#!/bin/bashPATH=/sbin:/bin:/usr/sbin:/usr/sbin
set-emtrap rescue ERR
functionrescue {echo -e "\e[31m NG \e[m"exec /bin/sh
}echo -n "[init] Connect console:"if (exec0</dev/console)2>/dev/null;thenexec0</dev/console
exec1>/dev/console
exec2>/dev/console
fiecho -e "\e[32m OK \e[m"echo -n "[init] Mount filesystem:"# mount -t devtmpfs udev /dev
mount -t proc /proc /proc
mount -t sysfs sysfs /sys
echo -e "\e[32m OK \e[m"echo -n "[init] Mount filesystem additionaly:"
mount -t tmpfs -osize=32m tmpfs /tmp
if [-d"/dev/pts"];then
mount -t devpts /dev/pts /dev/pts
fiif [-d"/sys/kernel/debug"];then
mount -t debugfs none /sys/kernel/debug
fiecho -e "\e[32m OK \e[m"exec setsid /sbin/agetty --long-hostname--autologin root -s ttyAMA0 115200,38400,9600 linux
起動確認
$ sudo qemu-system-arm -M vexpress-a9 \-smp1\-m1024\-kernel output/images/zImage \-dtb output/images/vexpress-v2p-ca9.dtb \-append"console=ttyAMA0,115200 rootwait ip=on root=/dev/nfs nfsroot=/srv/rootfs/armhf user_debug=31 rw"\-netnic,model=lan9118 \-net user \-nographic
...
VFS: Mounted root (nfs filesystem) on device 0:14.
devtmpfs: mounted
Freeing unused kernel memory: 1024K
Run /sbin/init as init process
random: fast init done[init] Connect console: OK
[init] Mount filesystem: OK
[init] Mount filesystem additionaly: OK
Ubuntu 20.04.3 LTS 10.0.2.15 ttyAMA0
10.0.2.15 login: root (automatic login)
Welcome to Ubuntu 20.04.3 LTS (GNU/Linux 5.10.1 armv7l)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize'command.
Last login: Sun Oct 10 11:57:52 JST 2021 on ttyAMA0
root@10:~#
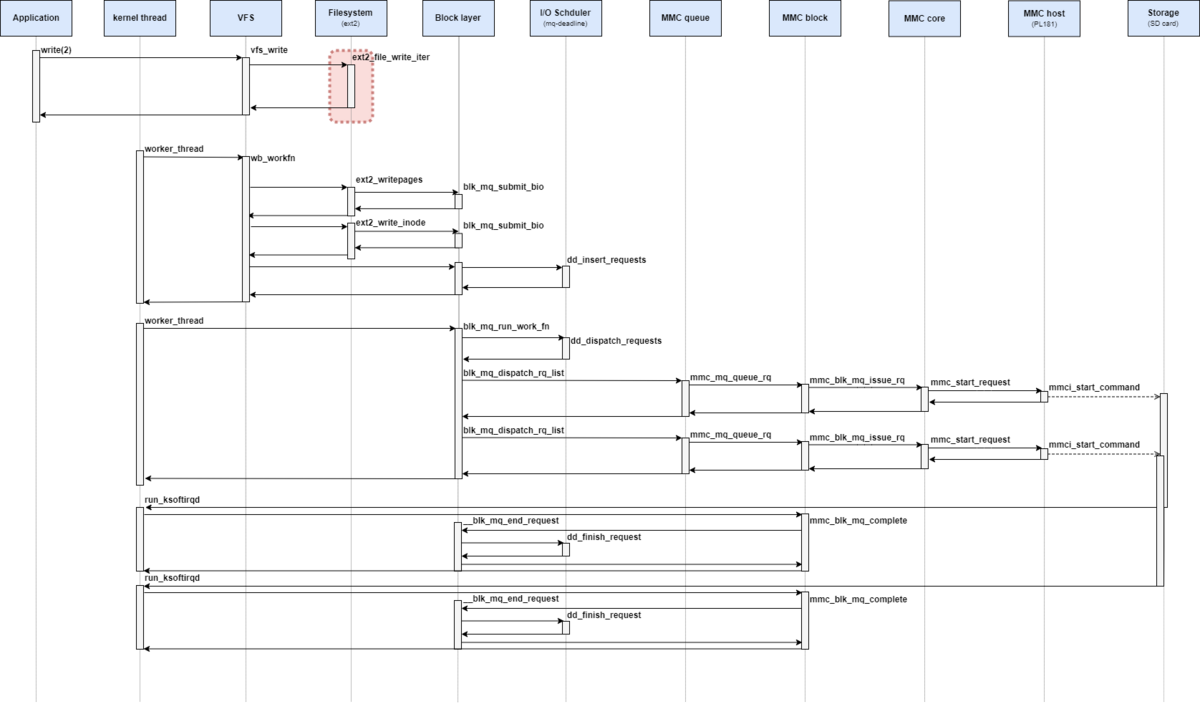
// 2168:intgeneric_write_end(struct file *file, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata)
{
struct inode *inode = mapping->host;
loff_t old_size = inode->i_size;
bool i_size_changed = false;
copied = block_write_end(file, mapping, pos, len, copied, page, fsdata);
