関連記事
- Part 1: 環境セットアップ
- Part 2: System call Interface
- Part 3: VFS
- Part 4: ext2 (1) write_iter
- Part 5: ext2 (2) write_begin
- Part 6: ext2 (3) get_block
- Part 7: ext2 (4) write_end
- Part 8: writeback (1) work Queue
- Part 9: writeback (2) wb_writeback
- Part 10: writeback (3) writepages
- Part 11: writeback (4) write_inode
- Part 12: block (1) submit_bio
- Part 13: block (2) blk_mq
- Part 14: I/O scheduler (1) mq-deadline
- Part 15: I/O scheduler (2) insert_request
- Part 16: I/O scheduler (3) dispatch_request
- Part 17: block (3) blk_mq_run_work_fn
- Part 18: block (4) block: blk_mq_do_dispatch_sched
- Part 19: MMC (1) initialization
- Part 20: PL181 (1) mmci_probe
- Part 21: MMC (2) mmc_start_host
- Part 22: MMC (3) mmc_rescan
- 概要
- はじめに
- write_iterの概要
- 書き込み前の正当性チェック
- writebackキューに登録する
- 特殊アクセス権を削除する
- ファイルのタイムスタンプを更新する
- ファイルの実データを書きこみ
- ファイルのオフセットを更新する
- おわりに
- 変更履歴
- 参考
概要
QEMUの vexpress-a9 (arm) で Linux 5.15を起動させながら、ファイル書き込みのカーネル処理を確認していく。
本章では、ext2_file_write_iter関数 (generic_file_write_iter関数)を確認した。
はじめに
ユーザプロセスはファイルシステムという機構によって記憶装置上のデータをファイルという形式で書き込み・読み込みすることができる。
本調査では、ユーザプロセスがファイルに書き込み要求を実行したときにLinuxカーネルではどのような処理が実行されるかを読み解いていく。
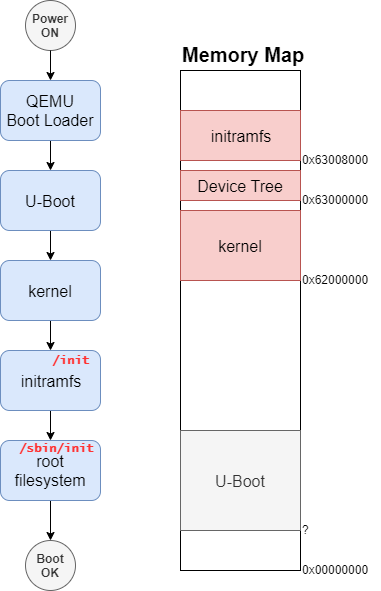
調査対象や環境などはPart 1: 環境セットアップを参照。
本記事では、ext2ファイルシステムのwrite操作を解説する。
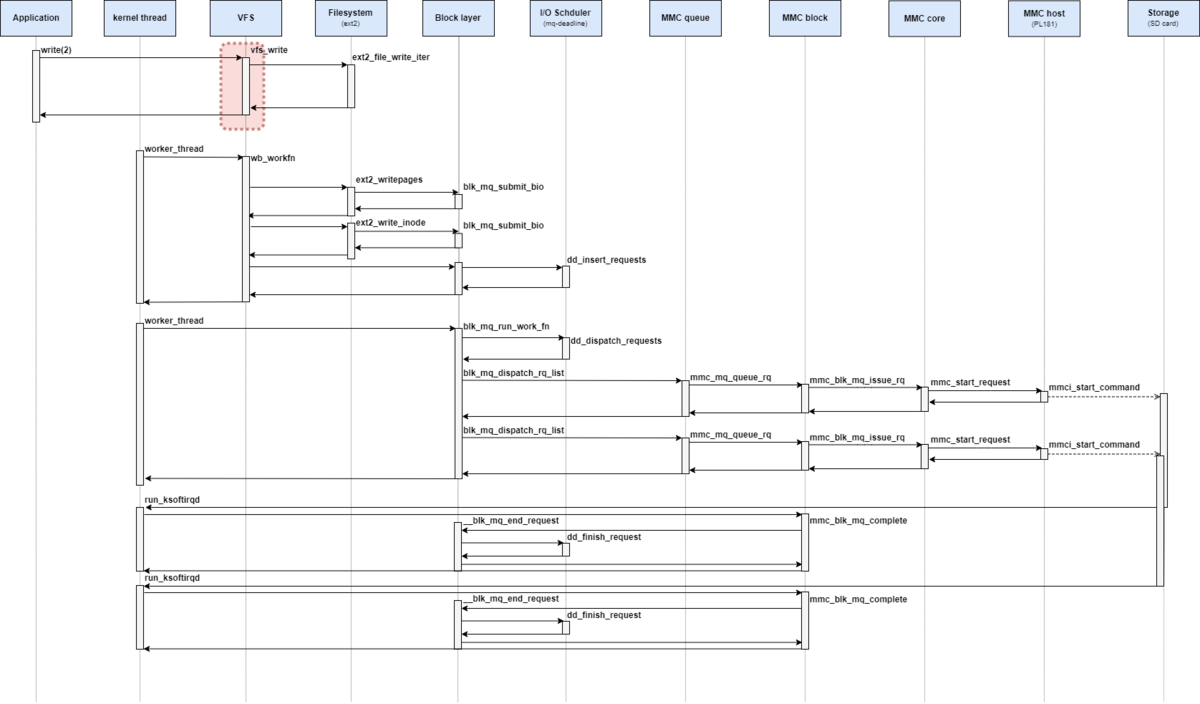
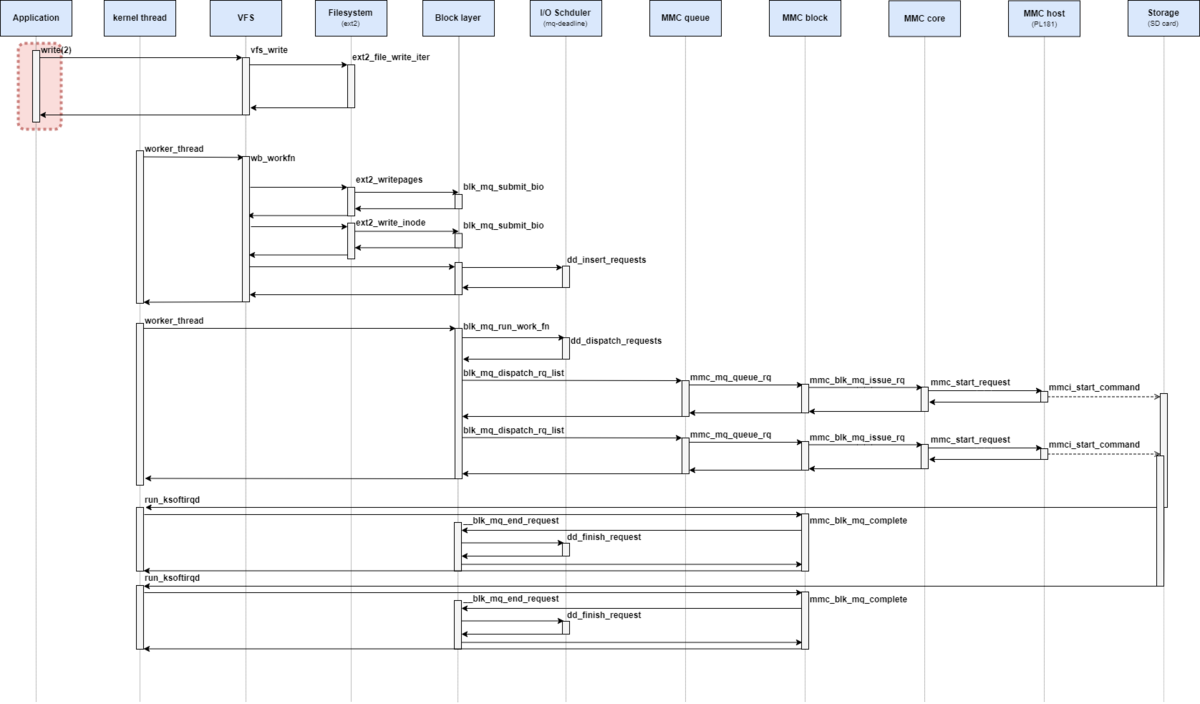
処理シーケンス図としては、下記の赤枠部分が該当する。
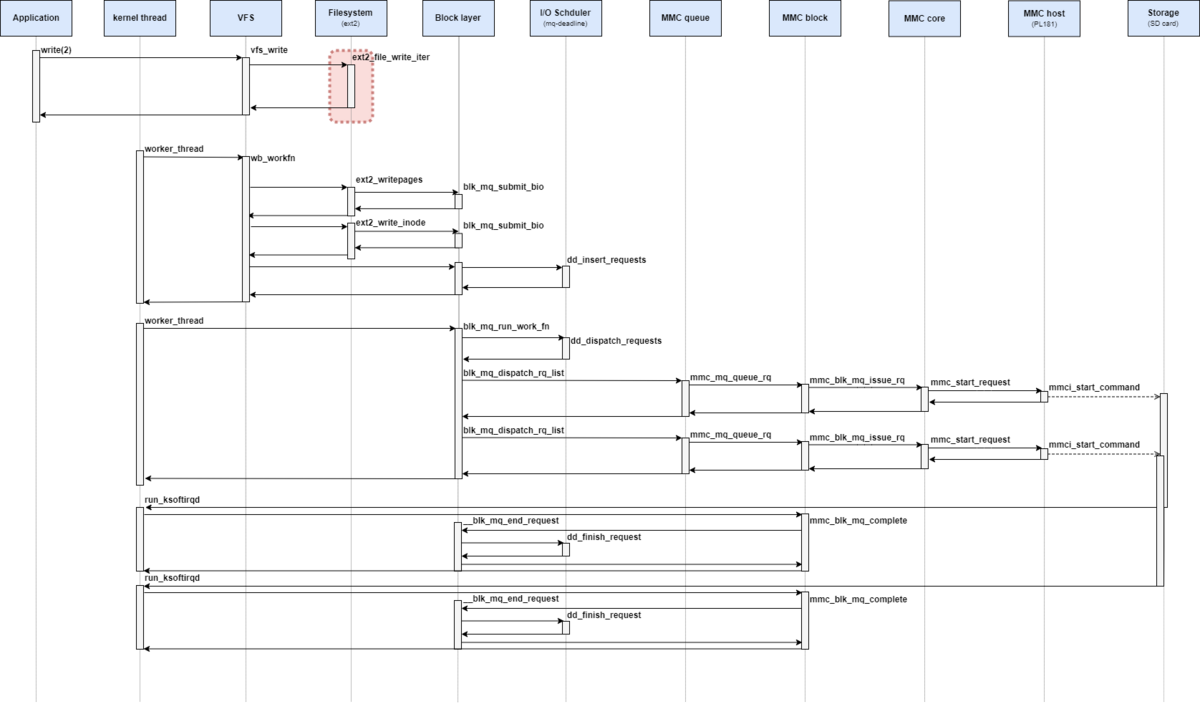
ただし、write_begin操作とwrite_end操作の解説は次回にまわす。
write_iterの概要
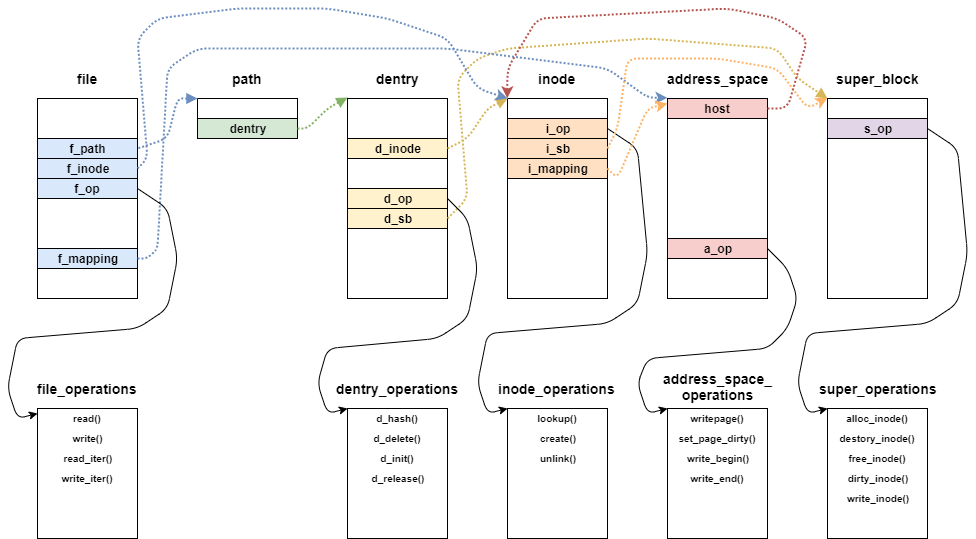
ファイルシステムで定義しているoperationsの種類によって、ファイルアクセスの挙動が異なる。
本調査では、ext2ファイルシステムを対象としているので、ext2のfile_operationsを確認する。
// 182: const struct file_operations ext2_file_operations = { .llseek = generic_file_llseek, .read_iter = ext2_file_read_iter, .write_iter = ext2_file_write_iter, .unlocked_ioctl = ext2_ioctl, #ifdef CONFIG_COMPAT .compat_ioctl = ext2_compat_ioctl, #endif .mmap = ext2_file_mmap, .open = dquot_file_open, .release = ext2_release_file, .fsync = ext2_fsync, .get_unmapped_area = thp_get_unmapped_area, .splice_read = generic_file_splice_read, .splice_write = iter_file_splice_write, };
ext2のfile_operationsは、ext2_file_operations構造体として定義されている。
ext2_file_operations構造体では、write_iterがサポートしている。
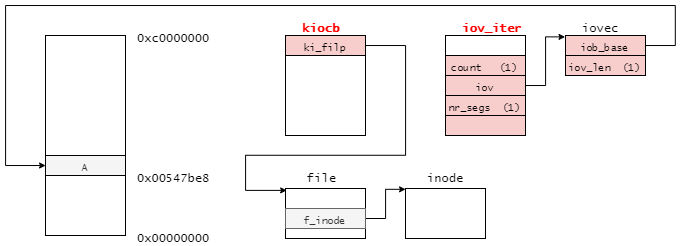
VFSレイヤからwrite_iter操作を呼び出し時に渡す引数を下記に再掲する。
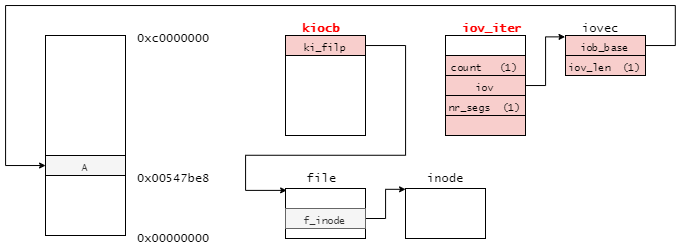
ext2のwrite_iter処理でもあるext2_file_write_iter関数は上記のkiocbとiov_iterを引数にとる。
// 173: static ssize_t ext2_file_write_iter(struct kiocb *iocb, struct iov_iter *from) { #ifdef CONFIG_FS_DAX if (IS_DAX(iocb->ki_filp->f_mapping->host)) return ext2_dax_write_iter(iocb, from); #endif return generic_file_write_iter(iocb, from); }
ext2ファイルシステムでは、Filesystem DAXに対応している。
Filesystem DAXや不揮発メモリ (NVDIMM)については、下記の資料の説明が分かりやすい。
www.slideshare.net
本記事では、Filesystem DAXについては調査対象外とする。
ext2_file_write_iter関数は、generic_file_write_iter関数を呼び出す。
// 3920: ssize_t generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from) { struct file *file = iocb->ki_filp; struct inode *inode = file->f_mapping->host; ssize_t ret; inode_lock(inode); ret = generic_write_checks(iocb, from); if (ret > 0) ret = __generic_file_write_iter(iocb, from); inode_unlock(inode); if (ret > 0) ret = generic_write_sync(iocb, ret); return ret; }
大半のファイルシステムが、ユーザアドレス空間のページキャッシュをカーネル空間にコピーするとページキャッシュにDirtyフラグを立てるという決められた操作をする。
generic_file_write_iter関数は、そのようなファイルシステムに対して汎用的に使えるようにLinuxカーネルでそういった処理を定義している。
ここで、generic_file_write_iter関数の流れを確認する。
大まかな流れを下記に記す。
- inodeに対応するセマフォ(
i_rwsem)を取得する - 書き込み前の正当性を確認する
- write_iterのメイン操作を実施する
- inodeに対応するセマフォ(
i_rwsem)を解放する O_DSYNCフラグ用の処理を実施する
write_iter操作では、タイムスタンプの更新などによってinode構造体を更新する可能性がある。
このタイミングで別プロセスから読み書きが入るとファイルの整合性が取れなくなってしまう。
そのため、書き込み前の正当性を確認するとrite_iter操作を実施するにinode_lock関数とinode_unlock関数を挿入している。
// 784: static inline void inode_lock(struct inode *inode) { down_write(&inode->i_rwsem); } static inline void inode_unlock(struct inode *inode) { up_write(&inode->i_rwsem); }
書き込み前の正当性チェック
generic_file_write_iter関数では、まず書き込み前の正当性を確認しなければならない。
generic_write_checks関数は、書き込み前の正当性を確認する。
