関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- 概要
- はじめに
- ext2ファイルシステムのボリュームレイアウト
- get_blockの概略
- オフセットの取得
- chainの作成
- chainの検証
- バッファキャッシュにマップする
- おわりに
- 変更履歴
- 参考
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、ext2_get_block関数を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
調査対象や環境などはPart 1: 環境セットアップを参照。
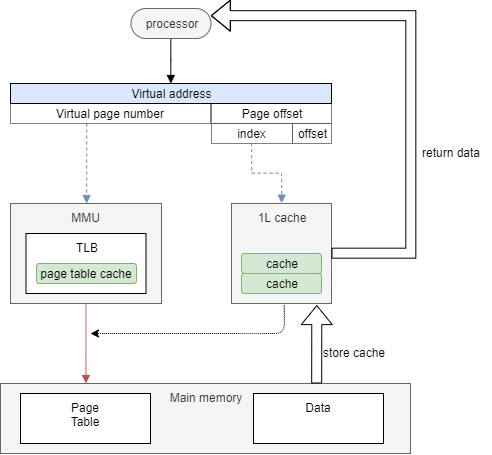
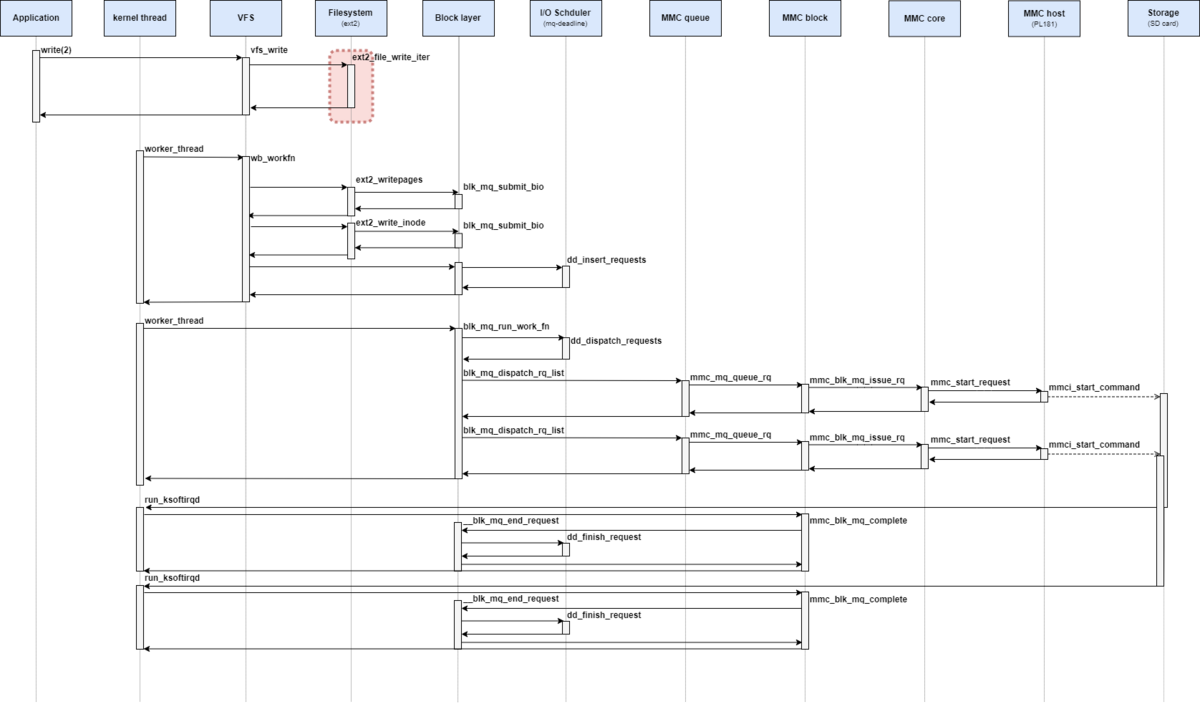
処理シーケンス図としては、下記の赤枠部分が該当する。
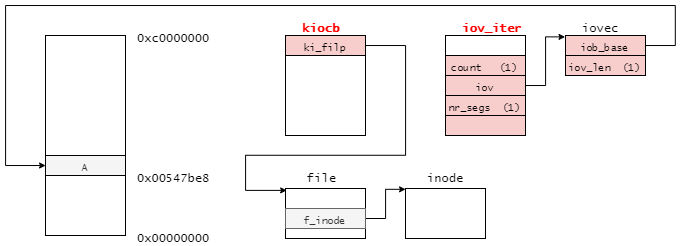
本記事では、ext2ファイルシステムのwrite_begin操作から呼び出されるget_block操作を解説する。
また本記事では、get_block操作は、ブロックがすでに確保されている場合のみに限定する。
ext2ファイルシステムのボリュームレイアウト
get_blockの処理に移る前にext2ファイルシステムのレイアウトを解説する。
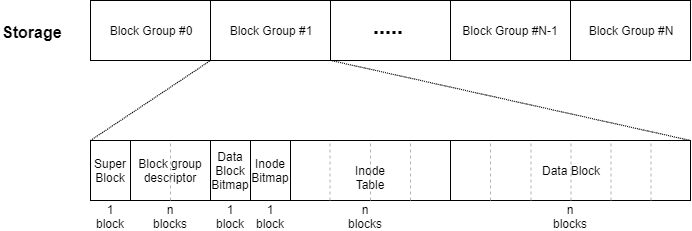
ext2ファイルシステムは複数のブロックグループ (Block Group)から構成されていて、各ブロックグループは複数のブロックから構成されている。
一つのブロックグループには、次のようなデータが格納されている。
- スーパーブロック : パーティション全体に関する情報 (1ブロック)
- ブロックグループディスクリプタ : そのブロックグループに関する情報 (複数ブロック)
- データブロックビットマップ : そのブロックグループにおけるデータブロックの空き情報 (1ブロック)
- iノードビットマップ : そのブロックグループにおけるiノードの空き情報(1ブロック)
- iノードテーブル : iノード (複数ブロック)
- データブロック : 実際のデータ (複数ブロック)
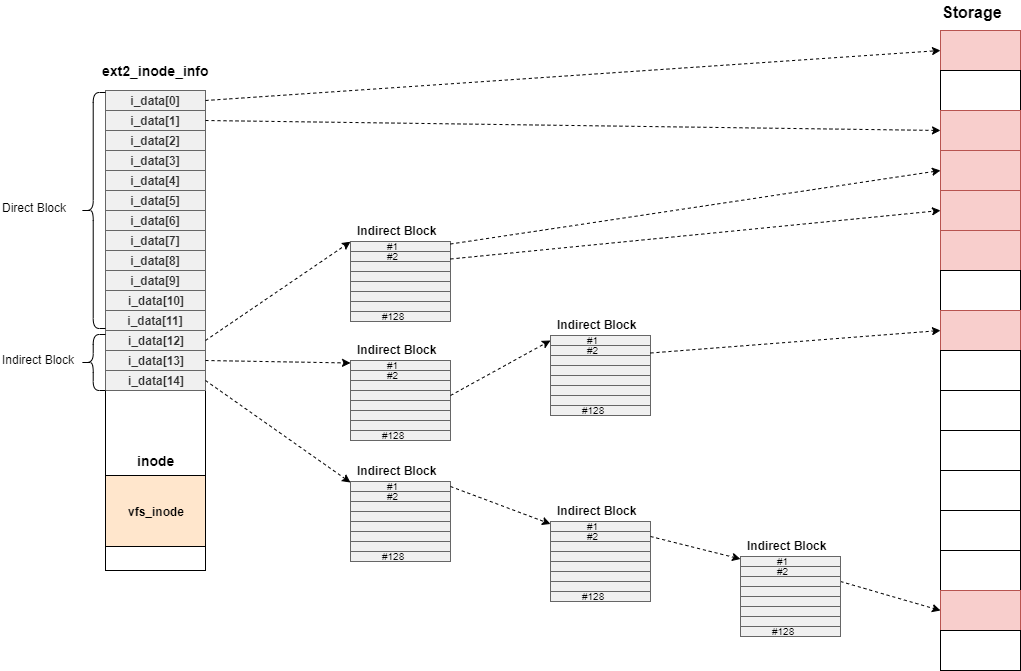
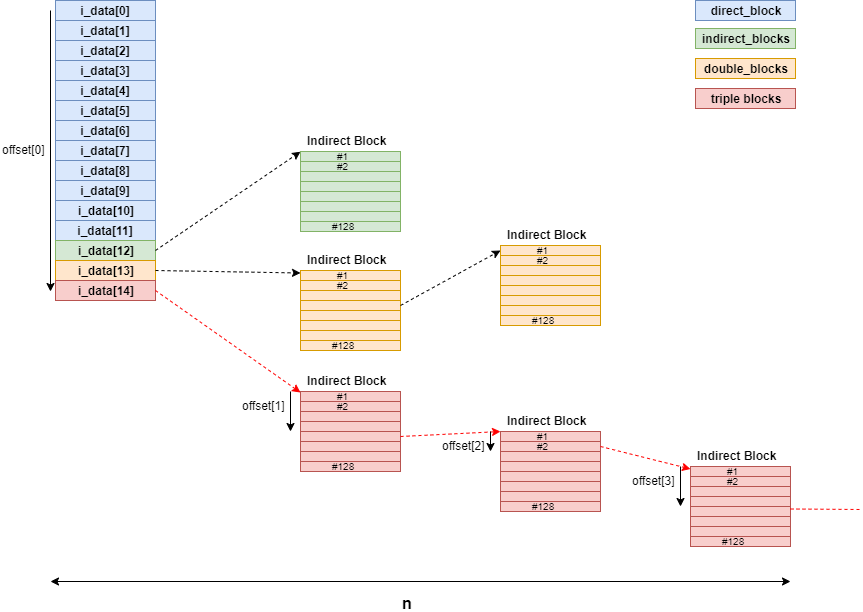
また、iノードにはi_dataと呼ばれるメンバが合計15個あり、i_dataがデータブロックを参照する。
ただし、i_data[12],i_data[13],i_data[14]に関しては、Indirect Blockと呼ばれるブロック番号のみを保持するブロックを参照する。
それぞれ、Indirect Blockを経由する個数が決まっており、i_data[12]は1回、i_data[13]は2回、i_data[14]は3回となっている。
これによって、ファイルサイズの小さいファイルに対しても効率的にデータを保存でき、かつファイルサイズの大きいファイルも扱うことができる。
ext2ファイルシステムの詳細については、解説記事や書籍を参照。
get_blockの概略
前回のwrite_begin操作(ext2_write_begin)は、ファイルシステムのブロックを取得するために、ext2_get_block関数を呼び出す。
このget_block操作はinode 構造体から指定されたブロックを取得する操作である。
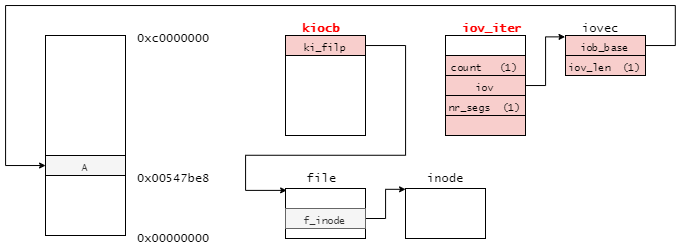
関数の定義は次のようになっており、対象ファイルのinode構造体と取得したデータのオフセットiblockを引数としてインプットすることで、対象のデータをbh_resultに返す。
このとき、指定されたオフセットのデータが存在しない場合、かつcreateフラグが立っている場合は、新しくブロックを確保する。