/* * No need to use i_size_read() here, the i_size cannot change under us * because we hold i_rwsem. * * But it's important to update i_size while still holding page lock: * page writeout could otherwise come in and zero beyond i_size. */if (pos + copied > inode->i_size) {
i_size_write(inode, pos + copied);
i_size_changed = true;
}
unlock_page(page);
put_page(page);
if (old_size < pos)
pagecache_isize_extended(inode, old_size, pos);
/* * Don't mark the inode dirty under page lock. First, it unnecessarily * makes the holding time of page lock longer. Second, it forces lock * ordering of page lock and transaction start for journaling * filesystems. */if (i_size_changed)
mark_inode_dirty(inode);
return copied;
}
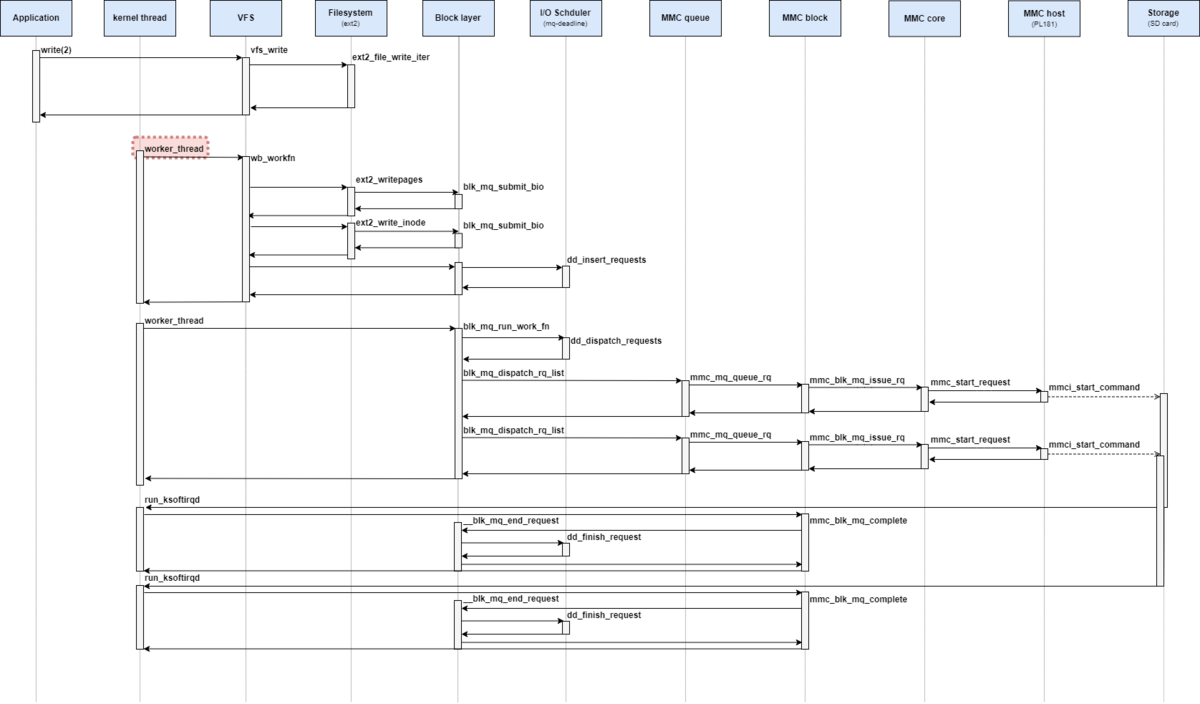
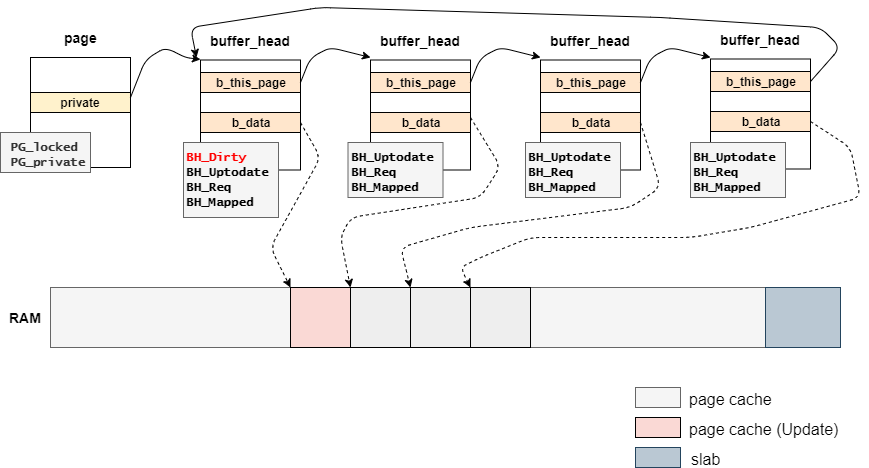
generic_write_end関数の処理は下記の通りとなっている。
ページキャッシュのフラグを更新する
バッファキャッシュのフラグを更新する
ファイルサイズを更新する
まず初めに、メインとなるblock_write_end関数から確認していく。
キャッシュのフラグの更新
block_write_end関数は下記のような定義となっている。
// 2132:intblock_write_end(struct file *file, struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata)
{
struct inode *inode = mapping->host;
unsigned start;
start = pos & (PAGE_SIZE - 1);
if (unlikely(copied < len)) {
/* * The buffers that were written will now be uptodate, so we * don't have to worry about a readpage reading them and * overwriting a partial write. However if we have encountered * a short write and only partially written into a buffer, it * will not be marked uptodate, so a readpage might come in and * destroy our partial write. * * Do the simplest thing, and just treat any short write to a * non uptodate page as a zero-length write, and force the * caller to redo the whole thing. */if (!PageUptodate(page))
copied = 0;
page_zero_new_buffers(page, start+copied, start+len);
}
flush_dcache_page(page);
/* This could be a short (even 0-length) commit */__block_commit_write(inode, page, start, start+copied);
return copied;
}
// 2064:staticint__block_commit_write(struct inode *inode, struct page *page,