// 1631: ssize_t generic_write_checks(struct kiocb *iocb, struct iov_iter *from) { struct file *file = iocb->ki_filp; struct inode *inode = file->f_mapping->host; loff_t count; int ret; if (IS_SWAPFILE(inode)) return -ETXTBSY; if (!iov_iter_count(from)) return 0; /* FIXME: this is for backwards compatibility with 2.4 */ if (iocb->ki_flags & IOCB_APPEND) iocb->ki_pos = i_size_read(inode); if ((iocb->ki_flags & IOCB_NOWAIT) && !(iocb->ki_flags & IOCB_DIRECT)) return -EINVAL; count = iov_iter_count(from); ret = generic_write_check_limits(file, iocb->ki_pos, &count); if (ret) return ret; iov_iter_truncate(from, count); return iov_iter_count(from); }
下記は、generic_write_checks関数から変数のチェック部分を抜き出したチャートとなっている。
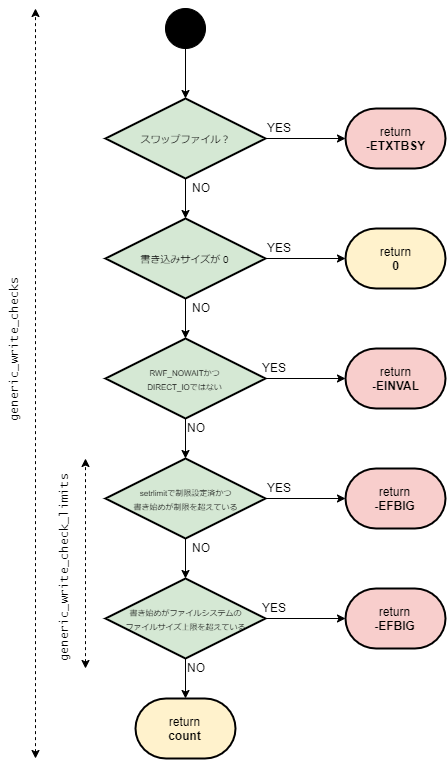
- 書き込み対象がスワップファイルであるか確認する。スワップファイルである場合、positionという概念がないため、汎用的なwrite_iterを実行することができない。その場合、
generic_write_checks関数は-ETXTBSYを返す。 - 書き込みサイズ
countが0であるかどうか確認する。書き込みサイズが0の場合、以降の処理を実行する必要がないため0を返す。 RWF_NOWAITかつ Direct IOではないか確認する。 ノンブロッキングIOのサポートはDirectIOである場合にのみサポートしているため、どちらかが成立することはない。その場合、generic_write_checks関数は-EINVALを返す。setrlimitシステムコールにより資源の制限がされている、かつその値がファイルの書き始めを下回るか確認する。Linuxでは、プロセスの資源利用を制限することができる。設定されている場合、開始位置がその値を超えている場合-EFBIGを返す。- ファイルシステムで定義されているファイルサイズの上限値を超えていないか確認する。書き込み開始位置がファイルシステムの上限
inode->i_sb->s_maxbytesを超えている場合、書き込みを続けることができる。その場合、generic_write_checks関数は-EFBIGを返す。
これらのチェックにより、書き込み前の正当性が確認できた場合は、書き込みサイズcountを返す。
呼び出し元のgeneric_file_write_iter関数は、この返り値が0より大きい場合にwrite処理を続行する。
また、generic_write_checks関数では、O_APPENDフラグが立っているときに変数ki_posを更新する。
(コメントを読む限り、この処理は version 2.4の後方互換性のためだけの処理らしい)
O_APPENDフラグが立っているときに呼び出すi_size_read関数の定義は以下のようになっている。
// 875: static inline loff_t i_size_read(const struct inode *inode) { #if BITS_PER_LONG==32 && defined(CONFIG_SMP) loff_t i_size; unsigned int seq; do { seq = read_seqcount_begin(&inode->i_size_seqcount); i_size = inode->i_size; } while (read_seqcount_retry(&inode->i_size_seqcount, seq)); return i_size; #elif BITS_PER_LONG==32 && defined(CONFIG_PREEMPTION) loff_t i_size; preempt_disable(); i_size = inode->i_size; preempt_enable(); return i_size; #else return inode->i_size; #endif }
i_size_read関数は、ファイル長を返す関数となっている。
ただし、32bitアーキテクチャの場合には処理が複雑になっている。
これは、読み込み対象のi_sizeがlong long型であるために、一つの命令で値をすべてコピーできないことが要因となっている。
- Symmetric Multiprocessing (SMP) の場合: 同時に他CPUにより更新される恐れがある
- 解決方法:
i_size_seqcountによるカウンタを利用する
- 解決方法:
- プリエンプション有効 の場合: ファイル長を一部読み込み後にプリエンプションにより別タスクが走る恐れがある
- 解決方法: その区間のみプリエンプションを無効にする
generic_write_checks関数を実行し、書き込み先のチェックで問題がなかった場合、__generic_file_write_iter関数を呼び出す。
この関数の定義は以下のようになっている。
// 3832: ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from) { struct file *file = iocb->ki_filp; struct address_space *mapping = file->f_mapping; struct inode *inode = mapping->host; ssize_t written = 0; ssize_t err; ssize_t status; /* We can write back this queue in page reclaim */ current->backing_dev_info = inode_to_bdi(inode); err = file_remove_privs(file); if (err) goto out; err = file_update_time(file); if (err) goto out; if (iocb->ki_flags & IOCB_DIRECT) { loff_t pos, endbyte; written = generic_file_direct_write(iocb, from); /* * If the write stopped short of completing, fall back to * buffered writes. Some filesystems do this for writes to * holes, for example. For DAX files, a buffered write will * not succeed (even if it did, DAX does not handle dirty * page-cache pages correctly). */ if (written < 0 || !iov_iter_count(from) || IS_DAX(inode)) goto out; status = generic_perform_write(file, from, pos = iocb->ki_pos); /* * If generic_perform_write() returned a synchronous error * then we want to return the number of bytes which were * direct-written, or the error code if that was zero. Note * that this differs from normal direct-io semantics, which * will return -EFOO even if some bytes were written. */ if (unlikely(status < 0)) { err = status; goto out; } /* * We need to ensure that the page cache pages are written to * disk and invalidated to preserve the expected O_DIRECT * semantics. */ endbyte = pos + status - 1; err = filemap_write_and_wait_range(mapping, pos, endbyte); if (err == 0) { iocb->ki_pos = endbyte + 1; written += status; invalidate_mapping_pages(mapping, pos >> PAGE_SHIFT, endbyte >> PAGE_SHIFT); } else { /* * We don't know how much we wrote, so just return * the number of bytes which were direct-written */ } } else { written = generic_perform_write(file, from, iocb->ki_pos); if (likely(written > 0)) iocb->ki_pos += written; } out: current->backing_dev_info = NULL; return written ? written : err; }