// 779: int ext2_get_block(struct inode *inode, sector_t iblock, struct buffer_head *bh_result, int create) { unsigned max_blocks = bh_result->b_size >> inode->i_blkbits; bool new = false, boundary = false; u32 bno; int ret; ret = ext2_get_blocks(inode, iblock, max_blocks, &bno, &new, &boundary, create); if (ret <= 0) return ret; map_bh(bh_result, inode->i_sb, bno); bh_result->b_size = (ret << inode->i_blkbits); if (new) set_buffer_new(bh_result); if (boundary) set_buffer_boundary(bh_result); return 0; }
ext2_get_block関数は、複数ブロックを取得するext2_get_blocks関数から構成される。
ただし、必ずしもブロックが一つのバッファキャッシュに収まるとは限らない。
変数max_blocksは、必要なバッファキャッシュの個数を表している。
ext2_get_blocks関数では、取得するブロックによって処理が異なる。
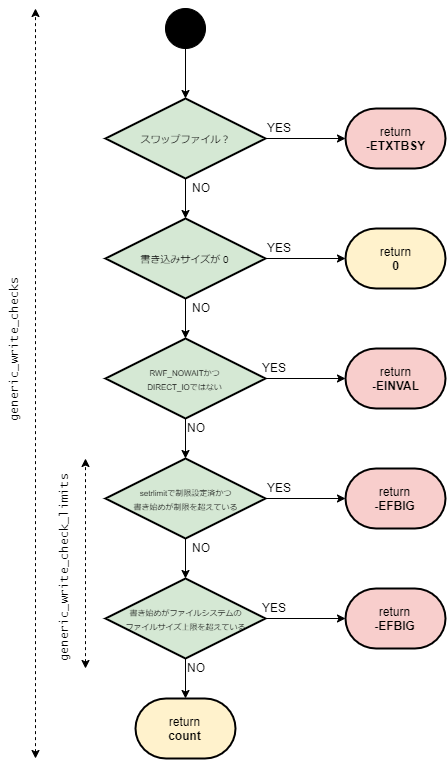
この関数の大まかなフローチャートを下記に示す。
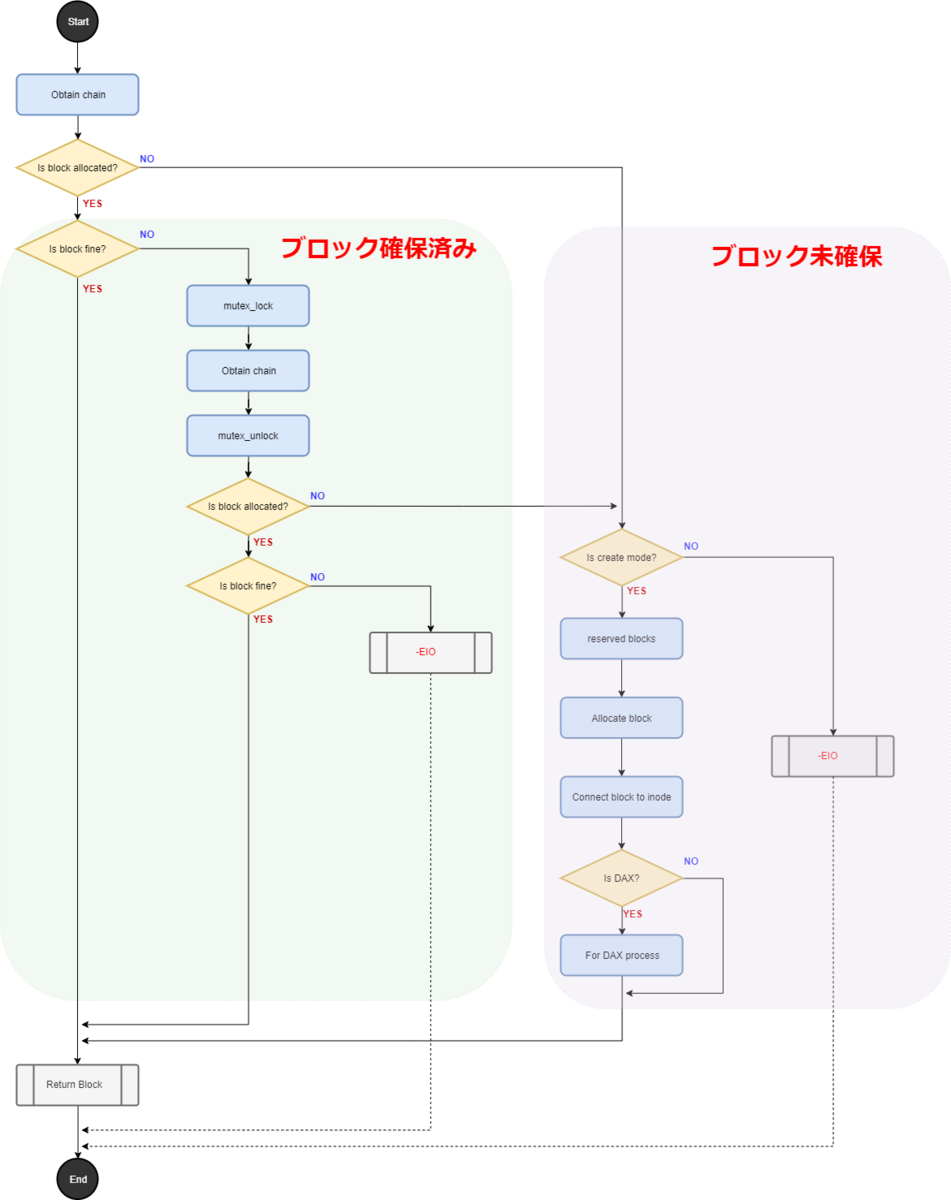
ext2_get_blocks関数を大きく分けて「取得するブロックが確保済みの場合」と「取得するブロックがまだ確保されていない場合」となる。
本記事では「取得するブロックが確保済みの場合」に注目して処理を確認していく。
まずは、ext2_get_blocks関数から確認していく。
// 620: static int ext2_get_blocks(struct inode *inode, sector_t iblock, unsigned long maxblocks, u32 *bno, bool *new, bool *boundary, int create) { int err; int offsets[4]; Indirect chain[4]; Indirect *partial; ext2_fsblk_t goal; int indirect_blks; int blocks_to_boundary = 0; int depth; struct ext2_inode_info *ei = EXT2_I(inode); int count = 0; ext2_fsblk_t first_block = 0; BUG_ON(maxblocks == 0); depth = ext2_block_to_path(inode,iblock,offsets,&blocks_to_boundary); if (depth == 0) return -EIO; partial = ext2_get_branch(inode, depth, offsets, chain, &err); /* Simplest case - block found, no allocation needed */ if (!partial) { first_block = le32_to_cpu(chain[depth - 1].key); count++; /*map more blocks*/ while (count < maxblocks && count <= blocks_to_boundary) { ext2_fsblk_t blk; if (!verify_chain(chain, chain + depth - 1)) { /* * Indirect block might be removed by * truncate while we were reading it. * Handling of that case: forget what we've * got now, go to reread. */ err = -EAGAIN; count = 0; partial = chain + depth - 1; break; } blk = le32_to_cpu(*(chain[depth-1].p + count)); if (blk == first_block + count) count++; else break; } if (err != -EAGAIN) goto got_it; } /* Next simple case - plain lookup or failed read of indirect block */ if (!create || err == -EIO) goto cleanup; mutex_lock(&ei->truncate_mutex); /* * If the indirect block is missing while we are reading * the chain(ext2_get_branch() returns -EAGAIN err), or * if the chain has been changed after we grab the semaphore, * (either because another process truncated this branch, or * another get_block allocated this branch) re-grab the chain to see if * the request block has been allocated or not. * * Since we already block the truncate/other get_block * at this point, we will have the current copy of the chain when we * splice the branch into the tree. */ if (err == -EAGAIN || !verify_chain(chain, partial)) { while (partial > chain) { brelse(partial->bh); partial--; } partial = ext2_get_branch(inode, depth, offsets, chain, &err); if (!partial) { count++; mutex_unlock(&ei->truncate_mutex); goto got_it; } if (err) { mutex_unlock(&ei->truncate_mutex); goto cleanup; } } /* * Okay, we need to do block allocation. Lazily initialize the block * allocation info here if necessary */ if (S_ISREG(inode->i_mode) && (!ei->i_block_alloc_info)) ext2_init_block_alloc_info(inode); goal = ext2_find_goal(inode, iblock, partial); /* the number of blocks need to allocate for [d,t]indirect blocks */ indirect_blks = (chain + depth) - partial - 1; /* * Next look up the indirect map to count the