unsigned from, unsigned to)
{
unsigned block_start, block_end;
int partial = 0;
unsigned blocksize;
struct buffer_head *bh, *head;
bh = head = page_buffers(page);
blocksize = bh->b_size;
block_start = 0;
do {
block_end = block_start + blocksize;
if (block_end <= from || block_start >= to) {
if (!buffer_uptodate(bh))
partial = 1;
} else {
set_buffer_uptodate(bh);
mark_buffer_dirty(bh);
}
if (buffer_new(bh))
clear_buffer_new(bh);
block_start = block_end;
bh = bh->b_this_page;
} while (bh != head);
/* * If this is a partial write which happened to make all buffers * uptodate then we can optimize away a bogus readpage() for * the next read(). Here we 'discover' whether the page went * uptodate as a result of this (potentially partial) write. */if (!partial)
SetPageUptodate(page);
return0;
}
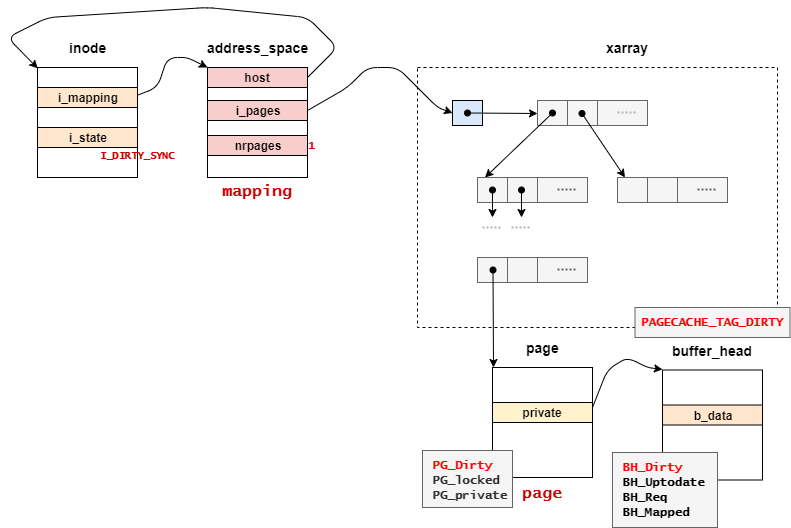
// 1082:voidmark_buffer_dirty(struct buffer_head *bh)
{
WARN_ON_ONCE(!buffer_uptodate(bh));
trace_block_dirty_buffer(bh);
/* * Very *carefully* optimize the it-is-already-dirty case. * * Don't let the final "is it dirty" escape to before we * perhaps modified the buffer. */if (buffer_dirty(bh)) {
smp_mb();
if (buffer_dirty(bh))
return;
}
if (!test_set_buffer_dirty(bh)) {
struct page *page = bh->b_page;
struct address_space *mapping = NULL;
lock_page_memcg(page);
if (!TestSetPageDirty(page)) {
mapping = page_mapping(page);
if (mapping)
__set_page_dirty(page, mapping, 0);
}
unlock_page_memcg(page);
if (mapping)
__mark_inode_dirty(mapping->host, I_DIRTY_PAGES);
}
}
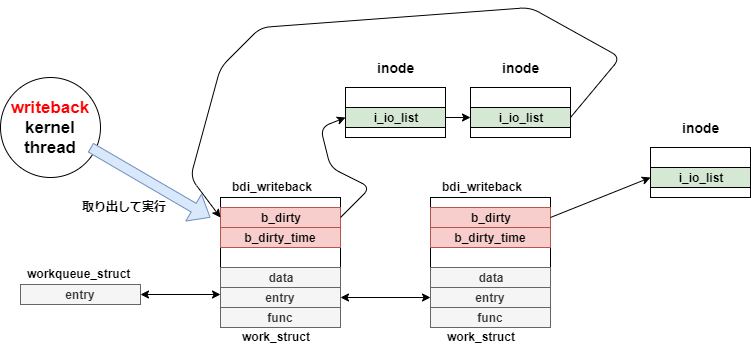
// 2460:/* * If the inode was already on b_dirty/b_io/b_more_io, don't * reposition it (that would break b_dirty time-ordering). */if (!was_dirty) {
...
// 2178:/* * No need to use i_size_read() here, the i_size cannot change under us * because we hold i_rwsem. * * But it's important to update i_size while still holding page lock: * page writeout could otherwise come in and zero beyond i_size. */if (pos + copied > inode->i_size) {