処理が多くて大変そうに見えるが、この関数にはDirect IOの処理も記載されている。
今回の調査処理 (Buffered IO)の場合は、以下の処理となる。
- writebackキューに、書き込み先のブロックデバイスを追加する
- 特殊アクセス権 (SUID) を削除する
- mtimeのctimeを更新する
- ファイルの実データを書きこみ
- ファイルのオフセットを更新する
それぞれの処理について解説する。
writebackキューに登録する
writebackキューへの登録は、現在のプロセスを表す変数currentのbacking_dev_infoを更新することで達成できる。
ここで、inode_to_bdi関数によって書き込み先のデバイス(今回の場合は/dev/mmcblk0)を取得できる。
これによって、ファイルのデータを/dev/mmcblk0へバックグラウンドで書き出すことができる。
// 136: static inline struct backing_dev_info *inode_to_bdi(struct inode *inode) { struct super_block *sb; if (!inode) return &noop_backing_dev_info; sb = inode->i_sb; #ifdef CONFIG_BLOCK if (sb_is_blkdev_sb(sb)) return I_BDEV(inode)->bd_disk->bdi; #endif return sb->s_bdi; }
本環境においては、I_BDEV(inode)->bd_bdi;を返す。
特殊アクセス権を削除する
特殊アクセス権の削除は、file_remove_privs関数で実現することができる。
ただし、本記事では以降の処理は追いかけない。
// 1936: int file_remove_privs(struct file *file) { struct dentry *dentry = file_dentry(file); struct inode *inode = file_inode(file); int kill; int error = 0; /* * Fast path for nothing security related. * As well for non-regular files, e.g. blkdev inodes. * For example, blkdev_write_iter() might get here * trying to remove privs which it is not allowed to. */ if (IS_NOSEC(inode) || !S_ISREG(inode->i_mode)) return 0; kill = dentry_needs_remove_privs(dentry); if (kill < 0) return kill; if (kill) error = __remove_privs(file_mnt_user_ns(file), dentry, kill); if (!error) inode_has_no_xattr(inode); return error; }
ファイルのタイムスタンプを更新する
file_update_time関数によって、ファイルの書き込みによってタイムスタンプ(ctimeとmtime)の更新する。
関数の定義を下記に示す。
// 1977: int file_update_time(struct file *file) { struct inode *inode = file_inode(file); struct timespec64 now; int sync_it = 0; int ret; /* First try to exhaust all avenues to not sync */ if (IS_NOCMTIME(inode)) return 0; now = current_time(inode); if (!timespec64_equal(&inode->i_mtime, &now)) sync_it = S_MTIME; if (!timespec64_equal(&inode->i_ctime, &now)) sync_it |= S_CTIME; if (IS_I_VERSION(inode) && inode_iversion_need_inc(inode)) sync_it |= S_VERSION; if (!sync_it) return 0; /* Finally allowed to write? Takes lock. */ if (__mnt_want_write_file(file)) return 0; ret = update_time(inode, &now, sync_it); __mnt_drop_write_file(file); return ret; }
S_NOCMTIMEフラグを指定した場合、タイムスタンプを更新しない。- ファイルのmtimeが現在時刻より古い場合、
update_time関数に渡すパラメータを更新する。 - ファイルのctimeが現在時刻より古い場合、
update_time関数に渡すパラメータを更新する。 - ファイルシステムが
i_versionをサポートしているかどうか、またファイルのi_versionをインクリメントする必要がある場合、update_time関数に渡すパラメータを更新する。 - ファイルシステムが書き込み可能な状態であるかどうかチェックする。書き込み可能な状態である場合、使用カウントを増やす。
update_time関数のメイン処理を実行する。- 書き込み可能な状態である場合、使用カウントを減らす。
今回のwriteの処理では、ctimeとmtimeが現在時刻より古いため、S_CTIMEとS_MTIMEが付与される。
update_time関数のメイン処理を実行する。
関数の定義を下記に示す。
// 1785: static int update_time(struct inode *inode, struct timespec64 *time, int flags) { if (inode->i_op->update_time) return inode->i_op->update_time(inode, time, flags); return generic_update_time(inode, time, flags); }
update_time関数では、ファイルシステムの独自のupdate_timeがサポートされているかどうかを実行する。
// 199: const struct inode_operations ext2_file_inode_operations = { .listxattr = ext2_listxattr, .getattr = ext2_getattr, .setattr = ext2_setattr, .get_acl = ext2_get_acl, .set_acl = ext2_set_acl, .fiemap = ext2_fiemap, .fileattr_get = ext2_fileattr_get, .fileattr_set = ext2_fileattr_set, };
しかし、ext2ファイルシステムでは、独自のupdate_time操作はサポートしていない。
そのため、汎用的なgeneric_update_time関数を実行する。
// 1755: int generic_update_time(struct inode *inode, struct timespec64 *time, int flags) { int dirty_flags = 0; if (flags & (S_ATIME | S_CTIME | S_MTIME)) { if (flags & S_ATIME) inode->i_atime = *time; if (flags & S_CTIME) inode->i_ctime = *time; if (flags & S_MTIME) inode->i_mtime = *time; if (inode->i_sb->s_flags & SB_LAZYTIME) dirty_flags |= I_DIRTY_TIME; else dirty_flags |= I_DIRTY_SYNC; } if ((flags & S_VERSION) && inode_maybe_inc_iversion(inode, false)) dirty_flags |= I_DIRTY_SYNC; __mark_inode_dirty(inode, dirty_flags); return 0; }
