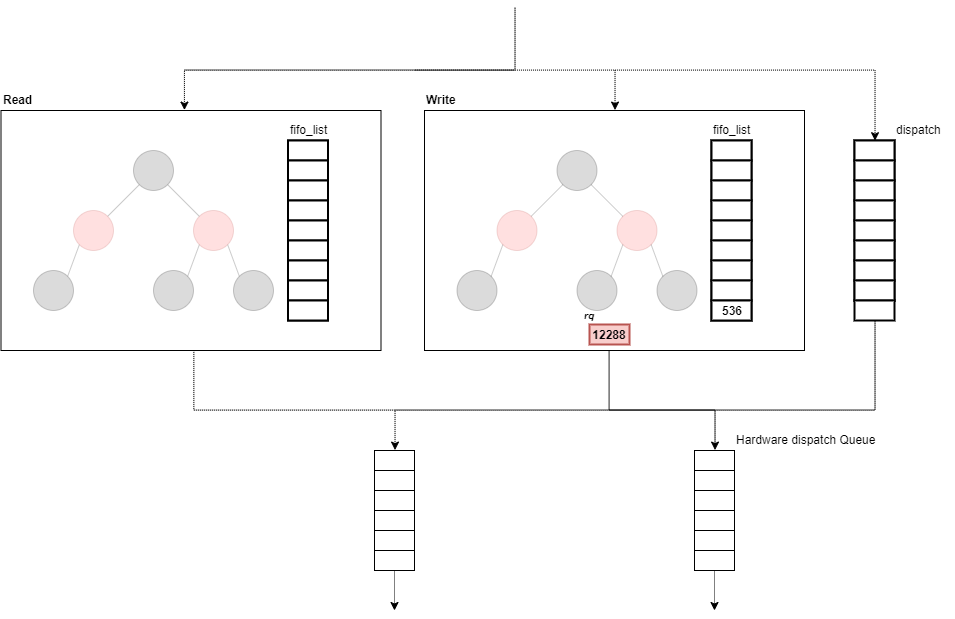
mq-deadline I/O スケジューラで登録されている dd_has_work関数の定義は次の通りとなっている。
// 477: static struct request *dd_dispatch_request(struct blk_mq_hw_ctx *hctx) { struct deadline_data *dd = hctx->queue->elevator->elevator_data; struct request *rq; enum dd_prio prio; spin_lock(&dd->lock); for (prio = 0; prio <= DD_PRIO_MAX; prio++) { rq = __dd_dispatch_request(dd, &dd->per_prio[prio]); if (rq) break; } spin_unlock(&dd->lock); return rq; }
dd_dispatch_request関数では、すべての優先度に対して __dd_dispatch_request関数を呼び出す。
// 362: static struct request *__dd_dispatch_request(struct deadline_data *dd, struct dd_per_prio *per_prio) { struct request *rq, *next_rq; enum dd_data_dir data_dir; enum dd_prio prio; u8 ioprio_class; lockdep_assert_held(&dd->lock); if (!list_empty(&per_prio->dispatch)) { rq = list_first_entry(&per_prio->dispatch, struct request, queuelist); list_del_init(&rq->queuelist); goto done; } /* * batches are currently reads XOR writes */ rq = deadline_next_request(dd, per_prio, dd->last_dir); if (rq && dd->batching < dd->fifo_batch) /* we have a next request are still entitled to batch */ goto dispatch_request; /* * at this point we are not running a batch. select the appropriate * data direction (read / write) */ if (!list_empty(&per_prio->fifo_list[DD_READ])) { BUG_ON(RB_EMPTY_ROOT(&per_prio->sort_list[DD_READ])); if (deadline_fifo_request(dd, per_prio, DD_WRITE) && (dd->starved++ >= dd->writes_starved)) goto dispatch_writes; data_dir = DD_READ; goto dispatch_find_request; } /* * there are either no reads or writes have been starved */ if (!list_empty(&per_prio->fifo_list[DD_WRITE])) { dispatch_writes: BUG_ON(RB_EMPTY_ROOT(&per_prio->sort_list[DD_WRITE])); dd->starved = 0; data_dir = DD_WRITE; goto dispatch_find_request; } return NULL; dispatch_find_request: /* * we are not running a batch, find best request for selected data_dir */ next_rq = deadline_next_request(dd, per_prio, data_dir); if (deadline_check_fifo(per_prio, data_dir) || !next_rq) { /* * A deadline has expired, the last request was in the other * direction, or we have run out of higher-sectored requests. * Start again from the request with the earliest expiry time. */ rq = deadline_fifo_request(dd, per_prio, data_dir); } else { /* * The last req was the same dir and we have a next request in * sort order. No expired requests so continue on from here. */ rq = next_rq; } /* * For a zoned block device, if we only have writes queued and none of * them can be dispatched, rq will be NULL. */ if (!rq) return NULL; dd->last_dir = data_dir; dd->batching = 0; dispatch_request: /* * rq is the selected appropriate request. */ dd->batching++; deadline_move_request(dd, per_prio, rq); done: ioprio_class = dd_rq_ioclass(rq); prio = ioprio_class_to_prio[ioprio_class]; dd_count(dd, dispatched, prio); /* * If the request needs its target zone locked, do it. */ blk_req_zone_write_lock(rq); rq->rq_flags |= RQF_STARTED; return rq; }