i_size_write(inode, pos + copied);
i_size_changed = true;
}
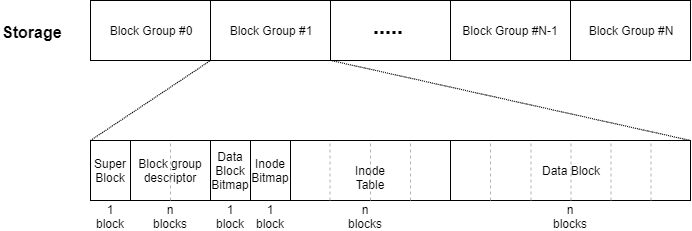
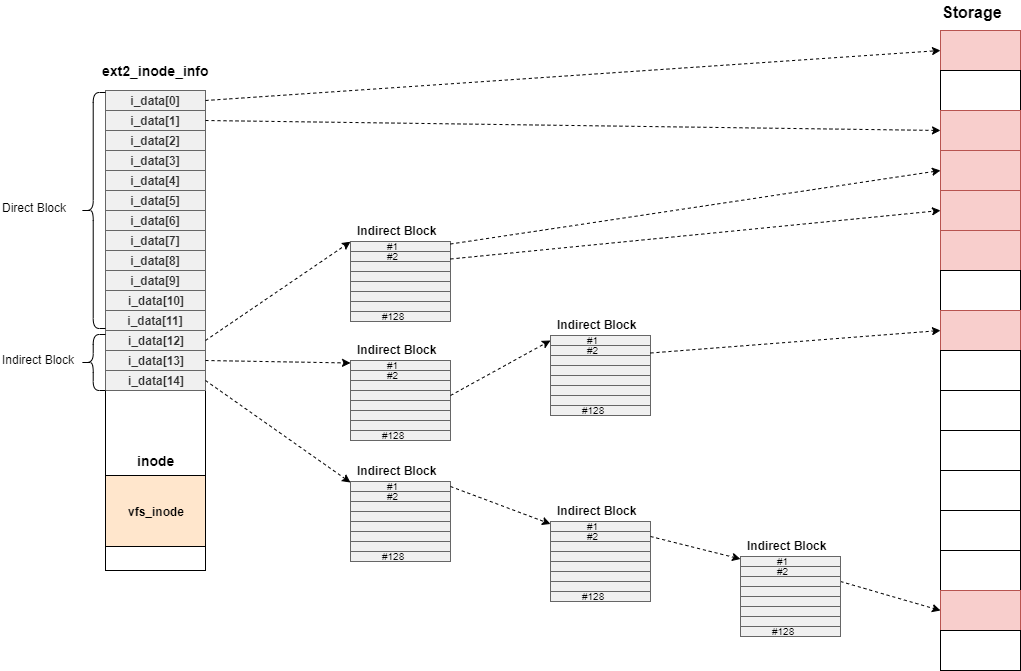
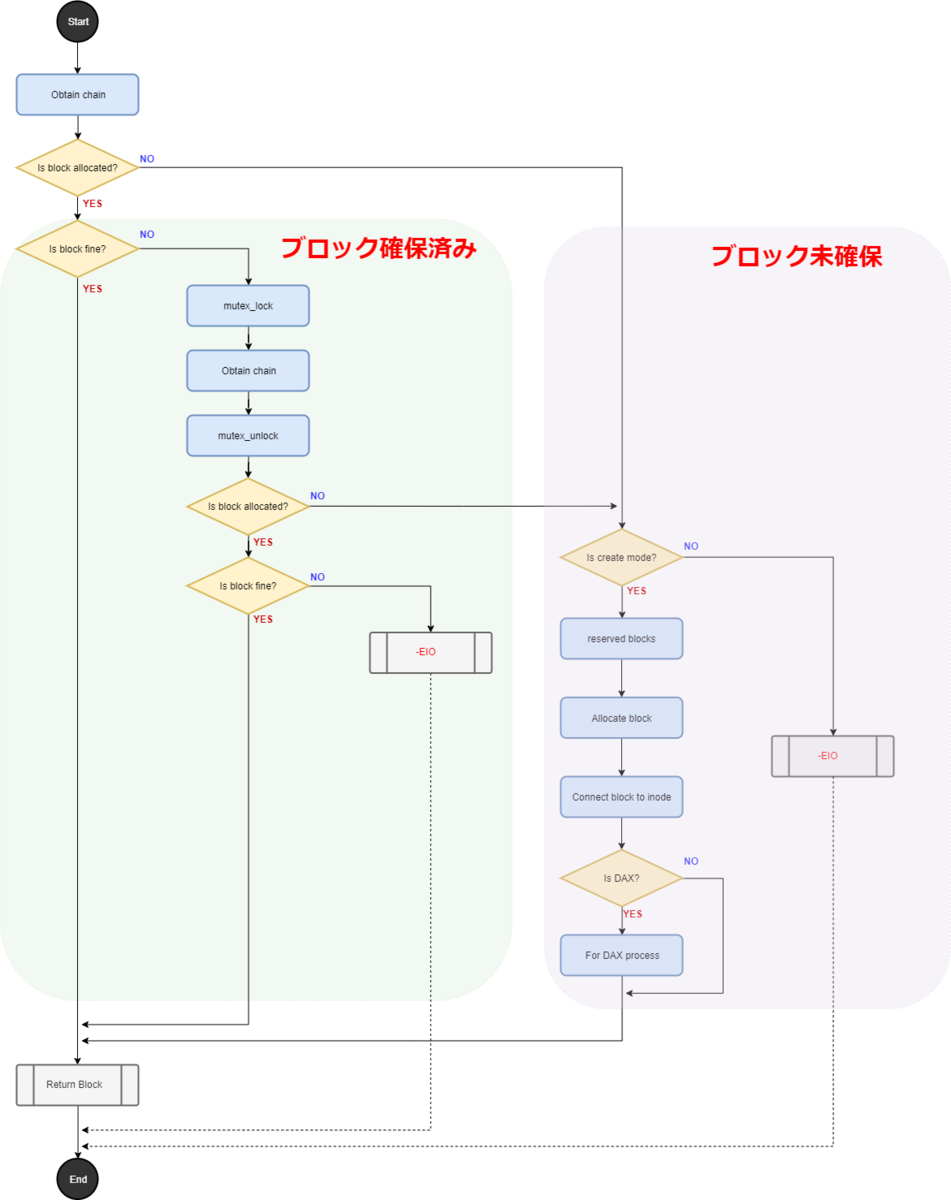
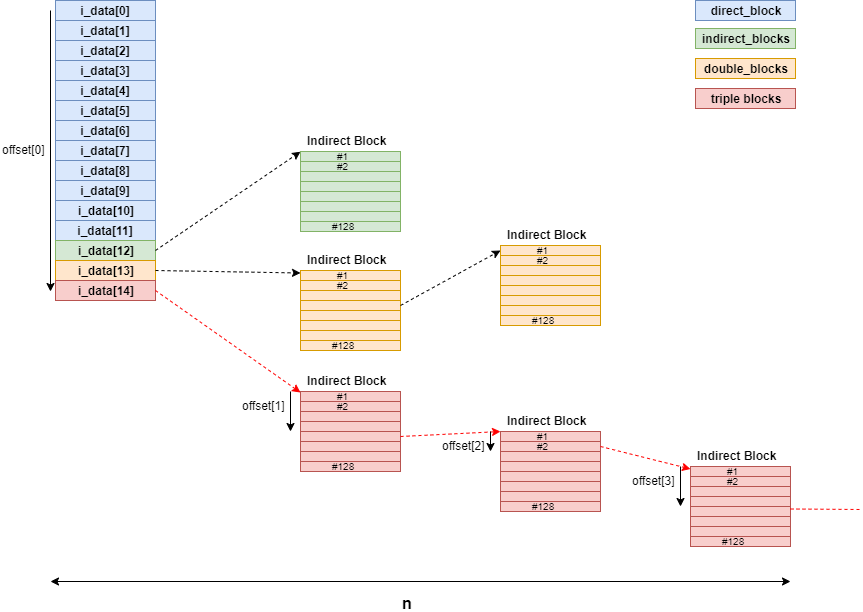
// 620:staticintext2_get_blocks(struct inode *inode,
sector_t iblock, unsignedlong maxblocks,
u32 *bno, bool *new, bool *boundary,
int create)
{
int err;
int offsets[4];
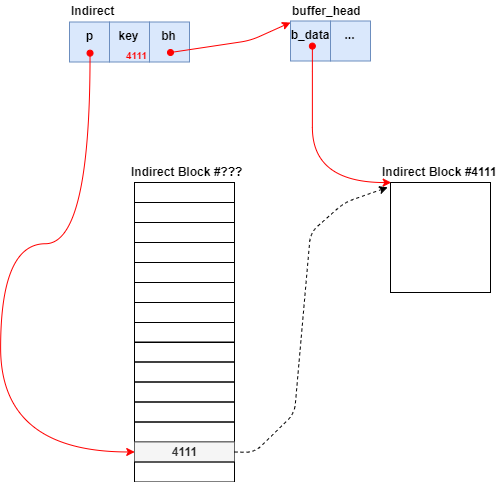
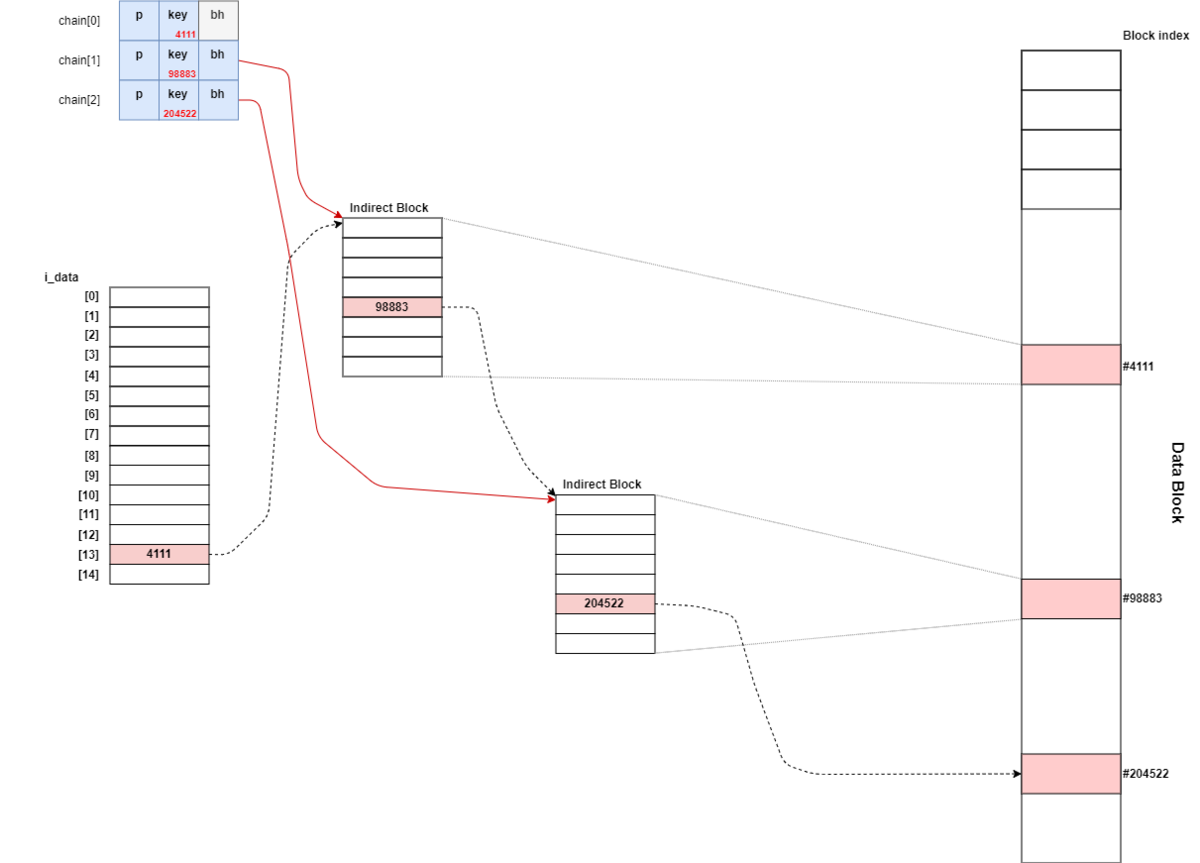
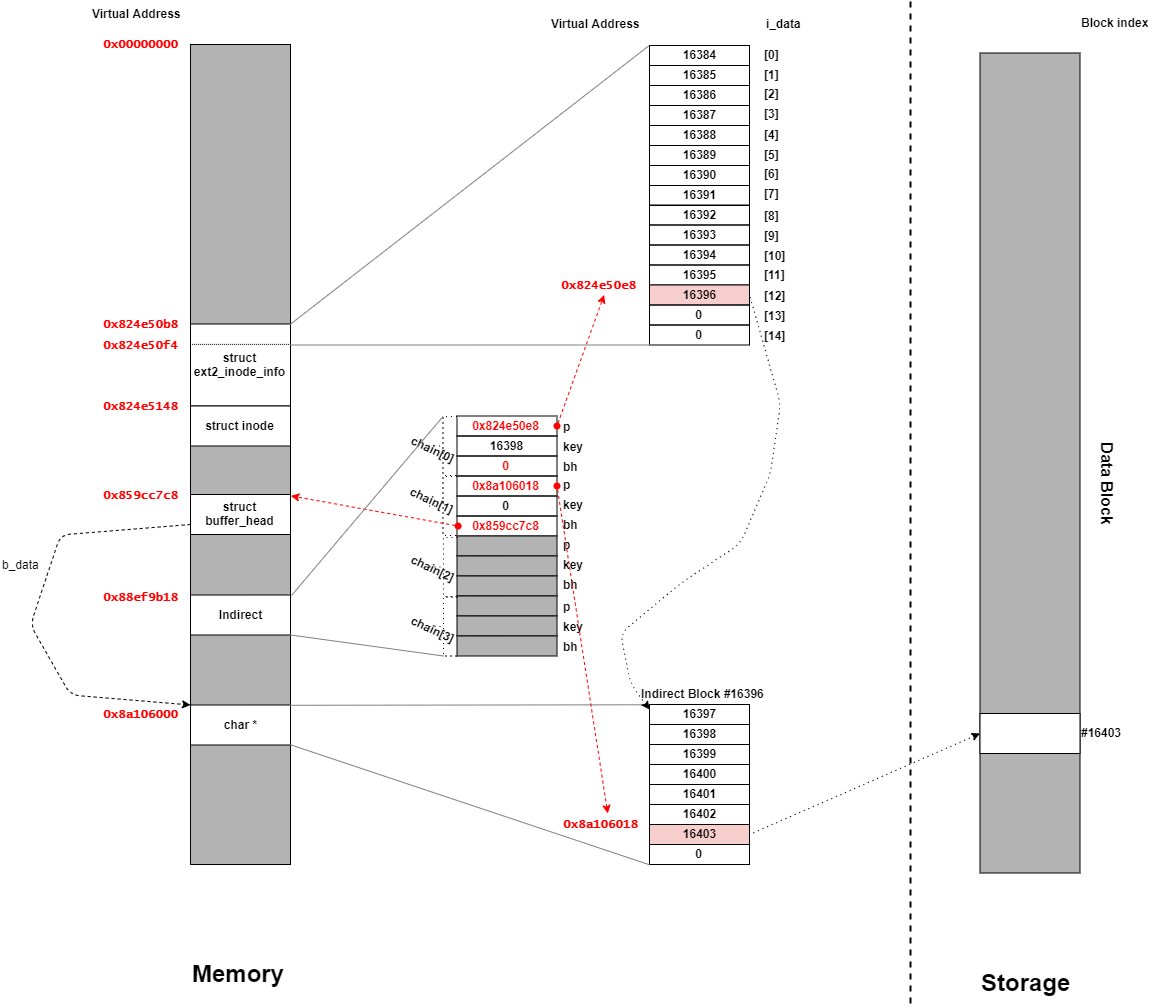
Indirect chain[4];
Indirect *partial;
ext2_fsblk_t goal;
int indirect_blks;
int blocks_to_boundary = 0;
int depth;
struct ext2_inode_info *ei = EXT2_I(inode);
int count = 0;
ext2_fsblk_t first_block = 0;
BUG_ON(maxblocks == 0);
depth = ext2_block_to_path(inode,iblock,offsets,&blocks_to_boundary);
if (depth == 0)
return -EIO;
partial = ext2_get_branch(inode, depth, offsets, chain, &err);
/* Simplest case - block found, no allocation needed */if (!partial) {
first_block = le32_to_cpu(chain[depth - 1].key);
count++;
/*map more blocks*/while (count < maxblocks && count <= blocks_to_boundary) {
ext2_fsblk_t blk;
if (!verify_chain(chain, chain + depth - 1)) {
/* * Indirect block might be removed by * truncate while we were reading it. * Handling of that case: forget what we've * got now, go to reread. */
err = -EAGAIN;
count = 0;
partial = chain + depth - 1;
break;
}
blk = le32_to_cpu(*(chain[depth-1].p + count));
if (blk == first_block + count)
count++;
elsebreak;
}
if (err != -EAGAIN)
goto got_it;
}
/* Next simple case - plain lookup or failed read of indirect block */if (!create || err == -EIO)
goto cleanup;
mutex_lock(&ei->truncate_mutex);