generic_update_time関数では、パラメータに応じてinodeオブジェクトを更新する。
ここでは、inode->i_ctimeとinode->i_mtimeを更新し、__mark_inode_dirty関数でinodeオブジェクトにDirtyフラグを立てる。
この__mark_inode_dirty関数は、inodeオブジェクトにDirtyフラグ付ける汎用的な関数であり、さまざまな状態でこの関数が呼ばれる。
update_timeからこの関数の呼び出し時には、下記の状態となっている。
flagsにI_DIRTY_SYNCが設定されているinode->i_stateに0が設定されている
これらに着目して、__mark_inode_dirty関数のフローに注目する。
// 2381: void __mark_inode_dirty(struct inode *inode, int flags) { struct super_block *sb = inode->i_sb; int dirtytime = 0; trace_writeback_mark_inode_dirty(inode, flags); if (flags & I_DIRTY_INODE) { /* * Notify the filesystem about the inode being dirtied, so that * (if needed) it can update on-disk fields and journal the * inode. This is only needed when the inode itself is being * dirtied now. I.e. it's only needed for I_DIRTY_INODE, not * for just I_DIRTY_PAGES or I_DIRTY_TIME. */ trace_writeback_dirty_inode_start(inode, flags); if (sb->s_op->dirty_inode) sb->s_op->dirty_inode(inode, flags & I_DIRTY_INODE); trace_writeback_dirty_inode(inode, flags); /* I_DIRTY_INODE supersedes I_DIRTY_TIME. */ flags &= ~I_DIRTY_TIME; } else { /* * Else it's either I_DIRTY_PAGES, I_DIRTY_TIME, or nothing. * (We don't support setting both I_DIRTY_PAGES and I_DIRTY_TIME * in one call to __mark_inode_dirty().) */ dirtytime = flags & I_DIRTY_TIME; WARN_ON_ONCE(dirtytime && flags != I_DIRTY_TIME); } /* * Paired with smp_mb() in __writeback_single_inode() for the * following lockless i_state test. See there for details. */ smp_mb(); if (((inode->i_state & flags) == flags) || (dirtytime && (inode->i_state & I_DIRTY_INODE))) return; spin_lock(&inode->i_lock); if (dirtytime && (inode->i_state & I_DIRTY_INODE)) goto out_unlock_inode; if ((inode->i_state & flags) != flags) { const int was_dirty = inode->i_state & I_DIRTY; inode_attach_wb(inode, NULL); /* I_DIRTY_INODE supersedes I_DIRTY_TIME. */ if (flags & I_DIRTY_INODE) inode->i_state &= ~I_DIRTY_TIME; inode->i_state |= flags; /* * If the inode is queued for writeback by flush worker, just * update its dirty state. Once the flush worker is done with * the inode it will place it on the appropriate superblock * list, based upon its state. */ if (inode->i_state & I_SYNC_QUEUED) goto out_unlock_inode; /* * Only add valid (hashed) inodes to the superblock's * dirty list. Add blockdev inodes as well. */ if (!S_ISBLK(inode->i_mode)) { if (inode_unhashed(inode)) goto out_unlock_inode; } if (inode->i_state & I_FREEING) goto out_unlock_inode; /* * If the inode was already on b_dirty/b_io/b_more_io, don't * reposition it (that would break b_dirty time-ordering). */ if (!was_dirty) { struct bdi_writeback *wb; struct list_head *dirty_list; bool wakeup_bdi = false; wb = locked_inode_to_wb_and_lock_list(inode); inode->dirtied_when = jiffies; if (dirtytime) inode->dirtied_time_when = jiffies; if (inode->i_state & I_DIRTY) dirty_list = &wb->b_dirty; else dirty_list = &wb->b_dirty_time; wakeup_bdi = inode_io_list_move_locked(inode, wb, dirty_list); spin_unlock(&wb->list_lock); trace_writeback_dirty_inode_enqueue(inode); /* * If this is the first dirty inode for this bdi, * we have to wake-up the corresponding bdi thread * to make sure background write-back happens * later. */ if (wakeup_bdi && (wb->bdi->capabilities & BDI_CAP_WRITEBACK)) wb_wakeup_delayed(wb); return; } } out_unlock_inode: spin_unlock(&inode->i_lock); }
__mark_inode_dirty関数の処理を簡潔にまとめると下記の処理となる。
- inodeオブジェクトのロックを取得する
- inodeオブジェクトのフラグを更新する
- inodeオブジェクトからbdi_writebackオブジェクトを取得する
- inodeオブジェクトのロックを解放する
- inodeオブジェクトにDirtyになった時刻を更新する
- bdi_writebackオブジェクトのDirtyリストにinodeオブジェクトを追加する
- 必要に応じて、bdi_writebackオブジェクトに対応するwritebackスレッドを起床させる
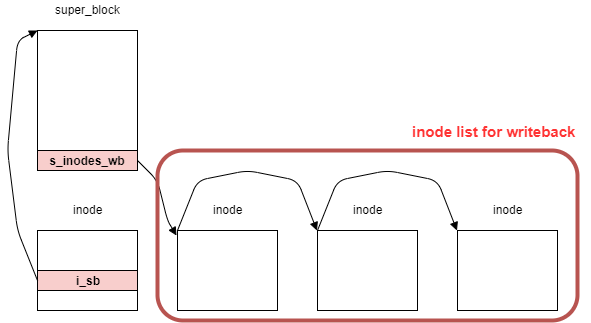
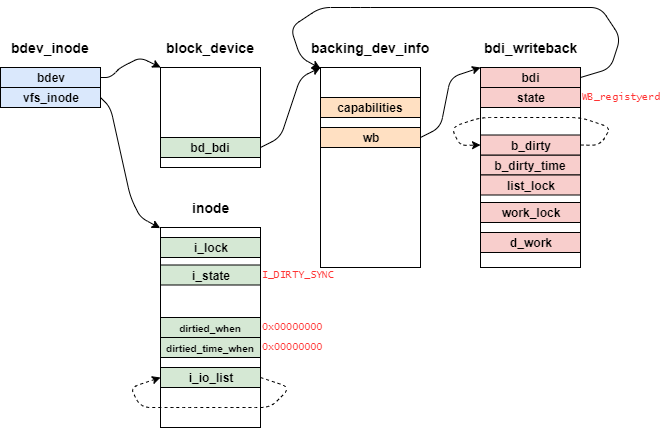
また、この関数呼び出し初期のオブジェクトの関係性を下記に示す。

bdev_inode構造体は仮引数inodeからポイントされ、後述するcontainer_ofマクロによって取得できる。
また、bdi_writeback構造体のstateは、マウント直後の場合、いくつかのフラグ(WB_has_dirty_io)がセットされている。
ここから、__mark_inode_dirty関数の流れを図を用いつつ解説していく。
初めに、同時にinodeメンバの参照・更新を防ぐためにspin_lockマクロでロックを取る。
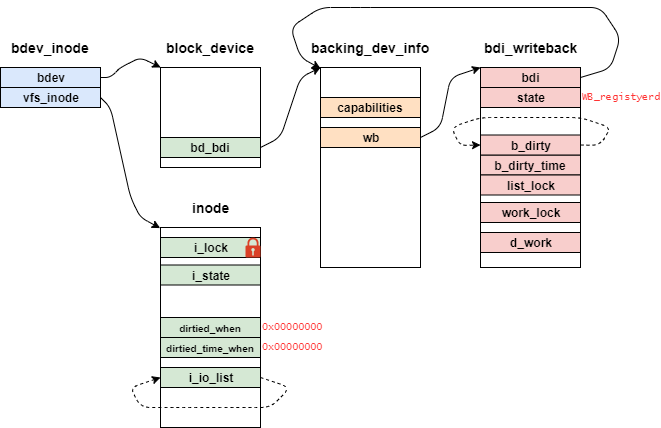
次に、inodeメンバ自体を更新したことを表すI_DIRTY_SYNCフラグを付与する。
タイムスタンプの更新(update_time)によってこの関数が呼ばれているため、このフラグのみとなる。