total number of * direct blocks to allocate for this branch. */ count = ext2_blks_to_allocate(partial, indirect_blks, maxblocks, blocks_to_boundary); /* * XXX ???? Block out ext2_truncate while we alter the tree */ err = ext2_alloc_branch(inode, indirect_blks, &count, goal, offsets + (partial - chain), partial); if (err) { mutex_unlock(&ei->truncate_mutex); goto cleanup; } if (IS_DAX(inode)) { /* * We must unmap blocks before zeroing so that writeback cannot * overwrite zeros with stale data from block device page cache. */ clean_bdev_aliases(inode->i_sb->s_bdev, le32_to_cpu(chain[depth-1].key), count); /* * block must be initialised before we put it in the tree * so that it's not found by another thread before it's * initialised */ err = sb_issue_zeroout(inode->i_sb, le32_to_cpu(chain[depth-1].key), count, GFP_NOFS); if (err) { mutex_unlock(&ei->truncate_mutex); goto cleanup; } } *new = true; ext2_splice_branch(inode, iblock, partial, indirect_blks, count); mutex_unlock(&ei->truncate_mutex); got_it: if (count > blocks_to_boundary) *boundary = true; err = count; /* Clean up and exit */ partial = chain + depth - 1; /* the whole chain */ cleanup: while (partial > chain) { brelse(partial->bh); partial--; } if (err > 0) *bno = le32_to_cpu(chain[depth-1].key); return err; }
必要なバッファキャッシュの個数maxblocksが0となることは通常ありえないので、その場合はBUG_ONマクロによってカーネルパニックを引き起こす。
この関数では、Indirect型が用いて取得するブロック間の関係性を表現する。
Indirect型は、下記のような定義となっており、ポインタと整数型のキー値とバッファキャッシュのポインタを持つ構造体である。
// 114: typedef struct { __le32 *p; __le32 key; struct buffer_head *bh; } Indirect;
Indirect型のメンバはそれぞれ、次のデータが格納されていく。
p: Indirect Blockの該当のオフセットへのポインタkey: Indirect Blockの該当オフセットに格納されているブロック番号の値bh: 次のIndirect Blockと関連付けているbuffer_headへのポインタ
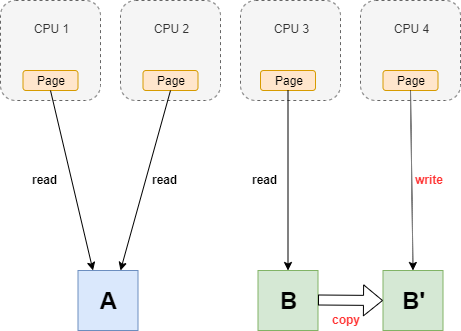