/* * If the indirect block is missing while we are reading * the chain(ext2_get_branch() returns -EAGAIN err), or * if the chain has been changed after we grab the semaphore, * (either because another process truncated this branch, or * another get_block allocated this branch) re-grab the chain to see if * the request block has been allocated or not. * * Since we already block the truncate/other get_block * at this point, we will have the current copy of the chain when we * splice the branch into the tree. */if (err == -EAGAIN || !verify_chain(chain, partial)) {
while (partial > chain) {
brelse(partial->bh);
partial--;
}
partial = ext2_get_branch(inode, depth, offsets, chain, &err);
if (!partial) {
count++;
mutex_unlock(&ei->truncate_mutex);
goto got_it;
}
if (err) {
mutex_unlock(&ei->truncate_mutex);
goto cleanup;
}
}
/* * Okay, we need to do block allocation. Lazily initialize the block * allocation info here if necessary */if (S_ISREG(inode->i_mode) && (!ei->i_block_alloc_info))
ext2_init_block_alloc_info(inode);
goal = ext2_find_goal(inode, iblock, partial);
/* the number of blocks need to allocate for [d,t]indirect blocks */
indirect_blks = (chain + depth) - partial - 1;
/* * Next look up the indirect map to count the total number of * direct blocks to allocate for this branch. */
count = ext2_blks_to_allocate(partial, indirect_blks,
maxblocks, blocks_to_boundary);
/* * XXX ???? Block out ext2_truncate while we alter the tree */
err = ext2_alloc_branch(inode, indirect_blks, &count, goal,
offsets + (partial - chain), partial);
if (err) {
mutex_unlock(&ei->truncate_mutex);
goto cleanup;
}
if (IS_DAX(inode)) {
/* * We must unmap blocks before zeroing so that writeback cannot * overwrite zeros with stale data from block device page cache. */clean_bdev_aliases(inode->i_sb->s_bdev,
le32_to_cpu(chain[depth-1].key),
count);
/* * block must be initialised before we put it in the tree * so that it's not found by another thread before it's * initialised */
err = sb_issue_zeroout(inode->i_sb,
le32_to_cpu(chain[depth-1].key), count,
GFP_NOFS);
if (err) {