次に、inodeオブジェクトからbdi_writebackオブジェクトを取得する。
locked_inode_to_wb_and_lock_list関数は、必要なロックの取得・解放とbdi_writebackオブジェクトを取得する。
// 1173: static struct bdi_writeback * locked_inode_to_wb_and_lock_list(struct inode *inode) __releases(&inode->i_lock) __acquires(&wb->list_lock) { struct bdi_writeback *wb = inode_to_wb(inode); spin_unlock(&inode->i_lock); spin_lock(&wb->list_lock); return wb; }
この関数では、型属性として__releasesと__acquiresが付与されている。
__releases: 関数に入る時に該当するロックがあらかじめ取得され、関数から出る時に解放されている__acquires関数に入る時には該当するロックが取得されてなく、関数から出る時に取得される
下記はinode_to_wbインライン関数の実装となっており、backing_dev_info構造体を経由してbdi_writeback構造体を取得する。
// 375: static inline struct bdi_writeback *inode_to_wb(struct inode *inode) { return &inode_to_bdi(inode)->wb; }
これによって、inode構造体からbdev_inode構造体を取得し、bdi_writeback構造体を返すことができる。
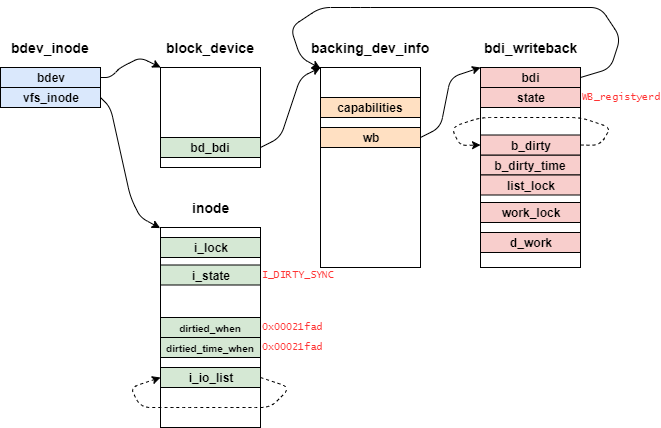
writebackするタイミングを契機を把握するために、inodeオブジェクトにDirtyになった時刻を更新する。
時間変数jiffiesについては、下記のリンクを参照すること。
その後、inode_io_list_move_locked関数でinode構造体にリンクされているDirtyリストをbdi_writeback構造体へ移動させる。
この時、inode構造体の状態によって移動先のリストが異なる。
// 2471: if (inode->i_state & I_DIRTY) dirty_list = &wb->b_dirty; else dirty_list = &wb->b_dirty_time;
I_DIRTYフラグは下記の通りとなっている。
// 2445: #define I_DIRTY_INODE (I_DIRTY_SYNC | I_DIRTY_DATASYNC) #define I_DIRTY (I_DIRTY_INODE | I_DIRTY_PAGES) #define I_DIRTY_ALL (I_DIRTY | I_DIRTY_TIME)
(I_DIRTY_SYNC | I_DIRTY_DATASYNC | I_DIRTY_PAGES)の場合はwb->b_dirtyリストへ、そうでなければwb->b_dirty_timeリストに移動させる。
update_time関数から呼び出される場合、inode構造体の状態はI_DIRTY_SYNCとなっているので、wb->b_dirtyとなる。
これらを踏まえて、inode_io_list_move_locked関数の定義を確認する。
// 118: static bool inode_io_list_move_locked(struct inode *inode, struct bdi_writeback *wb, struct list_head *head) { assert_spin_locked(&wb->list_lock); list_move(&inode->i_io_list, head); /* dirty_time doesn't count as dirty_io until expiration */ if (head != &wb->b_dirty_time) return wb_io_lists_populated(wb); wb_io_lists_depopulated(wb); return false; }
assert_spin_lockedマクロは、引数のwb->list_lockがlock/unlockの準備ができているかどうか確認することができる。
wb->list_lockの場合、デバイスドライバの登録時に初期化される。
list_moveインラインマクロは、list_head構造体が保持しているデータを移し替える。
ここでは、inode->i_io_listとhead(wb->b_dirty)が対象となる。
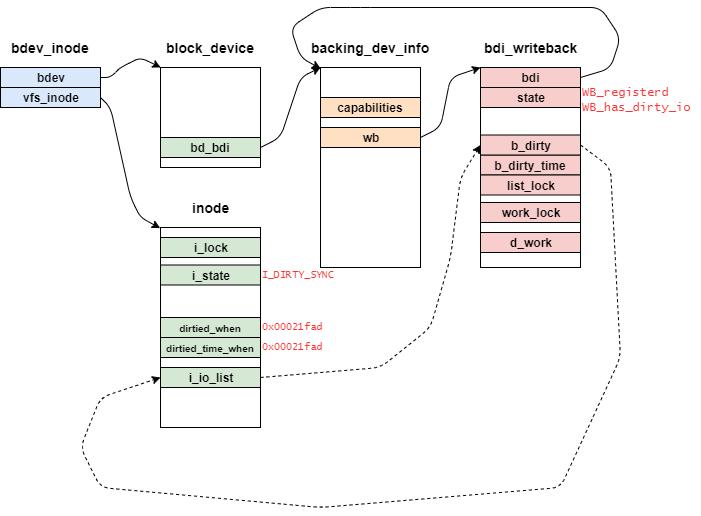
実際には、list_head構造体を通してリストがつながっているが説明の都合上で画像からは省略している。
その後、writeback用のリストをwakeup_delayedさせる必要があるかの確認する。
// 85: static bool wb_io_lists_populated(struct bdi_writeback *wb) { if (wb_has_dirty_io(wb)) { return false; } else { set_bit(WB_has_dirty_io, &wb->state); WARN_ON_ONCE(!wb->avg_write_bandwidth); atomic_long_add(wb->avg_write_bandwidth, &wb->bdi->tot_write_bandwidth); return true; } }
wb_has_dirty_ioインライン関数の結果 (WB_has_dirty_ioのビット値)によって、返す値が異なる。
// 53: static inline bool wb_has_dirty_io(struct bdi_writeback *wb) { return test_bit(WB_has_dirty_io, &wb->state); }
もし、b_dirtyにinodeが既に登録されていた場合には、リストに対して初めてノード追加ではないため、そのまま処理を終了する。
一方で、b_dirtyにinodeが登録されていない場合には、リストに対して初めてのノード追加なので、bdk_writebackにWB_has_dirty_ioをセットし、writebackカーネルスレッドに処理を依頼する必要がある。
// 2476: wakeup_bdi = inode_io_list_move_locked(inode, wb, dirty_list); spin_unlock(&wb->list_lock); trace_writeback_dirty_inode_enqueue(inode); /* * If this is the first dirty inode for this bdi, * we have to wake-up the corresponding bdi thread * to make sure background write-back happens * later. */ if (wakeup_bdi && (wb->bdi->capabilities & BDI_CAP_WRITEBACK)) wb_wakeup_delayed(wb); return;
wb_wakeup_delayed関数は、writeback用のカーネルスレッドにDirtyなファイルがあることを通知する。
こちらの関数は、後ほど (writebackのセクション) 確認する。
ちなみに、処理としては下記の通りとなっている。
// 263: void wb_wakeup_delayed(struct bdi_writeback *wb) { unsigned long timeout; timeout = msecs_to_jiffies(dirty_writeback_interval * 10); spin_lock_bh(&wb->work_lock); if (test_bit(WB_registered, &wb->state)) queue_delayed_work(bdi_wq, &wb->dwork, timeout); spin_unlock_bh(&wb->work_lock); }
ファイルの実データを書きこみ
ファイルのタイムスタンプの更新が完了後、 generic_perform_write関数によってバッファIOを実施する。