例えば、Indirect Block #???とIndirect Block #4111の関係性を表すようなIndirect型のデータ構造は次の通りとなる。
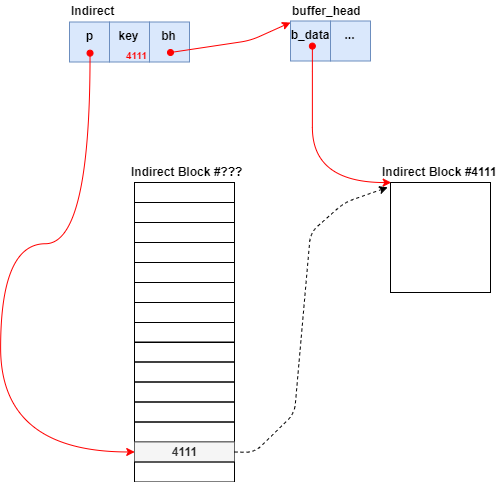
上記の内容を踏まえたうえで、ext2_get_blocks関数の処理に戻る。
オフセットの取得
ext2_get_blocks関数で最初に実施することは、「オフセットの取得」である。
この処理に該当するソースコードは下記の部分となっている。
// 639: depth = ext2_block_to_path(inode,iblock,offsets,&blocks_to_boundary); if (depth == 0) return -EIO;
ext2_block_to_path関数は、ファイルのinodeとブロック番号iblockを渡し、それぞれのIndirect Blockにおけるオフセットoffsetを返す。
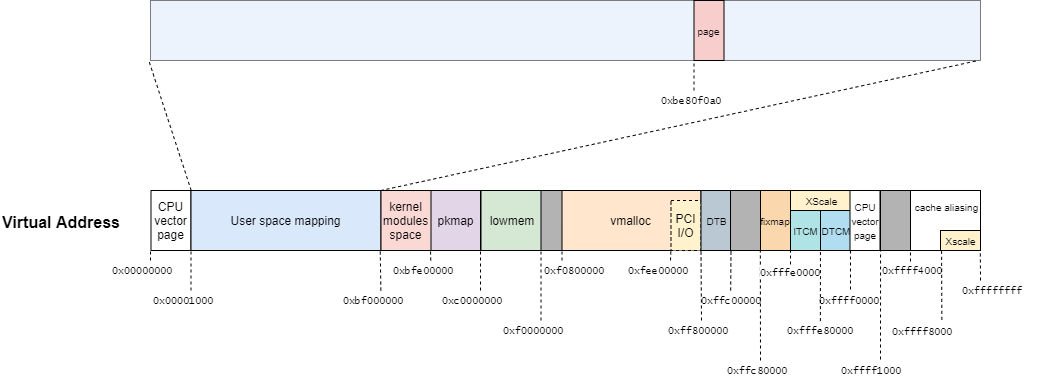
// 163: static int ext2_block_to_path(struct inode *inode, long i_block, int offsets[4], int *boundary) { int ptrs = EXT2_ADDR_PER_BLOCK(inode->i_sb); int ptrs_bits = EXT2_ADDR_PER_BLOCK_BITS(inode->i_sb); const long direct_blocks = EXT2_NDIR_BLOCKS, indirect_blocks = ptrs, double_blocks = (1 << (ptrs_bits * 2)); int n = 0; int final = 0; if (i_block < 0) { ext2_msg(inode->i_sb, KERN_WARNING, "warning: %s: block < 0", __func__); } else if (i_block < direct_blocks) { offsets[n++] = i_block; final = direct_blocks; } else if ( (i_block -= direct_blocks) < indirect_blocks) { offsets[n++] = EXT2_IND_BLOCK; offsets[n++] = i_block; final = ptrs; } else if ((i_block -= indirect_blocks) < double_blocks) { offsets[n++] = EXT2_DIND_BLOCK; offsets[n++] = i_block >> ptrs_bits; offsets[n++] = i_block & (ptrs - 1); final = ptrs; } else if (((i_block -= double_blocks) >> (ptrs_bits * 2)) < ptrs) { offsets[n++] = EXT2_TIND_BLOCK; offsets[n++] = i_block >> (ptrs_bits * 2); offsets[n++] = (i_block >> ptrs_bits) & (ptrs - 1); offsets[n++] = i_block & (ptrs - 1); final = ptrs; } else { ext2_msg(inode->i_sb, KERN_WARNING, "warning: %s: block is too big", __func__); } if (boundary) *boundary = final - 1 - (i_block & (ptrs - 1)); return n; }
ext2_block_to_path関数のイメージ図は次のとおりである。
chainの作成