mutex_unlock(&ei->truncate_mutex);
goto cleanup;
}
}
*new = true;
ext2_splice_branch(inode, iblock, partial, indirect_blks, count);
mutex_unlock(&ei->truncate_mutex);
got_it:
if (count > blocks_to_boundary)
*boundary = true;
err = count;
/* Clean up and exit */
partial = chain + depth - 1; /* the whole chain */cleanup:
while (partial > chain) {
brelse(partial->bh);
partial--;
}
if (err > 0)
*bno = le32_to_cpu(chain[depth-1].key);
return err;
}
// 679:mutex_lock(&ei->truncate_mutex);
/* * If the indirect block is missing while we are reading * the chain(ext2_get_branch() returns -EAGAIN err), or * if the chain has been changed after we grab the semaphore, * (either because another process truncated this branch, or * another get_block allocated this branch) re-grab the chain to see if * the request block has been allocated or not. * * Since we already block the truncate/other get_block * at this point, we will have the current copy of the chain when we * splice the branch into the tree. */if (err == -EAGAIN || !verify_chain(chain, partial)) {
while (partial > chain) {
brelse(partial->bh);
partial--;
}
partial = ext2_get_branch(inode, depth, offsets, chain, &err);
if (!partial) {
count++;
mutex_unlock(&ei->truncate_mutex);
goto got_it;
}
if (err) {
mutex_unlock(&ei->truncate_mutex);
goto cleanup;
}
}
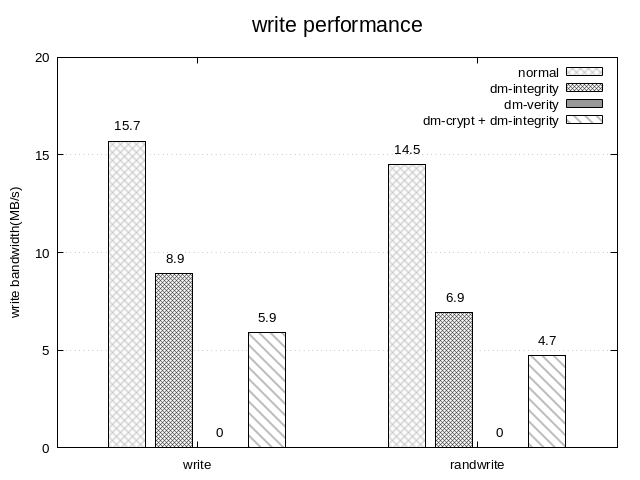
617a618 > # CONFIG_CRYPTO_CRCT10DIF_ARM64_CE is not set735c736,737 < # CONFIG_BLK_DEV_INTEGRITY is not set--- > CONFIG_BLK_DEV_INTEGRITY=y> CONFIG_BLK_DEV_INTEGRITY_T10=y2199c2201,2203< # CONFIG_DM_VERITY is not set---> CONFIG_DM_VERITY=m> # CONFIG_DM_VERITY_VERIFY_ROOTHASH_SIG is not set> # CONFIG_DM_VERITY_FEC is not set2202c2206< # CONFIG_DM_INTEGRITY is not set---> CONFIG_DM_INTEGRITY=m7414c7418< CONFIG_CRYPTO_GF128MUL=m---> CONFIG_CRYPTO_GF128MUL=y7448,7449c7452,7453< # CONFIG_CRYPTO_CFB is not set< CONFIG_CRYPTO_CTR=m---> CONFIG_CRYPTO_CFB=y> CONFIG_CRYPTO_CTR=y7452,7454c7456,7458< # CONFIG_CRYPTO_LRW