// 3733: ssize_t generic_perform_write(struct file *file, struct iov_iter *i, loff_t pos) { struct address_space *mapping = file->f_mapping; const struct address_space_operations *a_ops = mapping->a_ops; long status = 0; ssize_t written = 0; unsigned int flags = 0; do { struct page *page; unsigned long offset; /* Offset into pagecache page */ unsigned long bytes; /* Bytes to write to page */ size_t copied; /* Bytes copied from user */ void *fsdata; offset = (pos & (PAGE_SIZE - 1)); bytes = min_t(unsigned long, PAGE_SIZE - offset, iov_iter_count(i)); again: /* * Bring in the user page that we will copy from _first_. * Otherwise there's a nasty deadlock on copying from the * same page as we're writing to, without it being marked * up-to-date. */ if (unlikely(iov_iter_fault_in_readable(i, bytes))) { status = -EFAULT; break; } if (fatal_signal_pending(current)) { status = -EINTR; break; } status = a_ops->write_begin(file, mapping, pos, bytes, flags, &page, &fsdata); if (unlikely(status < 0)) break; if (mapping_writably_mapped(mapping)) flush_dcache_page(page); copied = copy_page_from_iter_atomic(page, offset, bytes, i); flush_dcache_page(page); status = a_ops->write_end(file, mapping, pos, bytes, copied, page, fsdata); if (unlikely(status != copied)) { iov_iter_revert(i, copied - max(status, 0L)); if (unlikely(status < 0)) break; } cond_resched(); if (unlikely(status == 0)) { /* * A short copy made ->write_end() reject the * thing entirely. Might be memory poisoning * halfway through, might be a race with munmap, * might be severe memory pressure. */ if (copied) bytes = copied; goto again; } pos += status; written += status; balance_dirty_pages_ratelimited(mapping); } while (iov_iter_count(i)); return written ? written : status; }
- ユーザ空間の書き込み対象のページを事前にページフォールトさせる
- シグナルを受信したかどうかチェックする
- 必要なオブジェクトを確保したり、書き込み前の準備をする
- ユーザ空間の書き込み対象のページをカーネル空間にコピーする
- バッファにDirtyフラグを立てる
- プリエンプトポイントを明示
それぞれの処理について確認していく。
「ユーザ空間の書き込み対象のページを事前にページフォールトさせる」に該当するソースコードは下記の部分となる。
// 3754: /* * Bring in the user page that we will copy from _first_. * Otherwise there's a nasty deadlock on copying from the * same page as we're writing to, without it being marked * up-to-date. * * Not only is this an optimisation, but it is also required * to check that the address is actually valid, when atomic * usercopies are used, below. */ if (unlikely(iov_iter_fault_in_readable(i, bytes))) { status = -EFAULT; break; }
この処理を理解するにあたって、コミットメッセージを一部を訳す。
sys_write() を実行する際には、ユーザ空間に書き込み元のバッファ、書き込み対象のファイル用のページが存在する。
その両方が同じ物理ページである場合、デッドロックの可能性があります。
具体的には下記のような処理となる。
つまり、この段階でページフォールトを発生させてデッドロックを防ぐ。
その後、シグナルを受信したかどうかチェックする。
// 3765: if (fatal_signal_pending(current)) { status = -EINTR; break; }
この段階で、SIGKILLかSIGPENDINGが受信していれば終了させる。
以降は、ファイルのデータが一部だけ書き込まれたり、ファイルに不整合が起きるため、このタイミングで行う。
その後、必要なオブジェクトを確保したり、書き込み前の準備をする。
// 3770: status = a_ops->write_begin(file, mapping, pos, bytes, flags, &page, &fsdata); if (unlikely(status < 0)) break;
write_begin関数は各ファイルシステムが定義しており、ページキャッシュの取得など実施している。
この処理はだけでも膨大な量となるので、次の記事にてwrite_endと共に追跡する。
そして、write_begin関数で用意したページキャッシュに対して、ユーザ空間の書き込み対象のページをカーネル空間にコピーする。
// 3775: if (mapping_writably_mapped(mapping)) flush_dcache_page(page); copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes); flush_dcache_page(page);
先にiov_iter_copy_from_user_atomic関数を確認する。
iov_iter_copy_from_user_atomic関数の定義は下記のとおりである。
// 909: size_t copy_page_from_iter_atomic(struct page *page, unsigned offset, size_t bytes, struct iov_iter *i) { char *kaddr = kmap_atomic(page), *p = kaddr + offset; if (unlikely(!page_copy_sane(page, offset, bytes))) { kunmap_atomic(kaddr); return 0; } if (unlikely(iov_iter_is_pipe(i) || iov_iter_is_discard(i))) { kunmap_atomic(kaddr); WARN_ON(1); return 0; } iterate_and_advance(i, bytes, base, len, off, copyin(p + off, base, len), memcpy(p + off, base, len) ) kunmap_atomic(kaddr); return bytes; }
iov_iter_copy_from_user_atomic関数は、ユーザ空間にあるiov_iter構造体のバッファをpage構造体が示す仮想アドレスにコピーする。
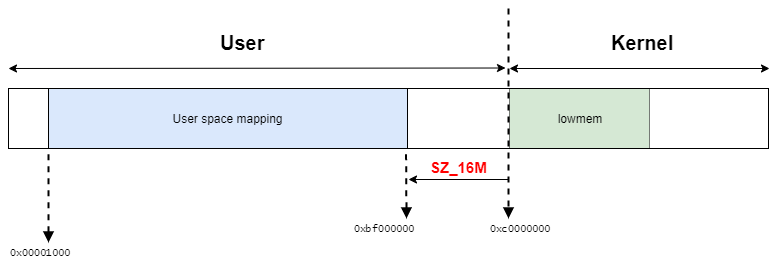
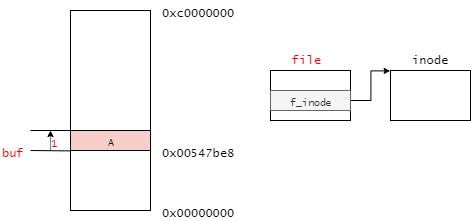
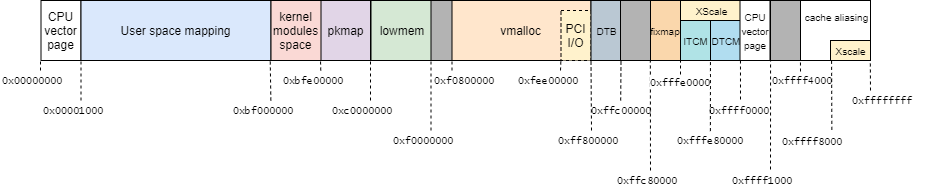
今回使用している環境はCONFIG_FLATMEMとなっているので、page構造体は下記のように配置される。
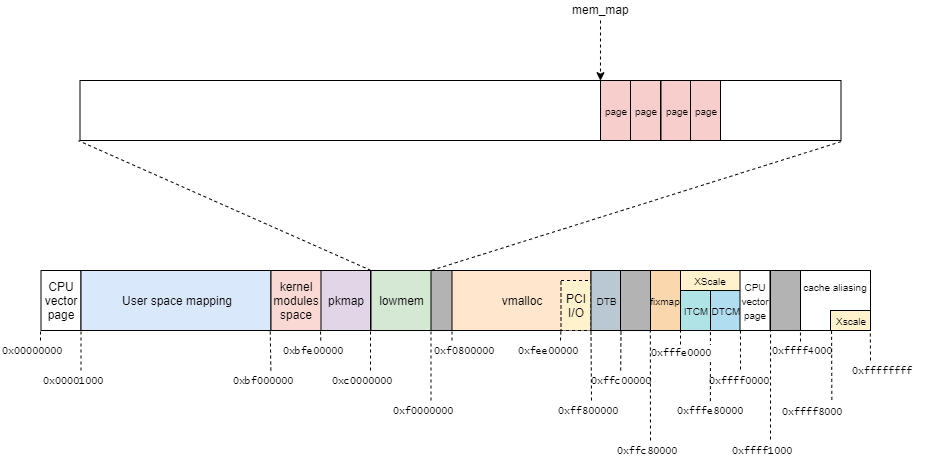
kmap_atomic関数は、page構造体から該当する仮想アドレスを(high memoryに割り当て)仮想アドレスを返す。
似たようなカーネルAPIとしてkmap関数があるが、kmap_atomic関数はsleepされないため割り込みコンテキストで呼ぶことができる。
// 191: static inline void *kmap_atomic(struct page *page) { if (IS_ENABLED(CONFIG_PREEMPT_RT)) migrate_disable(); else preempt_disable(); pagefault_disable(); return page_address(page); }