各Indirect Blockのオフセットが取得できたら、これらをIndirect型に代入していく。
ext2_get_branch関数が該当する関数となる。
// 644: partial = ext2_get_branch(inode, depth, offsets, chain, &err);
ext2_get_branch関数は、ファイルのinodeとIndirect Blockの数depthと各Indirect Blockのオフセットoffsetを渡し、ブロックが未確保の場合には Indirect型のpを返す。
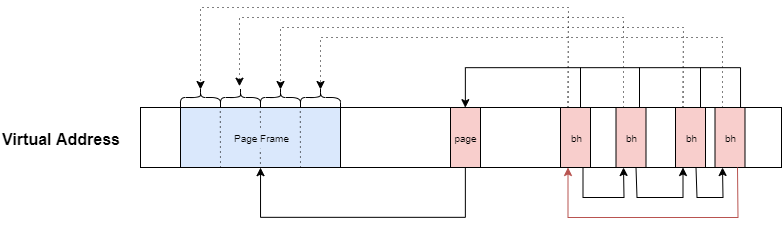
// 234: static Indirect *ext2_get_branch(struct inode *inode, int depth, int *offsets, Indirect chain[4], int *err) { struct super_block *sb = inode->i_sb; Indirect *p = chain; struct buffer_head *bh; *err = 0; /* i_data is not going away, no lock needed */ add_chain (chain, NULL, EXT2_I(inode)->i_data + *offsets); if (!p->key) goto no_block; while (--depth) { bh = sb_bread(sb, le32_to_cpu(p->key)); if (!bh) goto failure; read_lock(&EXT2_I(inode)->i_meta_lock); if (!verify_chain(chain, p)) goto changed; add_chain(++p, bh, (__le32*)bh->b_data + *++offsets); read_unlock(&EXT2_I(inode)->i_meta_lock); if (!p->key) goto no_block; } return NULL; changed: read_unlock(&EXT2_I(inode)->i_meta_lock); brelse(bh); *err = -EAGAIN; goto no_block; failure: *err = -EIO; no_block: return p; }
ext2_get_branch関数でchainがどのように連結されるのかを表したものが下記となる。
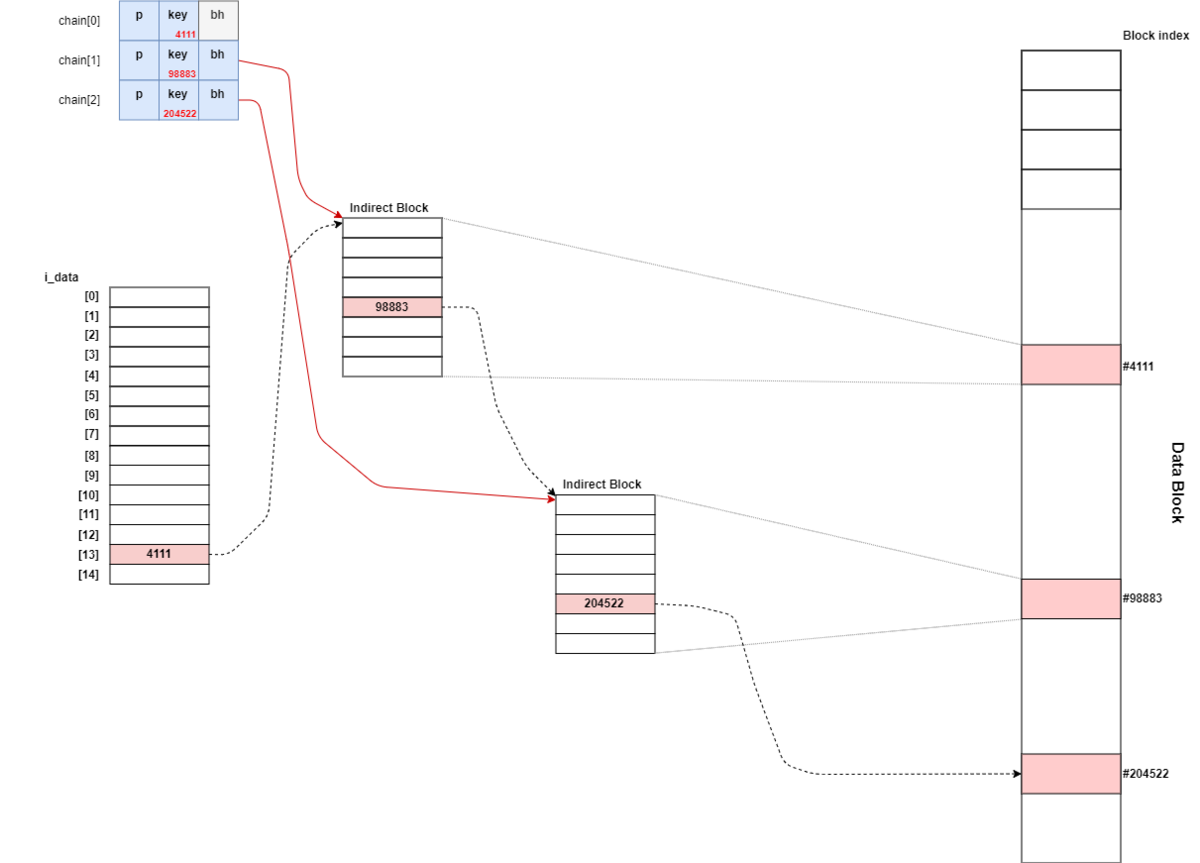
ext2_get_branch関数の処理を大まかにまとめると次の通りとなる。
- 0番目のchainを作成する
- ブロック番号がまだ格納されていない場合、ブロック未確保となるので
ext2_get_blocks関数でブロックを確保する - Indirect Blockが存在する場合、実ブロックまで下記をループする
p->keyから次のブロック番号を取得し、そのブロック番号を用いてsb_bread関数で次のブロックを取得するi_meta_lockのread_lockを取得する- 取得したブロックを検証する
i_meta_lockのread_lockを開放する
ここでchainの作成には、add_chain関数よって実現される。
// 120: static inline void add_chain(Indirect *p, struct buffer_head *bh, __le32 *v) { p->key = *(p->p = v); p->bh = bh; }
また、作成したchainが妥当であるか確認するために、verity_chain関数を呼び出す。
// 126: static inline int verify_chain(Indirect *from, Indirect *to) { while (from <= to && from->key == *from->p) from++; return (from > to); }