is not set< # CONFIG_CRYPTO_OFB is not set< # CONFIG_CRYPTO_PCBC is not set---> CONFIG_CRYPTO_LRW=y> CONFIG_CRYPTO_OFB=y> CONFIG_CRYPTO_PCBC=y7476c7480< # CONFIG_CRYPTO_CRCT10DIF is not set---> CONFIG_CRYPTO_CRCT10DIF=y7482,7485c7486,7489< # CONFIG_CRYPTO_RMD128 is not set< # CONFIG_CRYPTO_RMD160 is not set< # CONFIG_CRYPTO_RMD256 is not set< # CONFIG_CRYPTO_RMD320 is not set---> CONFIG_CRYPTO_RMD128=y> CONFIG_CRYPTO_RMD160=y> CONFIG_CRYPTO_RMD256=y> CONFIG_CRYPTO_RMD320=y7487c7491< CONFIG_CRYPTO_SHA256=m---> CONFIG_CRYPTO_SHA256=y7506c7510< # CONFIG_CRYPTO_CAST6 is not set---> CONFIG_CRYPTO_CAST6=m7610c7614< # CONFIG_CRC_T10DIF is not set---> CONFIG_CRC_T10DIF=y
pi@raspberrypi:~ $ sudo mount -t vfat -o ro /dev/mapper/dmtest /mnt/
dm-integrityのみ使用する場合
integrity target用のMapping tableを作成する
pi@raspberrypi:~ $ sudo integritysetup format /dev/sda1
Formatted with tag size 4, internal integrity crc32c.
Wiping device to initialize integrity checksum.
You can interrupt this by pressing CTRL+c (rest of not wiped device will contain invalid checksum).
Finished, time 18:26.389, 8064 MiB written, speed 7.3 MiB/s
device-mapper (/dev/mapper/test)を作成する
pi@raspberrypi:~ $ sudo integritysetup open /dev/sda1 test
作成したintegrity targetを確認する
pi@raspberrypi:~ $ sudo integritysetup status test
/dev/mapper/test is active.
type: INTEGRITY
tag size: 4
integrity: crc32c
device: /dev/sda1
sector size: 512 bytes
interleave sectors: 32768
size: 16516984 sectors
mode: read/write
failures: 0
journal size: 67043328 bytes
journal watermark: 50%
journal commit time: 10000 ms
pi@raspberrypi:~ $ sudo cryptsetup luksFormat --type luks2 /dev/sda1 --cipher aes-xts-plain64 --integrity hmac-sha256
Enter passphrase for /dev/sda1:
Verify passphrase:
Wiping device to initialize integrity checksum.
You can interrupt this by pressing CTRL+c (rest of not wiped device will contain invalid checksum).