この環境ではCONFIG_HIGHMEM=nであるため、kmap_atomic関数の実装はそのページに割り当てられている仮想アドレスを返す。
またkmap_atomic関数内では、プリエンプトとページフォールトが無効となっている。(これらの関数の詳細はここでは追わないこととする)
// 1630: #if !defined(HASHED_PAGE_VIRTUAL) && !defined(WANT_PAGE_VIRTUAL) #define page_address(page) lowmem_page_address(page) #define set_page_address(page, address) do { } while(0) #define page_address_init() do { } while(0) #endif
page_addressマクロは条件によって定義が異なるが、この環境ではlowmem_page_addressインライン関数を呼び出す。
// 1603: static __always_inline void *lowmem_page_address(const struct page *page) { return page_to_virt(page); }
lowmem_page_addressインライン関数は、page_to_virtマクロを呼び出す。
// 119: #ifndef page_to_virt #define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x))) #endif
page_to_pfnマクロによって、page構造体からそれに対応するPhysical Frame Number (PFN) を取得する。
// 52: #define page_to_pfn __page_to_pfn #define pfn_to_page __pfn_to_page
__page_to_pfnマクロの実装はLinuxのメモリモデルによって異なる。
この環境では、CONFIG_FLATMEMであるのが下記のような定義となる。
// 12: #if defined(CONFIG_FLATMEM) #ifndef ARCH_PFN_OFFSET #define ARCH_PFN_OFFSET (0UL) #endif #define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET)) #define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + \ ARCH_PFN_OFFSET)
__page_to_pfnマクロは、CONFIG_FLATMEMの場合には、簡単な演算で求めることができる。
(page構造体からmem_mapを引くことによってオフセットを取得して、ARCH_PFN_OFFSET(0x60000)と足す。)
ここで、mem_mep = 0xef7f9000かつpage = 0xeff5e860の場合を考えてみる。
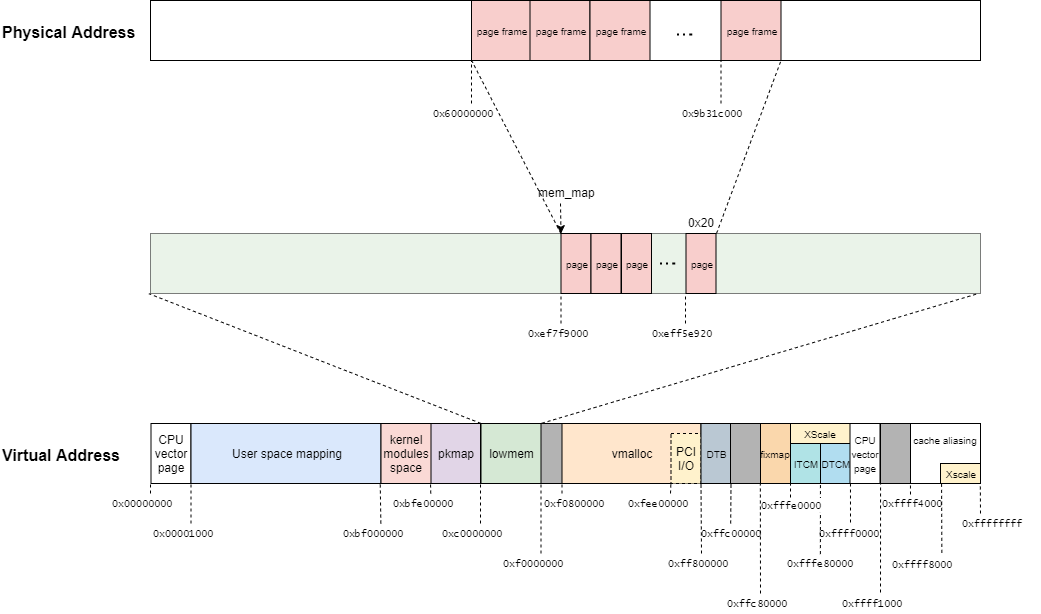
この時、__page_to_pfnマクロの結果として、(0xeff5e860 - 0xef7f9000)/0x20 + 0x0060000の結果で0x0063B2C3となる。
一方で、PFN_PHYSマクロの定義は次の通りとなっている。
// 18: #define PFN_ALIGN(x) (((unsigned long)(x) + (PAGE_SIZE - 1)) & PAGE_MASK) #define PFN_UP(x) (((x) + PAGE_SIZE-1) >> PAGE_SHIFT) #define PFN_DOWN(x) ((x) >> PAGE_SHIFT) #define PFN_PHYS(x) ((phys_addr_t)(x) << PAGE_SHIFT) #define PHYS_PFN(x) ((unsigned long)((x) >> PAGE_SHIFT))
Physical Frame Number にPAGE_SHIFT(12)を左ビットシフトすることで物理アドレスを取得できる。
// 323: /* * Drivers should NOT use these either. */ #define __pa(x) __virt_to_phys((unsigned long)(x)) #define __pa_symbol(x) __phys_addr_symbol(RELOC_HIDE((unsigned long)(x), 0)) #define __va(x) ((void *)__phys_to_virt((phys_addr_t)(x))) #define pfn_to_kaddr(pfn) __va((phys_addr_t)(pfn) << PAGE_SHIFT)
__vaマクロは、引数に渡した物理アドレスから対応する仮想アドレスを返す関数 (__phys_addr_t関数) を返す。
// 260: static inline unsigned long __phys_to_virt(phys_addr_t x) { unsigned long t; /* * 'unsigned long' cast discard upper word when * phys_addr_t is 64 bit, and makes sure that inline * assembler expression receives 32 bit argument * in place where 'r' 32 bit operand is expected. */ __pv_stub((unsigned long) x, t, "sub"); return t; }
ここまで、kmap_atomic関数によって仮想アドレスを取得できたので、サニティーチェックをした後にコピーを始める。
コピーには、iterate_and_advanceマクロに対してcopyin関数、memcpy関数を渡すことで達成できる。
// 148: #define iterate_and_advance(i, n, base, len, off, I, K) \ __iterate_and_advance(i, n, base, len, off, I, ((void)(K),0))
// 111: #define __iterate_and_advance(i, n, base, len, off, I, K) { \ if (unlikely(i->count < n)) \ n = i->count; \ if (likely(n)) { \ if (likely(iter_is_iovec(i))) { \ const struct iovec *iov = i->iov; \ void __user *base; \ size_t len; \ iterate_iovec(i, n, base, len, off, \ iov, (I)) \ i->nr_segs -= iov - i->iov; \ i->iov = iov; \ } else if (iov_iter_is_bvec(i)) { \ const struct bio_vec *bvec = i->bvec; \ void *base; \ size_t len; \ iterate_bvec(i, n, base, len, off, \ bvec, (K)) \ i->nr_segs -= bvec - i->bvec; \ i->bvec = bvec; \ } else if (iov_iter_is_kvec(i)) { \ const struct kvec *kvec = i->kvec; \ void *base; \ size_t len; \ iterate_iovec(i, n, base, len, off, \ kvec, (K)) \ i->nr_segs -= kvec - i->kvec; \ i->kvec = kvec; \ } else if (iov_iter_is_xarray(i)) { \ void *base; \ size_t len; \ iterate_xarray(i, n, base, len, off, \ (K)) \ } \ i->count -= n; \ } \ }
対象がITER_IOVECなので、iterate_iovecマクロでI(memcpy関数)を実行する。
iterate_iovecマクロはiov_iter構造体で指し示すそれぞれのデータに対して、引数のI処理を実行する。
これにより、ページフレームに書き込み用のデータをコピーすることができたのでkunmap関数を実行して、ページフレームを開放する。
// 3775: if (mapping_writably_mapped(mapping)) flush_dcache_page(page); copied = copy_page_from_iter_atomic(page, offset, bytes, i); flush_dcache_page(page);