ext2_get_branch関数から呼び出されるverify_chain関数では、下記を確認している。
- 作成したchain(
p) が引数のchain(chain)と同じ、または新しいこと - chainのポインタ
from->pで参照している値と、chainの値from->keyの値が一致していること
ext2_get_branch関数でchainの生成ができた、またはブロックの新規確保が必要と判断ができる。
chainの検証
ブロックがすでに確保済みである場合は、chainにある適切なデータを返す。
処理としては下記のブロックとなる。
// 645: /* Simplest case - block found, no allocation needed */ if (!partial) { first_block = le32_to_cpu(chain[depth - 1].key); count++; /*map more blocks*/ while (count < maxblocks && count <= blocks_to_boundary) { ext2_fsblk_t blk; if (!verify_chain(chain, chain + depth - 1)) { /* * Indirect block might be removed by * truncate while we were reading it. * Handling of that case: forget what we've * got now, go to reread. */ err = -EAGAIN; count = 0; partial = chain + depth - 1; break; } blk = le32_to_cpu(*(chain[depth-1].p + count)); if (blk == first_block + count) count++; else break; } if (err != -EAGAIN) goto got_it; }
このブロックの処理を簡潔にまとめると、「chainの先頭からverify_chain関数で検証しながら、データブロックを変数blkを取得する」。
このとき、適切であるかどうかをverify_chain関数で確認する。
検証に成功した場合
verify_chain関数で検証に成功した場合、got_itラベルにジャンプする。
got_itラベルは下記の場所に定義されている。
// 763: got_it: if (count > blocks_to_boundary) *boundary = true; err = count; /* Clean up and exit */ partial = chain + depth - 1; /* the whole chain */ cleanup: while (partial > chain) { brelse(partial->bh); partial--; } if (err > 0) *bno = le32_to_cpu(chain[depth-1].key); return err;
ここで、取得したバッファを開放 (リファレンスカウントをデクリメントする)をした後に、bnoに結果を格納して終了する。
検証に失敗した場合
verify_chain関数で検証に失敗した場合は、セマフォを確保した状態で再度chainの生成をする。(失敗する要因として、他のプロセスやコンテキストスイッチなどの影響で変化してしまった場合などがある)