Finished, time 33:38.376, 7634 MiB written, speed 3.8 MiB/s
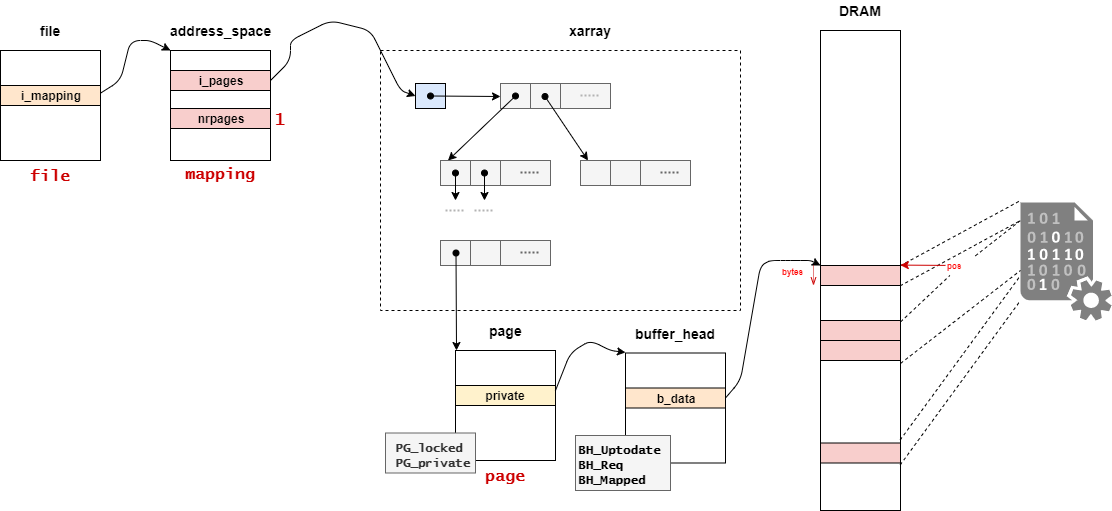
// 3715:/* * Find or create a page at the given pagecache position. Return the locked * page. This function is specifically for buffered writes. */struct page *grab_cache_page_write_begin(struct address_space *mapping,
pgoff_t index, unsigned flags)
{
struct page *page;
int fgp_flags = FGP_LOCK|FGP_WRITE|FGP_CREAT;
if (flags & AOP_FLAG_NOFS)
fgp_flags |= FGP_NOFS;
page = pagecache_get_page(mapping, index, fgp_flags,
mapping_gfp_mask(mapping));
if (page)
wait_for_stable_page(page);
return page;
}
EXPORT_SYMBOL(grab_cache_page_write_begin);
// 1888:struct page *pagecache_get_page(struct address_space *mapping, pgoff_t index,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
page = mapping_get_entry(mapping, index);
if (xa_is_value(page)) {
if (fgp_flags & FGP_ENTRY)
return page;
page = NULL;
}
if (!page)
goto no_page;
if (fgp_flags & FGP_LOCK) {
if (fgp_flags & FGP_NOWAIT) {
if (!trylock_page(page)) {
put_page(page);
returnNULL;
}
} else {
lock_page(page);
}
/* Has the page been truncated? */if (unlikely(page->mapping != mapping)) {
unlock_page(page);
put_page(page);
goto repeat;
}
VM_BUG_ON_PAGE(!thp_contains(page, index), page);
}
if (fgp_flags & FGP_ACCESSED)
mark_page_accessed(page);
elseif (fgp_flags & FGP_WRITE) {
/* Clear idle flag for buffer write */if (page_is_idle(page))
clear_page_idle(page);
}
if (!(fgp_flags & FGP_HEAD))
page = find_subpage(page, index);
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
int err;
if ((fgp_flags & FGP_WRITE) && mapping_can_writeback(mapping))
gfp_mask |= __GFP_WRITE;
if (fgp_flags & FGP_NOFS)
gfp_mask &= ~__GFP_FS;
page = __page_cache_alloc(gfp_mask);
if (!page)
returnNULL;
if (WARN_ON_ONCE(!(fgp_flags & (FGP_LOCK | FGP_FOR_MMAP))))
fgp_flags |= FGP_LOCK;
/* Init accessed so avoid atomic mark_page_accessed later */if (fgp_flags & FGP_ACCESSED)
__SetPageReferenced(page);
err = add_to_page_cache_lru(page, mapping, index, gfp_mask);
if (unlikely(err)) {
put_page(page);
page = NULL;
if (err == -EEXIST)
goto repeat;
}
/* * add_to_page_cache_lru locks the page, and for mmap we expect * an unlocked page. */if (page && (fgp_flags & FGP_FOR_MMAP))
unlock_page(page);
}
return page;
}
まずは、mapping_get_entry関数の定義を確認する。
// 1817:staticstruct page *mapping_get_entry(struct address_space *mapping,
pgoff_t index)
{
XA_STATE(xas, &mapping->i_pages, index);
struct page *page;
rcu_read_lock();
repeat:
xas_reset(&xas);
page = xas_load(&xas);
if (xas_retry(&xas, page))
goto repeat;
/* * A shadow entry of a recently evicted page, or a swap entry from * shmem/tmpfs. Return it without attempting to raise page count. */if (!page || xa_is_value(page))
goto out;
if (!page_cache_get_speculative(page))
goto repeat;
/* * Has the page moved or been split? * This is part of the lockless pagecache protocol. See * include/linux/pagemap.h for details. */if (unlikely(page != xas_reload(&xas))) {
put_page(page);
goto repeat;
}
out:
rcu_read_unlock();
return page;
}
// 977:intadd_to_page_cache_lru(struct page *page, struct address_space *mapping,
pgoff_t offset, gfp_t gfp_mask)
{
void *shadow = NULL;
int ret;
__SetPageLocked(page);
ret = __add_to_page_cache_locked(page, mapping, offset,
gfp_mask, &shadow);
if (unlikely(ret))
__ClearPageLocked(page);
else {
/* * The page might have been evicted from cache only * recently, in which case it should be activated like * any other repeatedly accessed page. * The exception is pages getting rewritten; evicting other * data from the working set, only to cache data that will * get overwritten with something else, is a waste of memory. */WARN_ON_ONCE(PageActive(page));
if (!(gfp_mask & __GFP_WRITE) && shadow)
workingset_refault(page, shadow);
lru_cache_add(page);
}
return ret;
}