__dd_dispatch_request関数では、"リクエスト候補を検索するフェーズ"(dispatch_writesやdispatch_find_request)と"リクエストを抽出するフェーズ"(dispatch_request)に分かれる。
リクエスト候補となる条件は次の通りとなっている。
dispatchリストにリクエストが追加されている- 実行中のバッチがあり、R/Wの方向が同じである
- READ用のfifo_listにリクエストが追加されている
- WRITE用のfifo_listにリクエストが追加されている
リクエスト候補が見つかった場合には、 deadline_next_request関数でバッチ実行中のものを確認する。
もし、バッチ実行中でなければ、deadline_check_fifo関数でリクエストがdispatchすべきかどうかを取得する。
deadline_check_fifo関数の定義は次のようになっている。
// 277: static inline int deadline_check_fifo(struct dd_per_prio *per_prio, enum dd_data_dir data_dir) { struct request *rq = rq_entry_fifo(per_prio->fifo_list[data_dir].next); /* * rq is expired! */ if (time_after_eq(jiffies, (unsigned long)rq->fifo_time)) return 1; return 0; }
deadline_check_fifo関数では、リクエストが fifo に追加/更新された時刻からdeadlineした時刻 (fifo_time)をtime_after_eqマクロによって比較する。
その結果、そのリクエストが deadlineしている場合には、deadline_check_fifo関数は 1を返す。
リクエストがdispatchすべきであることがわかれば deadline_fifo_request関数でそのリクエストを取得する。
取得したリクエストは deadline_move_request関数によって、I/O scheduler(Elevator)に登録されている該当リクエストを削除する。
deadline_move_request関数の定義は次のようになっている。
// 259: static void deadline_move_request(struct deadline_data *dd, struct dd_per_prio *per_prio, struct request *rq) { const enum dd_data_dir data_dir = rq_data_dir(rq); per_prio->next_rq[data_dir] = deadline_latter_request(rq); /* * take it off the sort and fifo list */ deadline_remove_request(rq->q, per_prio, rq); }
deadline_move_request関数では、次のリクエストを next_rqに保持し、deadline_remove_request関数を呼び出す。
deadline_remove_request関数の定義は次のようになっている。
// 192: static void deadline_remove_request(struct request_queue *q, struct dd_per_prio *per_prio, struct request *rq) { list_del_init(&rq->queuelist); /* * We might not be on the rbtree, if we are doing an insert merge */ if (!RB_EMPTY_NODE(&rq->rb_node)) deadline_del_rq_rb(per_prio, rq); elv_rqhash_del(q, rq); if (q->last_merge == rq) q->last_merge = NULL; }
deadline_remove_request関数は、該当するリクエストをハッシュと赤黒木から削除する。
おわりに
本記事では、mq-deadline I/Oスケジューラのdd_has_work関数とdd_dispatch_request関数を確認した。
変更履歴
- 2023/05/06: 記事公開
参考
- Deadline IO scheduler tunables — The Linux Kernel documentation
- Deadline IO scheduler 公式ドキュメント
- https://blog.51cto.com/u_15061941/3859244
- 中国の記事だが、v4.20のmq-deadlineについてソースコード分析する