// 679: mutex_lock(&ei->truncate_mutex); /* * If the indirect block is missing while we are reading * the chain(ext2_get_branch() returns -EAGAIN err), or * if the chain has been changed after we grab the semaphore, * (either because another process truncated this branch, or * another get_block allocated this branch) re-grab the chain to see if * the request block has been allocated or not. * * Since we already block the truncate/other get_block * at this point, we will have the current copy of the chain when we * splice the branch into the tree. */ if (err == -EAGAIN || !verify_chain(chain, partial)) { while (partial > chain) { brelse(partial->bh); partial--; } partial = ext2_get_branch(inode, depth, offsets, chain, &err); if (!partial) { count++; mutex_unlock(&ei->truncate_mutex); goto got_it; } if (err) { mutex_unlock(&ei->truncate_mutex); goto cleanup; } }
再度、ext2_get_branch関数を呼び出し、chainが取得できた場合はgot_itラベル、できない場合はcleanupラベルにジャンプする。
バッファキャッシュにマップする
再掲となるが、ext2_get_blocks関数直後のコードは次の通りとなっている。
// 789: if (ret <= 0) return ret; map_bh(bh_result, inode->i_sb, bno); bh_result->b_size = (ret << inode->i_blkbits); if (new) set_buffer_new(bh_result); if (boundary) set_buffer_boundary(bh_result); return 0;
ext2_get_blocks関数によって指定した関数を取得できた場合は、map_bh関数を実行する。
この関数では、引数のbuffer_headに対応するデータが記憶装置上のデータとマップしているフラグを付与する。
// 341: static inline void map_bh(struct buffer_head *bh, struct super_block *sb, sector_t block) { set_buffer_mapped(bh); bh->b_bdev = sb->s_bdev; bh->b_blocknr = block; bh->b_size = sb->s_blocksize; }
また、バッファキャッシュが新規に作られた場合はnewフラグを立て、Boundary Bufferである場合はboundaryフラグを立てる。
get_block操作では、該当のブロックをbh_resultに更新とフラグの更新をして処理を終了する。
おわりに
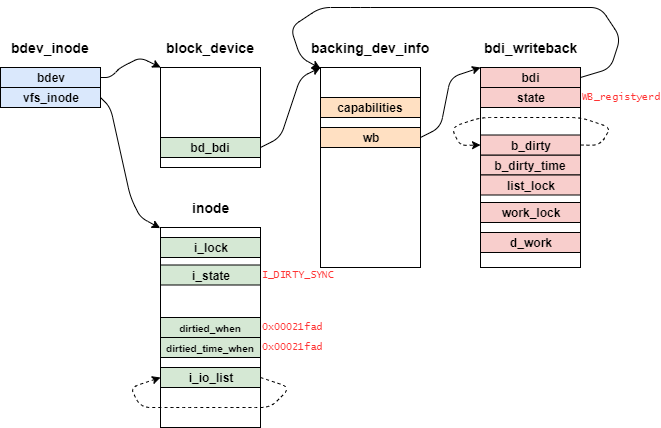
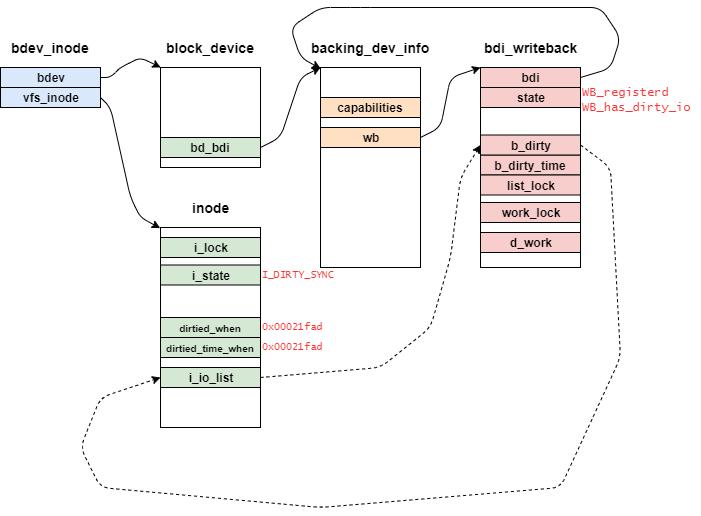
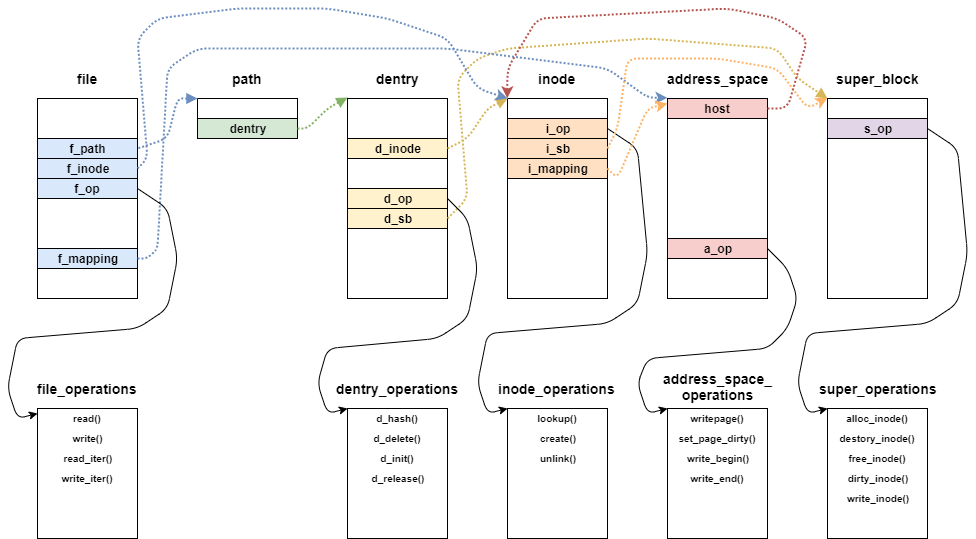
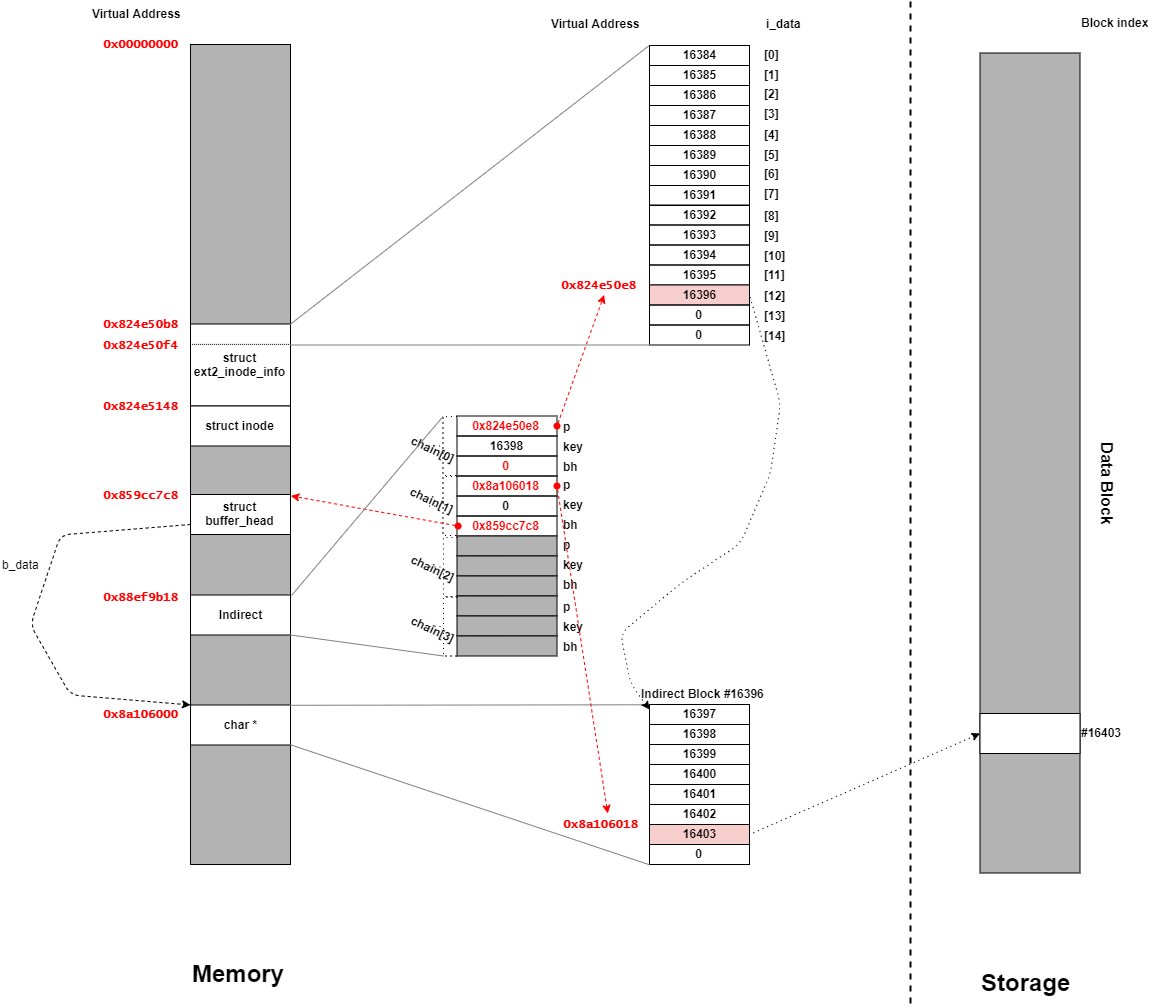
ext2_get_block関数で登場するデータ構造を表したものが下記となる。
変更履歴
- 2021/7/23: 記事公開
- 2022/09/19: カーネルバージョンを5.15に変更