一方で、iov_iter_copy_from_user_atomic関数の前後でflush_dcache_page関数を実行する。
ここから、flush_dcache_page関数について処理を追っていく。
iov_iter_copy_from_user_atomic関数の直前で、mapping_writably_mapped関数でチェックが入る。
mapping_writably_mapped関数は下記のような定義となっている。
// 551: static inline int mapping_writably_mapped(struct address_space *mapping) { return atomic_read(&mapping->i_mmap_writable) > 0; }
ここで、該当するページが共有されている場合 (mmapでMAP_SHAREDを指定した場合など)は、mapping->i_mmap_writebleが1以上となる。
この後はflush_dcache_page関数を実行するのだが、その前にCPU Cacheについておさらいする。
今回使用しているボードに搭載しているCortex-A9のデータは、Documentation – Arm DeveloperのCortex-Aシリーズのキャッシュ機能についてまとめられている。
| Item | Description |
|---|---|
| L2 Cache | External |
| Cache Implementation (Data) | PIPT |
| Cache Implementation (Inst) | VIPT |
| L1 Cache size (Data) | 16KB/32KB/64KB |
| L1 Cache size (Inst) | 16KB/32KB/64KB |
| L1 Cache Structure | 4-way set associcative (Inst, Data) |
| Cache line (words) | 8 |
| Cache line (bytes) | 32 |
ここから、データキャッシュはPIPT方式で命令キャッシュはVIPT方式が採用されていることがわかる。

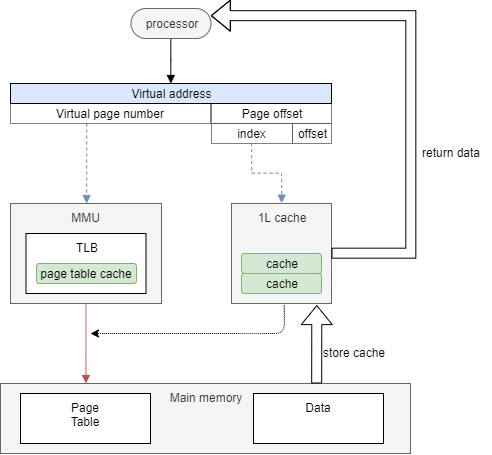
これらを踏まえてflush_dcache_page関数を確認する。
// 296: /* * Ensure cache coherency between kernel mapping and userspace mapping * of this page. * * We have three cases to consider: * - VIPT non-aliasing cache: fully coherent so nothing required. * - VIVT: fully aliasing, so we need to handle every alias in our * current VM view. * - VIPT aliasing: need to handle one alias in our current VM view. * * If we need to handle aliasing: * If the page only exists in the page cache and there are no user * space mappings, we can be lazy and remember that we may have dirty * kernel cache lines for later. Otherwise, we assume we have * aliasing mappings. * * Note that we disable the lazy flush for SMP configurations where * the cache maintenance operations are not automatically broadcasted. */ void flush_dcache_page(struct page *page) { struct address_space *mapping; /* * The zero page is never written to, so never has any dirty * cache lines, and therefore never needs to be flushed. */ if (page == ZERO_PAGE(0)) return; if (!cache_ops_need_broadcast() && cache_is_vipt_nonaliasing()) { if (test_bit(PG_dcache_clean, &page->flags)) clear_bit(PG_dcache_clean, &page->flags); return; } mapping = page_mapping_file(page); if (!cache_ops_need_broadcast() && mapping && !page_mapcount(page)) clear_bit(PG_dcache_clean, &page->flags); else { __flush_dcache_page(mapping, page); if (mapping && cache_is_vivt()) __flush_dcache_aliases(mapping, page); else if (mapping) __flush_icache_all(); set_bit(PG_dcache_clean, &page->flags); } } EXPORT_SYMBOL(flush_dcache_page);
flush_dcache_page関数は、CPUキャッシュの方式によって挙動が変わる。
エイリアス(異なる仮想アドレスから同じ物理アドレスを参照する)の問題があるVIPT aliasingやVIVTの場合は、ページフレームを扱う前後でキャッシュをフラッシュすることで回避している。
しかし、今回はnon-aliasingであるためflush_dcache_page関数はpage構造体のフラグ(PG_dcache_clean)を操作するだけである。
その後、バッファにDirtyフラグを立てるためにwrite_end関数を呼び出すが、本記事では解説を省略する。
cond_reschedマクロは、プリエンプトポイントを明示し必要に応じてプリエンプションさせる。
ファイルのオフセットを更新する
write処理が完了した後に、オフセットの更新やdirty pageのbalanceを実施する。
// 3790: if (unlikely(status == 0)) { /* * A short copy made ->write_end() reject the * thing entirely. Might be memory poisoning * halfway through, might be a race with munmap, * might be severe memory pressure. */ if (copied) bytes = copied; goto again; } pos += status; written += status; balance_dirty_pages_ratelimited(mapping); } while (iov_iter_count(i)); return written ? written : status;
おわりに
本記事では、ext2ファイルシステムのwrite_iter操作(generic_file_write_iter)を解説した。
次回の記事で、ファイルシステム固有のwrite_iter操作を解説したいと思う。
変更履歴
- 2021/2/23: 記事公開
- 2021/10/08: dirtyリストの繋げる処理する画像の更新
- 2022/09/04: カーネルバージョンを5.15に変更
参考
- Linuxにおける非同期IOの実装について #Linux - Qiita
- 非同期IOについて、それぞれの問題点やio_uringの解説
- hiboma/kernel/i_size_readと32bit.md at master · hiboma/hiboma · GitHub
i_size_read関数で32bitの処理が複雑になっている件について解説
- No wait AIO [LWN.net]
- 非同期IOでノンブロッキング処理の導入
- Linuxでのpage構造体群の配置 #Linux - Qiita
- Linuxのメモリモデル
- About cachetype on ARMv7
- ARMv7のcacheについて
- あるキャッシュメモリの話 | PPT
- CPUのキャッシュ方式について
- https://programmer.help/blogs/linux-memory-management-arm-memory-layout-and-mmu-configuration.html
- ARM Memory Layout
- HighMemory - Linuxカーネルメモ
- Linux のメモリ空間
- メモリ管理
- 筑波大学の講義資料。この資料では2020年のメモリ管理に関する資料